





ArkTS多线程的HarmonyOS 鸿蒙Next多线程系列(一):ArkTS多线能力入门
ArkTS多线程的HarmonyOS 鸿蒙Next多线程系列(一):ArkTS多线能力入门
- ArkTS多线程的多线程系列(二):基于Sendable共享对象实现跨线程通信及UI状态刷新
- ArkTS多线性的多线程系列(三):基于单例实现跨线程缓存
- ArkTS多线程的多线程系列(四):基于生产者-消费者实现多线程协同
- ArkTS多线程的多线程系列(五):通过子线程实现全局弹窗
HarmonyOS应用的UI操作必须在主线程执行(如修改UI控件,更新视图这些操作必须在UI线程中进行),如果主线程出现阻塞,那么UI界面就会出现明显的卡顿。因此为了解决此类问题,我们需要将一些耗时的操作例如加载网络数据、查询本地文件、数据等放到子线程中,以提升应用的响应速度和性能。
多线程能力介绍
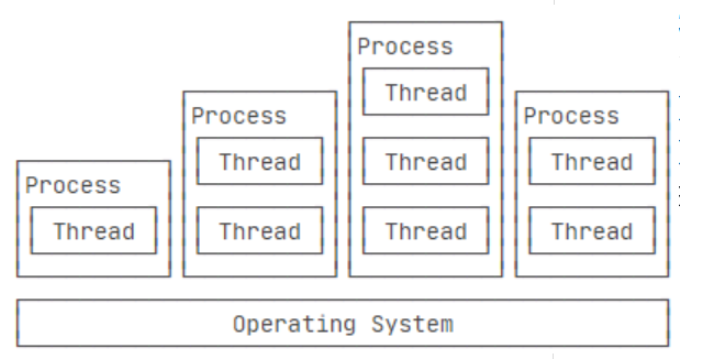
进程与线程
在单线程中执行的代码都是串行的,即按顺序执行,直到执行完成后,程序才会退出。当程序需要执行多个任务时,每个任务必须等待前一个任务执行完成后才能继续执行,这使得程序的性能非常低下。多线程技术通过使用多个线程来充分利用CPU资源,同时执行多个任务,从而提高程序执行的效率。每个线程都是相互独立的,并能够单独执行、暂停、继续和停止。进程(Process):是操作系统进行资源分配的最小单元。线程(Thread):是操作系统进行运算调度的最小单元,它被包含在进程之中,是进程中的实际运作单位。
多线程的使用场景
多线程的应用场景包括但不限于以下场景:
-
CPU密集型:数据处理、图像处理。当需要大量的数据处理时,可以使用多线程,以提高处理效率
-
I/O密集型:文件读写、网络请求。当需要发起大量的I/O请求时,可以使用多线程,以避免卡主线
-
后台任务:自动化作业处理,比如需要定期完成特定任务。
ArkTS的多线程解决方案
在HarmonyOS的ArkTS侧为多线程提供了两种方式:TaskPool和Worker,应用可以结合自身业务诉求,选择对应的实现方案。
TaskPool简介
任务池(TaskPool)作用是为应用程序提供一个多线程的运行环境,降低整体资源的消耗、提高系统的整体性能,且开发者无需关心线程实例的生命周期。TaskPool提供了多种不同的任务能力:
| 能力 | 任务构建 | 任务执行 | 场景描述 |
| 普通任务 | new taskpool.Task() | taskpool.execute() | 立即执行的短时任务,耗时不能超过3分钟。 |
| 延时任务 | new taskpool.Task() | taskpool.executeDelayed() | 为了不影响应用启动的性能,一些不影响启动的初始化类任务往往期望放在延时任务中执行,如拉取线上的配置信息等。 |
| 长时任务 | new taskpool.LongTask() | taskpool.execute() | 希望长时运行的任务一直保持执行,已为其他模块提供特定的服务,比如日志埋点,后台长链接保活等。 |
| 串行任务 | new taskpool.SequenceRunner(),new taskpool.Task() | SequenceRunner. execute() | 用于执行一组需要串行执行的任务 |
| 依赖任务 | task1.addDependency(task2), task1.removeDependency(task2) | taskpool.execute() | 任务之间存在先后依赖关系 |
| 任务的优先级设置 | 待支持 | 待支持 | 在应用运行时,期望可以给设置空闲时任务,当应用处于闲时(比如冷启动完成后停留在首页)做一些相应的预加载动作(如预加载其他页面),从而提升应用整体性能。 |
TaskPool注意事项
-
实现任务的函数需要使用装饰器@Concurrent标注,且仅支持在.ets文件中使用。
-
由于不同线程中上下文对象是不同的,因此TaskPool工作线程只能使用线程安全的库,例如UI相关的非线程安全库不能使用,具体请见多线程安全注意事项。
-
序列化传输的数据量大小限制为16MB。
推荐使用场景
TaskPool的工作线程会绑定系统的调度优先级,并且支持负载均衡(自动扩缩容)
-
需要设置优先级的任务。
-
大量或者调度点较分散的任务。
-
需要频繁取消的任务。
TaskPool线程池扩容策略
总体算法TaskPool需要的工作线程数由任务平均执行时间和当前任务数共同决定。任务池会根据过往的执行数据计算出一个预期线程数,但是各个任务的执行时间并不能准确衡量TaskPool当前的负载,因此需要通过任务数来反映。
扩容机制TaskWorker线程创建有一定耗时。为了优化启动阶段的性能和加快任务执行,TaskPool默认创建和预留了一个线程。结合JS的async/await机制和TaskPool的线程复用特性,当任务较少时,一个线程能够正常处理所有任务,此时并不一定会触发扩容机制。当首次执行且任务执行耗时较长的时候,上述算法的平均执行时间并不能立刻得出,因此有新的任务时,将会额外新建两个线程,避免线程池拥塞。当任务执行完成后,仍会采用上述算法。
正常流程下,每当开发者向任务池中抛任务时,都会触发一次扩容检测。扩容检测首先会判断当前的空闲线程数是否大于任务数,若大于,则说明线程池存在空闲线程,不需要扩容即可执行完新的任务。否则通过算法判断需要的线程数进而创建线程到指定数目。
缩容机制当任务耗时且较多时,TaskPool将会新建多个TaskWorker线程。但在空闲时仍保留这么多线程将会导致资源浪费和内存无法下降。因此TaskPool使用了定时器,定时检测TaskPool的负载,负载计算方式仍然采用上述算法。但是考虑到频繁创建和销毁带来的开销,缩容并不会立刻缩到计算出的数目,而是整体沿用了急涨缓停的思想,即立刻扩容到指定数目,但在缩容阶段采用阶梯式下降的方式。空闲时每个检测阶段会尝试释放2个线程(当前策略)。由于涉及到资源释放,需要确保不会因为错误的释放带来野指针等crash行为,缩容阶段仍会去检测当前空闲线程是否可以释放。仅有满足条件的线程才能够被释放。
Worker简介
Worker主要作用是为应用程序提供一个多线程的运行环境,可满足应用程序在执行过程中与主线程分离,在后台线程中运行一个脚本操作耗时操作,极大避免类似于计算密集型或高延迟的任务阻塞主线程的运行。
Worker注意事项
-
Worker的创建和销毁耗费性能,建议开发者合理管理已创建的Worker并重复使用。
-
Worker存在数量限制,支持最多同时存在64个Worker。当Worker数量或者内存超出限制时,会抛出相应错误。
推荐的使用场景
-
常驻后台的线程任务
TaskPool与Worker对比
本节将从实现特点和适用场景两个方面来进行TaskPool与Worker的比较。更详细内容可以参考指南TaskPool和Worker的对比
| 实现 | TaskPool | Worker |
| 内存模型 | 线程间隔离,内存不共享。 | 线程间隔离,内存不共享。 |
| 参数传递机制 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移、SharedArrayBuffer共享、sendable共享。 | 采用标准的结构化克隆算法(Structured Clone)进行序列化、反序列化,完成参数传递。支持ArrayBuffer转移和SharedArrayBuffer共享。 |
| 参数传递 | 直接传递,无需封装,默认进行transfer。 | 消息对象唯一参数,需要自己封装。 |
| 方法调用 | 直接将方法传入调用。 | 在Worker线程中进行消息解析并调用对应方法。 |
| 返回值 | 异步调用后默认返回。 | 主动发送消息,需在onmessage解析赋值。 |
| 生命周期 | TaskPool自行管理生命周期,无需关心任务负载高低。 | 开发者自行管理Worker的数量及生命周期。 |
| 任务池个数上限 | 自动管理,无需配置。 | 同个进程下,最多支持同时开启64个Worker线程,实际数量由进程内存决定。 |
| 任务执行时长上限 | 3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时),长时任务无执行时长上限。 | 无限制。 |
| 设置任务的优先级 | 支持配置任务优先级。 | 不支持。 |
| 执行任务的取消 | 支持取消已经发起的任务。 | 不支持。 |
| 线程复用 | 支持。 | 不支持。 |
| 任务延时执行 | 支持。 | 不支持。 |
| 设置任务依赖关系 | 支持。 | 不支持。 |
| 串行队列 | 支持。 | 不支持。 |
| 任务组 | 支持。 | 不支持。 |
多线程开发常见场景&解决方案
创建&停止线程
TaskPool线程的创建&停止
通过taskpool.Task或者taskpool.LongTask构建TaskPool线程池任务,构造方法如let task: taskpool.Task = new taskpool.Task(taskName, taskFun, args);。
-
taskName为任务名称,此任务名无法在子线程中获取,如果子线程需要使用任务名,则需要将任务名作为参数传递给子线程。
-
taskFun为要执行的逻辑函数,该函数必须使用@Concurrent装饰器装饰。
-
args为任务执行函数的入参。默认值为undefined。
import taskpool from ‘@ohos.taskpool’;
function add(num1: number, num2: number): number {
return num1 + num2;
}
async function ConcurrentFunc(): Promise<void> {
try {
let task: taskpool.Task = new taskpool.Task(add, 1, 2);
console.info("taskpool res is: " + await taskpool.execute(task));
} catch (e) {
console.error("taskpool execute error is: " + e);
}
}
struct Index {
build() {
Row() {
Column() {
Text(‘Do Something in Taskpool’)
.onClick(() => {
ConcurrentFunc();
})
}
}
}
}
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>TaskPool任务销毁:对于长时任务(LongTask),除了通过启动外,开发者还需要在任务完成后调用terminateTask方法终止此任务,系统不会主动回收此任务。
let longTask: taskpool.LongTask = new taskpool.LongTask(longTask, 1000); // 1000: sleep time
taskpool.execute(longTask).then((res: Object)=>{
taskpool.terminateTask(longTask);
});
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>Worker线程的创建&停止
通过new worker.ThreadWorker(‘entry/ets/workers/MyWorker.ets’)的方式加载Worker。HAP中的Worker加载,路径规则为:{moduleName}/ets/{relativePath}。
import worker from ‘@ohos.worker’;
const workerThreadHAP: worker.ThreadWorker = new worker.ThreadWorker(‘entry/ets/workers/worker.ets’);
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>HSP中的Worker加载,路径规则为:{moduleName}/ets/{relativePath}。
import worker from ‘@ohos.worker’;
const workerThreadHSP: worker.ThreadWorker = new worker.ThreadWorker(‘hsp/ets/workers/worker.ets’);
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>HAR中的Worker加载,路径规则为:@{moduleName}/ets/{relativePath}。
import worker from ‘@ohos.worker’;
const workerThreadHAR: worker.ThreadWorker = new worker.ThreadWorker(’@har/ets/workers/worker.ets’);
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>Worker线程销毁
Worker的生命周期需要开发者自行进行管理,也就是说创建出Worker线程后,开发者需要管理Worker线程实例,因此当不需要再使用该线程后,需要显示调用Worker的terminate()方法,将Worker线程实例销毁掉。
const workerInstance = new worker.ThreadWorker(“entry/ets/workers/worker.ets”);
workerInstance.terminate();
<button style="position: absolute; padding: 4px 8px 0px; cursor: pointer; top: 8px; right: 8px; font-size: 14px;">复制</button>线程间通信数据类型说明
此处只做简单说明,具体规格参考相关文档
Sendable类型共享数据类型
Sendable协议定义了ArkTS的可共享对象体系及其规格约束。符合Sendable协议的数据(以下简称 Sendable 数据)可以在ArkTS并发实例间传递。默认情况下,Sendable数据在ArkTS并发实例(主线程、TaskPool、Worker)间通过引用传递。同时,ArkTS也支持Sendable数据在ArkTS并发实例间的拷贝传。
Sendable对象可以支持的属性类型:
-
属性限制:包含基础类型(boolean, number,string,bigint,null,undefined)、其他共享对象、枚举、@arkts.collections下的容器。
-
方法限制:可以传递共享对象中的方法。
当前Sendable对象使用限制较多,如:
-
Sendable class不能使用除了@Sendable的其他装饰器
-
不能使用字面量初始化Sendable类型
-
非Sendable类型不可以as成Sendable类型
更多的规则可参考Sendable使用规则
Sendable对象的使用:
-
taskpool中使用Sendable对象构建Task时传递参数是,通过args参数将Sendable对象的引用传递给子线程new taskpool.Task(taskName, taskFun, args)。
-
worker中使用Sendable对象通过workerPort.postMessageWithSharedSendable()方法,将Sendable对象的引用传递给子线程。
普通数据类型
普通对象传输采用标准的结构化克隆算法(Structured Clone)进行序列化,此算法可以通过递归的方式拷贝传输对象,相较于其他序列化的算法,支持的对象类型更加丰富。
序列化支持的类型包括:除Symbol之外的基础类型、Date、String、RegExp、Array、Map、Set、Object(仅限简单对象,比如通过“{}”或者“new Object”创建,普通对象仅支持传递属性,不支持传递其原型及方法)、ArrayBuffer、TypedArray。
可转移对象
可转移对象(Transferable object)传输采用地址转移进行序列化,不需要内容拷贝,会将ArrayBuffer的所有权转移给接收该ArrayBuffer的线程,转移后该ArrayBuffer在发送它的线程中变为不可用,不允许再访问。
可共享对象
共享对象SharedArrayBuffer,拥有固定长度,可以存储任何类型的数据,包括数字、字符串等。
共享对象传输指SharedArrayBuffer支持在多线程之间传递,传递之后的SharedArrayBuffer对象和原始的SharedArrayBuffer对象可以指向同一块内存,进而达到内存共享的目的。
SharedArrayBuffer对象存储的数据在同时被修改时,需要通过原子操作保证其同步性,即下个操作开始之前务必需要等到上个操作已经结束。
Native绑定对象
当前支持序列化传输的Native绑定对象主要包含:Context、RemoteObject和PixelMap。
更多关于ArkTS多线程的HarmonyOS 鸿蒙Next多线程系列(一):ArkTS多线能力入门的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html



更多关于ArkTS多线程的HarmonyOS 鸿蒙Next多线程系列(一):ArkTS多线能力入门的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html



ArkTS在HarmonyOS鸿蒙Next中支持多线程编程,主要通过TaskPool和Worker两种方式实现。TaskPool为应用提供多线程运行环境,支持多种任务类型如普通、延时、长时和串行任务,提升系统性能。Worker用于在后台线程执行耗时操作,避免阻塞主线程。两者均有助于提升应用响应速度和整体性能。如果问题依旧没法解决请加我微信,我的微信是itying888。
更多关于ArkTS多线程的HarmonyOS 鸿蒙Next多线程系列(一):ArkTS多线能力入门的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html