




Golang Go语言中踩到 json 解析坑了,如何才能严格解析 json?
精准踩中了 json 解析包的两个坑导致了生产环境出错
假设有下面结构体定义
type Data struct {
A string `json:"a"`
B int `json:"b`
Obj struct {
AA string `json:"aa"`
BB int `json:"bb"`
} `json:"obj"`
}
使用json.Unmarshal() 解析下列几种 json
{"a":null, "b": null, "obj":null}
{"obj": null}
{"a": "a"}
{"a": "a","z":"z"}
{}
{"obj": {}}
问:解析哪个 json 会报错?
答:全都不报错都正确解析
都是不出事就注意不到的问题。尤其非指针类型字段,我下意识认为遇到 null 是会直接报错的,结果直接是当作不存在(undefined)来处理。。。
so ,go 下怎么才能简单地进行严格 json 解析?要求
- 不允许出现未知字段,出现则报错(这个似乎倒是可以用 json 包的 DisallowUnknownFields 简单做到)
- 非指针字段不允许传入 null ,否则报错(似乎 json 包没法简单做到)
Golang Go语言中踩到 json 解析坑了,如何才能严格解析 json?
更多关于Golang Go语言中踩到 json 解析坑了,如何才能严格解析 json?的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html


我看过结构体成员用指针判断是否空串的,不清楚是否满足你的要求
更多关于Golang Go语言中踩到 json 解析坑了,如何才能严格解析 json?的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

可能不太现实,因为通过定义成指针来满足第二点需求的话,意味着结构体全部字段都必须定义成指针。如果字段非常多(几十上上百个)一个个判断代码量和工作量非常大增减字段容易出纰漏(最终要上反射)。而且所有字段定义成指针的话,使用起来会相当难受


json.Unmarshal() 会把 null 解析成对应类型的空值,比如 int 的话就是 0 。validation 只能判断是不是 0 不能判断是不是 null ,派不上用场




我出两个小建议,但是可能都需要对全局代码进行查找和替换。不过改动量还算可控的。
1. 如果只是针对 json 格式和 struct 定义不完全匹配,可以用 jsoniter 库,通过这个配置玩一下:jsoniter.Config{DisallowUnknownFields: true}
2. 如果需要在 struct 上自定义 tag ,例如:required ,那可以提供一套自定义的 json 方法,里面先使用 github.com/go-playground/validator/v10 进行检查(支持的 tag 应该足够用了),再执行原生的 json 方法,方法签名保持不变
对于方案 2 ,全局的代码应该可以通过修改 import ,把所有的 json 包都替换成自行实现的 json 包,提供 marshal / unmarshal 方法就可以了



https://go.dev/play/p/8_2sAiXdrQ7
9L 的小 demo ,试了一下感觉应该挺好用的
type User struct {
Name string json:"name" validate:"required"
Age int64 json:"age" validate:"required"
}
testCase: {“name”: “john”, “age”: 10}
result: <nil>
testCase: {“name”: “john”, “age”: 10, “is_v2ex”: false}
result: main.User.ReadObject: found unknown field: is_v2ex, error found in #10 byte of …| “is_v2ex”: false}|…, bigger context …|{“name”: “john”, “age”: 10, “is_v2ex”: false}|…
testCase: {“name”: “john”}
result: Key: ‘User.Age’ Error:Field validation for ‘Age’ failed on the ‘required’ tag


"因为 json 默认把 null 解析为空值,所以解析 json 的时候并不会报错,商品价格会以 0 元被解析"
作为一个合格的程序员会告诉你,并不会,null 本来就是合格的 json 值格式你为何非要别人报错
当某个问题别人从没遇到过自己经常遇到的时候,好好思考下,会不会是自己的思维方式或使用方式不当

关于 validation 这件事,你们真的应该亲自试试,就会发现这根本不是 validation 能解决的问题。
null 会被解析为默认空值,如 int 字段传入 null 会被解析为 0 ,即便用 validator 这个包做 validation 检测也只能检测字段是不是 0 。但在实际业务中 int 值字段为 0 基本都是正常值,不应该被报错
你理解错 9L 的意思了,你提供的这段代码其实是有问题的。比如你尝试解析下 {"name": "john", "age": 0} 是会报错的(有的地区是有 0 岁这个概念的哦),单纯在解析后用 validator 是没法区分传入的到底是 0 岁还是 null 的
如果你是个合格的程序员并且经验丰富接触的语言也不只有一种的话,那么你会清楚一般来说语言解析遇到 null 的话,都会尽量将其解析为对应语言中的空指针/null/None 一类。比如 python 把 null 解析为 None, js 、php 、java (大部分 json 包)会把 null 解析为 null 。而对于 kotlin 这种明确区分了空值非空值的语言,将 null 解析为非空类型的字段会直接报错。
话题绕回来,对于 json 来说 null 存在是合理的,但是将 null 解析为非指针的时候不报错解析为默认空值是不合理的。请问你如何区分 {“a”:null} {“a”:0} ?而且落地到实际项目中,假设一个 api 接口所有字段都是禁止传 null 的,但是前端/外部接口就硬是因为 bug 之类的给你传了个 null ,请问你认为是直接报错拒绝请求比较好呢,还是直接解析成对应类型空值去处理业务从而引发严重事故好?
要改成指针的可不止匿名类,匿名类里的 AA 、BB ,外面的 A 和 B 也都得要改成指针哦。然后就出现了我 2L 说的问题,为了解决 null 判定这一个问题,整个 struct 全部字段都定义成指针,实在过于得不偿失了。
其实问题不在“已知字段会为 null”,而是 API 文档已经明确约定了些字段全都不能为 null ,但外部接口/前端就硬是给你传了 null (不要问为什么,后端永远不能相信前端传给你的数据是什么牛鬼蛇神,实际上这次出事就是因为约定了非 null 的字段外部接口给传了 null 。)
C++对象也是不可为 null 的,但是许多 C++的 JSON 库懂得把 null 对应到 std::optional 或者其他的 optional 实现。Golang 这个问题实际上反映了缺乏类似 std::optional 这样的表达 null 的工具。
“Go 不用指针就代表不能为 null”
“那你知不知道,golang 里面,struct 只有 0 值没有 null 值呢”
你们说的对啊,Go 里一个类型不是指针代表这个类型不能赋值 nil ,json 解析的时候遇到 null 意思就是要把 nil 赋值给非指针,直接报错不是再正常不过的想法吗?
“你也知道,你列举的这些语言,对象是可为 null 的”
这里面和 go 最相近的是 Go ,因为 kotlin 和 go 一样类型分可空/非可空(对应到 go 近似看成指针/非指针)。当尝试将 null 解析到非可空字段时,kotlin 是可以报错的
// Decode reads the body of an HTTP request looking for a JSON document. The
// body is decoded into the provided value.
//
// If the provided value is a struct then it is checked for validation tags.
func Decode(r *http.Request, val interface{}) error {
decoder := json.NewDecoder(r.Body)
decoder.DisallowUnknownFields()
if err := decoder.Decode(val); err != nil {
return err
}
return nil
}
type NewComment struct {
Body string json:"body" validate:"required"
ParentId string json:"parentId"
}
…
var nc comment.NewComment
if err := web.Decode(r, &nc); err != nil {
return fmt.Errorf(“unable to decode payload: %w”, err)
}
…
很久没有写 go 了,go 不至于连个 json 不能处理吧
你可能都没看懂我这贴的意思到底是什么。我只是举例,出的事故不是订单相关。
后端不应该信任前端/外部端口传入的数据,所以后端需要对传入的数据做最低限度的确认,如果不符合预期和要求就要报错。请问这点你同不同意?
这次问题就出在“对传入数据做最低限度的确认”上,API 接口约定不能传 null ,但是外部接口传了 null ,在 json 解析的时候自然而然会认为要给非指针赋值 nil ,json 包肯定会报错,但实际上它解析成空值不报错,而空值 0 是业务允许的,从而引发了生产事故
自然,传了 null 的确是前端/外部接口的锅,但除了生产事故加班 log 调查、数据查找、确立回复数据库数据都是后端/运维的工作。到时候如果来一句“虽然 xxx ,但后端连 null 都不检查的吗”就问你怎么应对。

我顶楼也说了,直到踩到坑之前我都一直以为 json 包替我完成了对 null 的校验啊。你要想,json 包做解析的时候吧 string 解析到 int 类型字段会报错,那么谁会想到把 null 解析到非指针字段就不会报错了呢?
> 都是不出事就注意不到的问题。尤其非指针类型字段,我下意识认为遇到 null 是会直接报错的,结果直接是当作不存在(undefined)来处理。。。
我看过比较好的方式是 前端来的 json 用一个 struct, 校验完转成 db 专用的另一个 struct, db 查询返回的又用另外一个新的 struct. 前端更新某个 field , 又用一个专属的 struct. 用 go 写 curd 后台,做得最多的就是各个 struct 之间转来转去。
<br>// Create adds a Comment to the database. It returns the created Comment with<br>// fields like ID and DateCreated populated.<br>func (c Core) Create(ctx context.Context, nc NewComment, now time.Time, usrId string, tutId string) (Comment, error) {<br> if err := validate.Check(nc); err != nil {<br> return Comment{}, fmt.Errorf("validating data: %w", err)<br> }<br> parentId := &dbschema.NullString{}<br> if nc.ParentId == "" {<br> parentId.Valid = false<br> } else {<br> parentId.Valid = true<br> parentId.String = nc.ParentId<br> }<br> dbCm := db.Comment{<br> ID: validate.GenerateID(),<br> CommenterId: usrId,<br> TutorialId: tutId,<br> ParentId: parentId,<br> Body: nc.Body,<br> DateCreated: now,<br> DateUpdated: now,<br> }<br> if err := c.store.Create(ctx, dbCm); err != nil {<br> return Comment{}, fmt.Errorf("create: %w", err)<br> }<br><br> return toComment(dbCm), nil<br>}<br><br>
web 到业务逻辑 然后再到 db 层,json tag 校验是必备的。sql.NullString sql.NullInt 都不是简单的 struct ,理论上不存在 go 后端不查 null 的,因为必须确认. 你们是不是用了什么 orm 一把梭了.
#33 “前端来的 json 用一个 struct, 校验完” 其实问题就出现在怎么校验这一步上啊。null 会被解析成对应字段类型的空值,也意味着根本没有手段去校验 json 传入的是不是 null 。问题就出现在这一步了。我顶楼给的那几个涉及到 null 的例子就是最好写照

拿 php python 这种动态脚本语言来类比 go,很让你怀疑你的基础水平
kotlin 还差不多
但是, 你说的 kotlin 报错并不代表所有语言都要按照你喜好的语言来走, 严格来说,你的需求就是 2 步: 1 解析 2 验证非法值
如果 kotlin 直接在 json 解析阶段做了校验,我认为没有问题, 但是因为它做了就 diss 别的语言就显得太幼稚了, 如果你要这样来的话,麻烦你先把 c 和 rust 先 diss 一遍,按我经验,一般流行的库在解析阶段也不会报错,除非加了数值校验
再举个例子,以后再出一款高级语言,在 json 解析的时候支持自动反序列化,数值严重,enum 验证,time 类型验证…那新语言的开发者是不是又继续来鄙视这些老前辈呢?
如果你非要区分 0 和 null,按楼上说的用指针才是正道,你用了错误的方法去处理问题还一直想不通,感觉有点钻牛角尖了
多说一句,除了 null 以外,如果某个字段没填,json unmarshal 到非指针字段给的也是零值,也是不好区分的。
可能的一种做法是你封装一层 json unmarshal ,先通过反射把结构里必填的字段获取个列表,然后把数据先 unmarshal 到 map ,做是否填写的校验。
通过之后再 unmarshal 到对应结构上。

我不知道是自己说明能力太差还是你没法理解,我举例 python 、php 、js 只是想说他们都会将 json 中的 null 解析成对应语言中的 None/null 。这点你能明白吗?然后在 Go 语言里,与 json 的 null 最接近的概念也就只有 nil 了,你同不同意?所以将 null 的解析为 nil → 而非指针类型无法赋值 nil 从而会引发解析错误难道不是非常自然的想法?为什么你会认为这是个校验的问题呢?
而且如果要较真的话,我们再来深入思考一个问题,什么才叫校验?你说 null 解析成 nil 赋值给非指针字段是校验问题,那么解析如下 json {“a”:“hello”}到 这个结构体 struct { A int} 是不是也应该归类为校验问题? 在这里 A 是 int 类型,但是传入了字符串,两者的类型不对的检测是不是也应该交给校验?按照你的说法,解析 { “a”: “hello”} 的结果就应该和{“a”: null} 一样都解析成 0 ,然后交给校验来处理是不是?
#31
1. 我还以为你是不想把事故说很细, 换了个类似讲法规避一下风险. 但话说回来, 如果连测试都不需要, 那么这个业务 SLA 估计也没啥要求, 这种问题就算遇上也就是个慢慢修的过程.
2. 如果"需要对传入的数据做最低限度的确认", 那么就应该用指针. 因为这句话的背后已经说明了有可能为 null.
3. 不是自己的锅别接, 别人再怎么说也改变不了这个不是后端的问题. 我不知道是不是只有我司这样, 数据处理时要不要检查 null 或是其他异常值永远都是白纸黑字写的清清楚楚的. 不同语言对于异常值的处理差别太大了, 有的在 parse 时报错, 有的要用的时候才报错, 有的像 go 是在内存申请后自动 0 值的, 有的是不初始化的. 不写清楚太容易出问题了.
你现在就是一定要用 int 去完成指针的功能, 那除了自己魔改或者你自己做点 optional 的类型, 确实没啥办法了. 还是要用合适的工具去做合适的事情.
你说的非常对,你说的这个情况其实就是我顶楼给的几个例子中之一
解析下面的 json 都会成功,解析结果就是所有没有填的字段全为空值
{“a”: “a”}
{}
{“obj”: {}}
支持 op ,go 的包括 json 这块在内的很多设计其实都很扯,错的离谱还扯什么大道至简,一边标榜自己新,一边又只敢跟传统语言对比,对其他新语言的优秀特性视而不见听而不闻,可以说是非常双标了
> 如果"需要对传入的数据做最低限度的确认", 那么就应该用指针. 因为这句话的背后已经说明了有可能为 null
你好,你这已经是我针对不同人提出的同一个问题的第三次回复了。定义成指针是没有可行性的做法。理由很简单,作为后端我必须不相信前端,所以我要考虑 DTO 的所有字段都有可能被前端瞎传入 null 的情况。
如果采用指针的话,这意味着我一切 struct 中每一个字段都必须定义成指针。这根本不现实对吧?整个项目 DTO 中所有字段全是指针用起来一定很酸爽对吧。再一个,实际项目中 API 并不是所有字段都禁 null ,个别字段是允许 null 的,所有一切字段都定义成指针的话,请问你能轻松分辨出这一堆指针类型的字段中,哪些是允许 null 哪些是禁止 null 的?更要命的是,使用字段值的时候到底哪个字段要加*,哪个字段要判 nil ?
> 如果连测试都不需要
不好意思,不是没有测试而是测试没有覆盖到。你如果认为所有项目只存在完全没测试和所有测试条件都覆盖到的两种极端的话那就太理想了
> 不是自己的锅别接, 别人再怎么说也改变不了这个不是后端的问题
不是的,锅的确不是自己的我也不会接,但是因此产生的生产事故和因为事故调查、恢复加的班是实打实(你不可能叫前端过来给你查后端 l 日志,抽取数据回复被破坏的生产环境)
离谱,你说 often 就 often
https://pkg.go.dev/encoding/json#Unmarshal
Because null is often used in JSON to mean “not present,” unmarshaling a JSON null into any other Go type has no effect on the value and produces no error.
先说答案: 我认为解析成 0 没问题, 错就错在你自己定义类型不对
go 本身提供了非常好的解决方案 *指针, 稍微有点基础的都知道灵活运用来判断空(默认)值与 nil 值的区别
比如接收参数的时候,如果预判参数可能超过范围或可能存在空,直接指针介入即可
或者读取数据库的时候,也可以用来判断
通过这种方式来区分 nil 与空值,我认为非常合理,不应该在解析阶段处理,如果在解析阶段处理,我才觉得会引起大麻烦:
我目前接手的一些第三方类库一些结构体参数就几十个,很多值不需要额外处理直接默认留空即可,如果按你的想法,那漏掉一个 kv 对不传输过来都会报错
另外 你如何看待 c 和 rust 对于这个的处理
op 说的有一定道理,但是可以尝试从另一个角度考虑。对于许多语言来说 {“a”: null} 和 {} 是等价的,类比到 Go, 不传这个字段就是 0 值是合理的。所以实际上缺少的是一个 “required” tag, 当有 required 时,要求不能是 null.
我能理解你在判断 nil 与空值的模糊感受,但仍然不会赞同你的想法,在我看来,语言框架基础方法就应该尽可能简洁低耦合,要实现的功能完全可以通过三方库而且性能还不低
比如 go-playground/validator
如果我要验证必须有值 加 required
如果我要求某项值小于 30 加 lte=30
如果我要求 enum 验证 加 oneof=xiaoming huahua
如果我要求字符串以 V2EX 开头 加 startswith=v2ex
如果各种方便的方法都糅杂在 go 自身,那画面简直不敢想象
是我迷糊了吗? 零值不是 创建 struct 的时候就有了吗??“The JSON null value unmarshals into an interface, map, pointer, or slice by setting that Go value to nil. Because null is often used in JSON to mean “not present,” unmarshaling a JSON null into any other Go type has no effect on the value and produces no error.” 自己读一读 doc 呗,unmarshaler 只是没有去改原先的零值而已。unmarshaler 要快,而不是提前做很多 validation.这些后续你可以慢慢搞。
可以在 Unmarshal 检查一下 json ,给 struct 加 tag ,然后自己写个 scaner 。老实说 golang 的 json 我也感觉不太好用,看似简单实则臃肿。
典型站着说话不腰疼。我写了个例子给你展示所有字段都为指针是什么地狱情况
https://gist.github.com/WonderfulSoap/18a14da135f659d5350f36bdbe439b6a
真的太优雅了,是吧。main2.go 用来模拟在其他包里调用 Data2 数据的情况。悄悄跟你说 Calculate() 里已经塞入了两个 bug 了哦? data.I 和 data.Obj1.I 是可 null 字段段,所以不能直接取值。那么问题来了,如此高的心智负担这么多指针倒来倒去,你怎么确保你每次取值都取得万无一失?
为了证明自己是对的 刻意写了个极端情况 真是辛苦你了
可是我发现你逻辑思维可能有些问题,具体表现在:
非要想靠语言自身 hold 所有情况
对别人提出的问题视而不见, 只想强行解释自己的想法
我觉得你反倒很令人费解,请问你真的有业务经验吗,我说的都是实实在在经手的项目中遇到的问题。实际复杂业务中,前端/外部接口根据需要传过来的 json 包含这么多字段不是很正常的?其中个别字段为可 null 难道不正常?我给你的这个 Data2 就是我目前一个项目的 DTO 定义(当然类型并非全都是 int ,数量规模差不多这种感觉)
作为后端的基本要求就是不信任外部输入,我就只能考虑以这些字段都可能被传入 null 。你说全定义成指针可以解决问题,那么我就定义成指针了,结果就是我给的例子中的样子为什么反倒说我极端。。。。而且你要知道一旦涉及到业务,也就不是例子里简简单单的取值相乘了,根据 nil 不 nil ,计算方法不同等等等等一大堆复杂计算,全都是要对这些指针倒腾来倒腾去的,所以我才说不现实
可以参考下 GRPC 的做法
https://zhuanlan.zhihu.com/p/46603988?utm_id=0
额外给你认为一定要区分的变量配置一个是否为 null 的 bool 的字段
文章里也给了一些讨论的原因 为什么这么设计 感觉跟 json 这块的设计还有些共通的地方吧
https://stackoverflow.com/questions/31801257/why-required-and-optional-is-removed-in-protocol-buffers-3
这有什么区别吗? struct 创建的时候就是默认零值,unmarshal 只是选择性宽容。你后续按自己业务需求去校验。一群人在喷一些什么东西。又不是所有场景都需要判断。
10 多年开发经验了 确实没遇到过你的问题
就以你上面说的 php 为例, 加入 php 做后端,计算前端传入{“a”: null}给你,你又能如何呢, 解析同样正常, 你仍然需要在业务层做数据校验,你要解析时报错,除非使用支持的第三方库
当我们需要判断一个值的时候当然可以 if a> 0 …
当我们需要判断 100 个值得时候, 正常人都会选择复用方法来实现, 你还要按照一个值的方法来使用还指责语言不够完善就不合理了,而且我上面也给你提到了好用的三方库,也忽视不见
要按这样说,c 语言官方连 json 支持几乎为 0 呢,那不是更应该吊起来打
“要改成指针的可不止匿名类,匿名类里的 AA 、BB ,外面的 A 和 B 也都得要改成指针哦。”
兄弟看来是没用过 proto3 ,这个缺省零值的设定习惯了还是挺好用的,首先大部分零值在业务上本身就对应无效值,或者可以通过取值范围设计对应为无效值,例如 string 如果按你的想法传 null 直接解析时报错,但你程序里往往还要检查非空,所以直接解析时多一步 null 检查就有点多余了,枚举类型的 0 值同理;对于极少数 0 值合法,且你要区分是没传还是传入了 0 值的情况,可以用指针,这种情况显然是非常少的。
这只能说是标准库的一种取舍,对你可能不方便,但是对大部分人可能是一种更可接受的行为。并且标准库文档是有明确说明这种行为的 // By convention, to approximate the behavior of [Unmarshal] itself, // Unmarshalers implement UnmarshalJSON([]byte("null")) as a no-op.
https://cs.opensource.google/go/go/+/master:src/encoding/json/decode.go;l=117-121;drc=dac9b9ddbd5160c5f4552410f5f8281bd5eed38c
对于 LZ 这种场景,比较好的方案是自己定义一个类型别名,然后给这个类型实现自己的 Unmarshal 接口,实现很简单。如果 LZ 的场景有很多的类型都要考虑 null 要报错,那我觉得可能是设计上有点问题了。<br>type Int int<br><br>func (i *Int) UnmarshalJSON(bs []byte) error {<br> if len(bs) == 0 || bytes.Equal(bs, []byte("null")) {<br> return fmt.Errorf("need a value")<br> }<br> val, err := strconv.ParseInt(string(bs), 10, 64)<br> if err != nil {<br> return err<br> }<br> *i = Int(val)<br> return nil<br>}<br><br>type Req struct {<br> ID Int `json:"id"`<br>}<br><br>var _ json.Unmarshaler = (*Int)(nil)<br><br>func TestNULLJSON(t *testing.T) {<br> var r Req<br> var args = []struct {<br> payload []byte<br> err bool<br> }{<br> {<br> []byte(`{"id": null}`),<br> true,<br> },<br> {<br> []byte(`{"id": 0}`),<br> false,<br> },<br> }<br> for idx, arg := range args {<br> if err := json.Unmarshal(arg.payload, &r); (err == nil) == arg.err {<br> t.Fatalf("%d: want err: %v, but got: %+v", idx, arg.err, err)<br> }<br> }<br>}<br><br>
你声明的是 Int 这种基本类型,只是一段 32 比特的数据,不能表示 Null
既然你这么声明了,那么你就应该处理好零值,或者你换一个可以表示 null 的类型
结构体的 size 是固定的,必须初始化对应的成员。
我说个对比你们就明白 op 的疑问了,.net 中的 System.Text.Json ,碰到这种情况会在反序列化 json 的时候抛出异常 “Cannot get the value of a token type ‘Null’ as a number.“
record JsonTest(int price);
JsonSerializer.Deserialize<JsonTest>(”{“price”:null}”);
==============
System.Text.Json.JsonException: 'The JSON value could not be converted to Test.JsonTest. Path: $.price | LineNumber: 0 | BytePositionInLine: 13.'
InvalidOperationException: Cannot get the value of a token type ‘Null’ as a number.
如果必须前端传回 price ,且值可以为 int 或 null 的话就定义成这样,未传入 price 会抛出异常 'JSON deserialization for type ‘Test.JsonTest’ was missing required properties, including the following: price’
record JsonTest
{
[JsonPropertyName(“price”)]
public required int? Price { get; set; }
}
v2 上大伙都这么学院派吗,对于业务来说这确实是个很令人难受的问题啊。类比 Java 的话,会有人在定义 vo 的时候用 int 而不用 Integer ,然后去判断 int 的值 != 0 吗?正常情况下肯定是判断是否为 null 啊。当然用指针不是不可以,额外多出的工作量不还是得自己来吗?
OP 搞错了。并不是将 null 解释为空值,而是你类型不对,它就会解析成默认值。因为这个 Data 实例的每个值都肯定得有值。
你就算
{“a”:123, “b”: “abc”, “obj”:999}
它照样会解析成
{“a”:"", “b”: 0, “obj”:…}
go 的 json 反序列化 null 值或者空值不报错或者赋默认值这是一个特性,既然你用了别人的库就要接受相关特性,因为这是一个特性所以你的需求需要自行实现校验。
现在来看解决方案有两种,第一种通过指针,第二种自定义 type + 实现 UnmarshalJSON 。
{A: B:0 Obj:{AA: BB:0}}
我亲测的没报错啊:
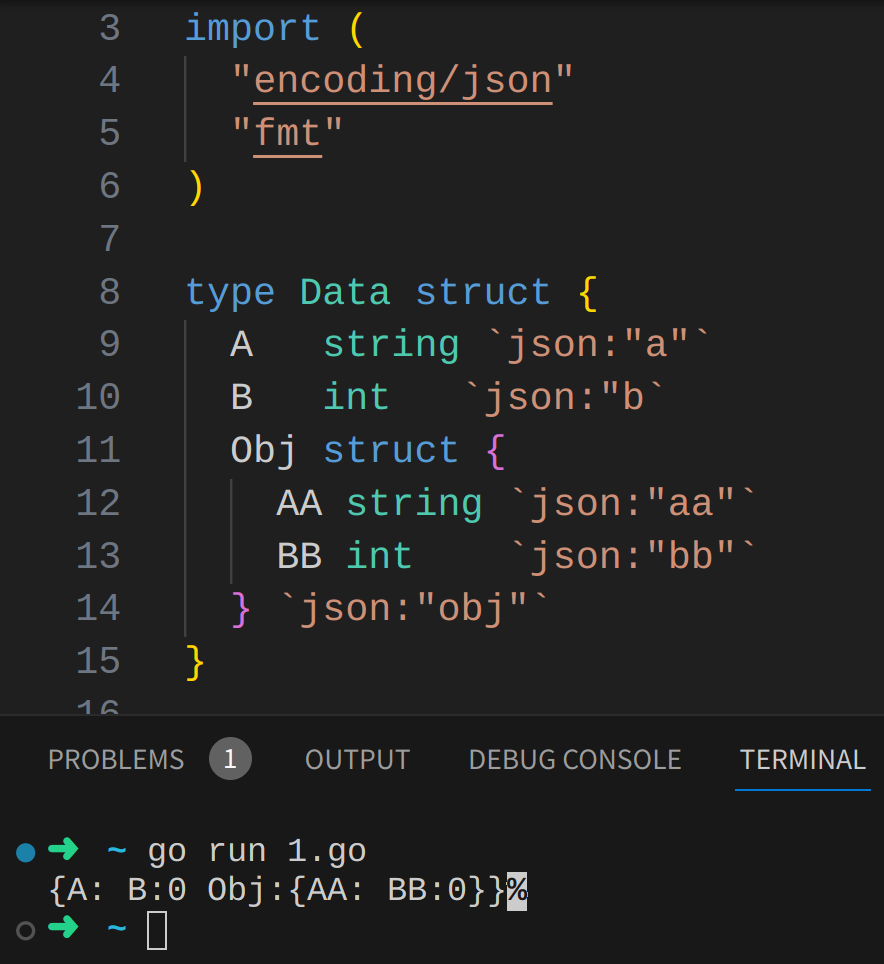<br>package main<br><br>import (<br> "encoding/json"<br> "fmt"<br>)<br><br>type Data struct {<br> A string `json:"a"`<br> B int `json:"b`<br> Obj struct {<br> AA string `json:"aa"`<br> BB int `json:"bb"`<br> } `json:"obj"`<br>}<br><br>func main() {<br> var json_str = `{"a":123, "b": "abc", "obj":999}`<br> var test Data<br> json.Unmarshal([]byte(json_str), &test)<br> fmt.Printf("%+v", test)<br>}<br>
看到第一个 json 第一反应是这个不应该是非法的吗,null 都没有""包裹,然后查了下才发现默认 json 是支持 null 的,https://www.json.org/json-zh.html ,因为 json 就是 javascript 来的。。。
不过我还真没遇到这种问题,写 go 习惯了,都是用下面这种代码检查默认值,可能我用 json 不多,不嫌麻烦吧,主要是有的时候可以免去检查 err 了
var obj = &Obj{ val: -1}
_ = json.Unmarshal(data, obj)
if obj.val == -1 {
panic(“haha”)
}
null 还是很重要的基础类型之一,你看别的语言解析,一般都会保留一个变体字段结构,来识别原始 JSON 字段的具体类型。
如果强制映射到结构体,那么 null 就会消失,变成 int 或者 string 默认值,也是能理解的。
指针 nil 是个解决方案,也没有更好的办法了。
传输协议用的 protobuf go 后端同样遇到这样的问题 解析出来 int 的值是 0 无法确认客户端传的是 null 还是就是业务上的 0 ,所以全改成指针了,然后全局替换判断,取值的时候也用公共方法统一替换。这样客户端不用改,就后端加了一堆工作量,md 好想写回 java ,加个注解就完事了🤔
其实问题在于 JSON 并没有指针的概念,null 是一个合法的值,而 Golang 中在进行反序列化时,没有与 null 相对于的值用于表示这个状态,同样的,也没有对应于 undefined 状态。
一种凑合的解决方案呢,就是业务中不使用默认值作为合法状态,例如 0 元的价格 price ,当值为-1 时代表 0 元,而 0 代表未传值。类似的,空字符串等都不作为有效的数据输入,用其他值作为默认值的替代。
但是多数场景下,op 的问题可能都不大,0/""这些默认值都不具有实际意义。
我觉得其实和团队风格有关。我以前的公司 toC 高并发,比较抠性能不抠细节。现在的公司 toB ,反正业务维护得下去就行性能无所谓。然后我才接触到,json 里还区分 not assign 和 null 有区别的。谷歌说的 often 其实在大部分情况是成立的,比如 10 个字段 9 个不区分这样。 作为一种语言,把自己的理念强行安排给所有人这事 Go 干的不少。
说回现在我们是怎么解决的,就是多包一个类似 Optional 的实现,并且实现对应的自己的 validator 。完全可以实现楼主所说的功能。在泛型没出来之前是每个基础类型包一下,幸好现在出来了,但是历史代码还是有点不雅。
在Go语言中,处理JSON解析时确实可能会遇到一些“坑”,尤其是当JSON数据不完全符合预期格式时。为了严格解析JSON,你可以采取以下几个措施:
-
定义明确的结构体:使用结构体来映射JSON数据,确保每个字段都有明确的类型。这样,在解析时,如果JSON数据中的字段名或类型不匹配,解析将失败并返回错误。
-
使用
json.Decoder:相较于json.Unmarshal,json.Decoder提供了更细粒度的控制,允许你逐步解析JSON数据,并在遇到错误时立即停止处理。 -
启用严格解码模式:虽然Go标准库的
encoding/json包没有直接的“严格模式”开关,但你可以通过自定义的Unmarshal方法来实现更严格的解析逻辑,比如检查额外的字段或确保所有必需字段都存在。 -
错误处理:总是检查
json.Unmarshal或json.Decoder返回的错误,并根据错误类型进行适当处理。常见的错误包括类型不匹配、字段缺失等。 -
单元测试:编写全面的单元测试来覆盖各种可能的JSON输入情况,确保你的解析逻辑能够正确处理各种异常情况。
-
使用第三方库:如果标准库的
encoding/json包不能满足你的需求,可以考虑使用如jsoniter等第三方JSON库,它们可能提供了更灵活或更严格的解析选项。
通过以上措施,你可以大大提高JSON解析的严格性和可靠性。