




Golang Go语言实现的高性能分布式IM:GlideIM
GlideIM 是一款真正的完全开源, Golang 实现的高性能分布式 IM 服务, 有完整的安卓 APP 示例, JAVA SDK, Web 端示例, 持续更新迭代中.
GlideIM 支持单实例, 分布式部署. 支持 WebSocket, TCP 两种连接协议, 内置 JSON, ProtoBuff 两种消息交换协议, 并支持添加其他协议, 消息加密等. 还实现了智能心跳保活机制, 死链接检测, 消息送达机制等功能.
这个项目自 2020 年中旬开始, 三端均开发由我一个人独自不间断开发直到现在, 也是我第一个耗费最多精力去开发及学习的项目. 由于我工作较多空闲时间, 基本上都在开发本项目, 边学习边开发, 查阅了大量资料, 经过大量的思考, 目标就是一个高性能分布式 IM. 第一版微服务架构在开发三个月的时候基本已经完成了, 后面则是做了微服务架构调整, 和进一步优化 IM 服务细节, 截至目前(2022 年 3 月 3 日), 距离我预期的第二版, 只剩下一些收尾工作.
本项目将持续更新迭代.
- 服务端源码: GlideIM - GitHub
- Android App 下载: Android - GitHub
- Web 端: GlideIM
一. 功能
1.1 用户侧功能
- 无感掉线重连, 消息同步
- 登录注册及保持登录
- 一对一聊天, 群聊
- 消息漫游, 历史记录
- 离线消息
- 多设备登录, 同设备互挤下线
- 多种类型的消息 (图片, 语音等, 由客户端定义)
- 消息撤回
- 联系人管理, 群管理
1.2 开发侧功能
- 支持 WebSocket, TCP, 自定义连接协议
- 支持 JSON 或 Protobuff 或自定义数据交换协议
- 支持分布式部署, 水平扩展
- 心跳保活, 超时断开, 清理死链接
- 消息缓冲, 异步处理, 弱网优化
- 消息送达机制, 消息重发, ACK
- 消息去重, 顺序保障, 读扩散
二. 项目架构
为了提高可用性和整体的稳定性, 单机性能的限制, 必须使用分布式架构, 微服务的模式方便了维护. 本项目对 IM 业务部分拆分了六大核心主模块(服务), 每个服务可以水平任意数量扩展, 整个系统可以具有一定的伸缩性, 每个模块根据其业务特性划分, 逻辑和接口分离, 在保证接口简洁性的同时也有足够的扩展性.
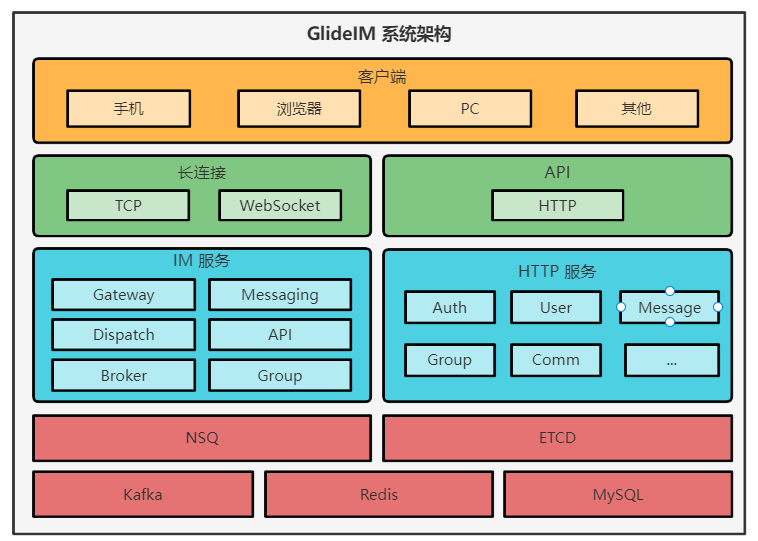
2.1 聊天服务划分
Gateway
Gateway 模块为管理用户连接的聊天服务网关, 所有用户消息上下行都由这个模块处理. Gateway 管理用户连接, 消息的接收解析, 消息下发, 判断连接是否存活, 标识用户连接, 断开用户连接.
Gateway 依赖 Messaging 服务, 接收到客户端消息将交由 Messaging 处理, Gateway 提供指定 uid 登录, 登出, 下发消息三个接口.
Messaging
Messaging 负责不同类型消息的路由, 例如群消息, API 消息, 也处理部分类型的消息, 例如 ACK 消息, 单聊消息, 心跳消息. 根据消息类型分别转发给 Dispatch (用户消息), API (API 消息), Group(群消息).
Messaging 依赖 API, GroupMessaging, Dispatch, 提供一个消息路由接口.
Group
(GroupMessaging), 群聊服务, 主要负责多人聊天消息的下发, 保存, 群消息确认, 成员管理. 用户上线后同步联系人时初始化群聊列表, 根据群聊所在服务通进入群聊天.
Group 服务依赖 Dispatch 服务, 提供群更新, 成员更新, 发送消息到指定群三个接口.
API
目前暂时作为长连接的登录鉴权, HTTP API 接口都可以通过长连接消息访问, 这个可以根据具体情况灵活配置, 只需配置相关路由即可.
API 依赖 Dispatch, Group 服务. 提供一个处理 API 类型消息的接口.
Dispatch
消息路由服务, 用于消息路由到用户所在网关, 在用户登录时通知 Dispatch 更新缓存用户对应的网关, 缓存信息通过一致性哈希保存在固定的一个服务上, 消息下发时查询缓存, 根据查询到的网关信息放入到 NSQ 队列, 每 Gateway 订阅自己的消息. 这里的消息不一定是用户消息, 也可以是通知网关更新用户状态的控制消息, 例如登录登出, 由于使用消息队列进行通信, 所以叫做消息, 其实是调用 Gateway 的接口.
Dispatch 不直接依赖任何服务, 消息通过 NSQ 发送到 Gateway, 提供更新路由和下发消息两个接口.
Broker
群聊与用户网关一样是属于带状态服务, 消息需要准确快速路由到群所在路径, Broker 和 Dispatch 功能大致相似.
NSQ
NSQ 是 Golang 实现的消息队列, 所有消息都通过 NSQ 路由. 相比其他 MQ 选择 NSQ 的理由: 去中心分布式(生产消费直连), 低延迟, 不需要顺序, 高性能, 简单二进制协议.
在每一台生产者上都部署一个 nsqd.
2.2 HTTP API 服务划分
- 认证: 用户鉴权, 登录注册等
- 用户: 用户信息管理
- 消息: 消息同步, 拉取等接口, 消息 ID
- 群管理: 群增删改查
- 其他
以上划分只是在项目中的模块划分, 并未独立成服务, 但拆分这些是轻而易举的事情, 上面这些接口既可以通过 HTTP 服务访问, 也可使用长连接访问, 长连接 与 HTTP 访问的差异在于: 1. 长连接访问需要添加 公共请求体, 2. 公共响应体定义不同.
2.3 消息路由
网关消息路由
在分布式部署环境下, 网关可能部署任意个实例, 用户可能连接到其中任意一个实例中, 当需要给某一个用户发送消息, 或者断开某个用户的连接时, 我们需要找到这个用户所在的网关, 这就需要记录所有在线用户所在网关. 可能快想到的是使用 Redis, 或者 Redis 加二级缓存, 但 IM 系统消息吞吐量非常大, 而且存在扩散等其他原因, Redis 很容易成为性能瓶颈.
GlideIM 使用一致性哈希算法, 将每个用户连接的网关信息按照 UID 分布在不同的 Dispatch 服务上, 从而达到分散缓存, 负载均衡, 及提高可用性的目的.
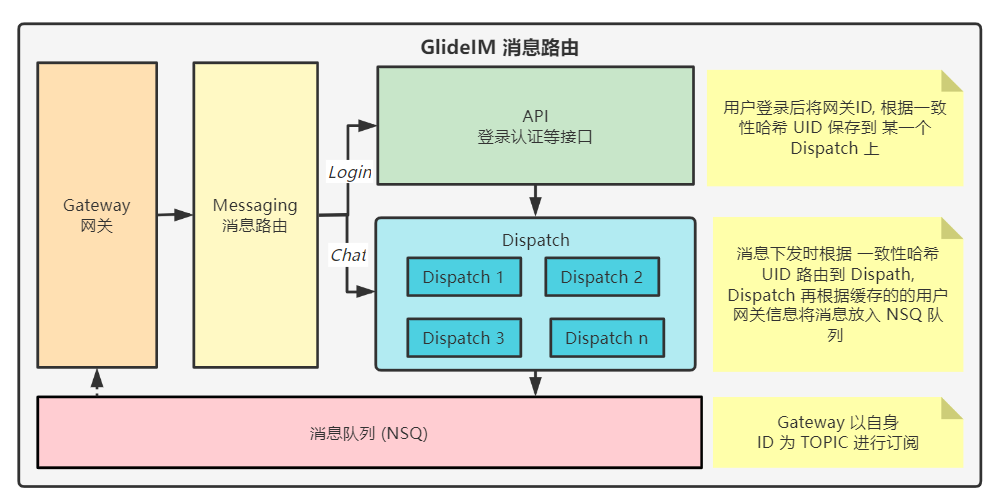
如上图所示, Dispatch 在整个环节中承当了消息分发的角色. 当某一个 Dispatch 服务宕机后, 该服务中所有缓存的网关信息都将丢失, 根据一致性哈希算法, 原来的请求都转向了下一个 Dispatch, 显然这个服务上是没有已宕机的那个服务缓存的信息的, 我们可以在用户登录后将登录信息缓存在 Redis 中 (查询登录设备列表等其他场景共用), Dispatch 内存中没查到再去 Redis 查找, 查找一次后缓存在内存中即可.新上线的用户则不影响, 只影响在线期间网关信息保存的 Dispatch 服务宕机的用户.
群消息的路由
群和用户一样 Group 服务也需要一样的路由, 不同群可能分布在不同的服务上, 但群并不会随意切换所在服务, 一般只有群所在的服务异常的时候重新加载群信息才可能重新分配, Broker 读多写少, 因此只需要在所有 Broker 中都缓存所有群所在服务即可, 群消息可以通过任意一台 Broker 转发, 当 Group 服务掉线和加载群时通知所有 Broker 更新即可.
2.4 设计准则
在本项目中, 我一直在探索和追求项目整洁性与复杂系统架构之间矛盾的解决方案, 但由于我没有任何相关经验, 在项目中可能出现一些非主流的风格或错误冗余的设计, 若你对此有任何疑惑或指教, 请在 issues 中自由地发表你的想法.
在面对一个庞大复杂的问题, 将问题拆分并抽象成对象, 划分为一个个小问题往往方便解决, OOP 在这方面一直是优势, 本项目使用了较多的 OOP 思想.
使用接口
对一些可能需要扩展的关键点, GlideIM 使用接口的方式实现的, 例如 Dao (数据访问对象)层实现均为接口, 出于时间原因(还有我本人对数据库方面知识匮乏), 项目中对数据库方面均是简单实现, 并未考虑例如性能等优化, 但接口不影响后期对这方面升级和替换.
按业务分包
包的划分方式一般有两种, 按层分包和按业务分包. 按层分包就是相同类型的模块放在同一个包, 例如将所有的 API 请求处理模块放一层, 将请求和响应的实体对象放在同一个包, 这这方法给模块的管理增加了不便, 我们更改一个接口需要在几个不同的包中修改代码, 这样分包一个包里的不同代码没有任何关联, 完全是类似于图书馆管理员根据书的出版社进行分类一样.
而按功能分包则不会出现更新一个功能, 修改不同包的代码的情况, 一个功能相关的代码都在相同包内. GlideIM 每个包尽量都遵循单一职责原则, 多个包之间尽量降低耦合度.
模块接口依赖
项目包的划分基本和微服务的模块划分保持一致, 刚开始启动的本项目时就按照了按功能划分模块的方法, 并且每个模块只暴露提供给其他模块的接口, 模块之间的调用只通过特定的接口, 这样设计即方便维护也方便其他人查看代码, 不会使得模块之间的调用凌乱, 而且也为后期微服务化的提供了极大便利.
例如 Gateway 模块的接口
// 提供给其他模块的接口
type Interface interface {
ClientSignIn(tempId int64, uid int64, device int64)
ClientLogout(uid int64, device int64)
EnqueueMessage(uid int64, device int64, message *message.Message)
}
// Gateway 依赖的接口
type MessageHandleFunc func(from int64, device int64, message *message.Message)
其他模块只需要知道 Gateway 模块提供客户端的登录登出和将消息加入到指定 ID 的客户端的队列即可, 其他模块不必知道 Gateway 的具体实现, 我们可以轻而易举的将这个模块替换为一个微服务服务.
2.5 微服务
GlideIM 使用 RPCX 作为微服务的基础, 开箱即用的微服务方案让我选择了它, RPCX 功能丰富, 性能优越, 集成了服务发现, 多种路由方案, 以及失败模式, 服务发现使用 ETCD.
服务间通讯均使用 Protobuff + RPC 方式, 在性能上这是最好的选择组合.
2.6 项目介绍
项目目录
一下目录结构省略了部分不重要的目录
├─cmd // 入口(从这里开始运行)
│ ├─performance_test // 性能测试代码入口
│ ├─run // 项目程序入口
│ │ ├─api_http // API 接口的 HTTP 服务, 提供给客户端访问
│ │ ├─api_rpc // API 接口的 RPC 服务, 提供给其他服务使用
│ │ ├─broker // 群路由服务
│ │ ├─dispatch // 网关路由服务
│ │ ├─getaway // 网关服务
│ │ ├─group // 群服务
│ │ ├─messaging // IM 消息路由服务
│ │ └─singleton // 单实例运行 (这里同时启动 IM 和 HTTP API 接口)
│ └─script // 部署脚本
│ ├─etcd // 启动 etcd 脚本
│ ├─glide_im // 项目部署脚本
│ └─nsq // nsq 部署脚本
├─config // 配置入口
├─doc // 项目文档
├─im // IM 核心逻辑入口
│ ├─api ////////////// API 接口
│ │ ├─apidep // API 外部依赖
│ │ ├─auth // 登录认证
│ │ ├─comm // 公共
│ │ ├─groups // 群管理
│ │ ├─http_srv // api http 服务启动逻辑
│ │ ├─msg // 消息
│ │ ├─router // 通过长连接访问接口的路由抽象
│ │ └─user // 用户相关
│ ├─client ///////////// 用户连接管理相关
│ ├─conn // 长连接基础抽象
│ ├─dao // 数据访问层, 数据库相关
│ ├─group // 群聊, 及群聊消息
│ ├─message // IM 消息定义
│ ├─messaging // IM 消息路由
│ └─statistics // 数据统计, 测试用
├─pkg ///////////// 包, 公共依赖管理
│ ├─db // 数据库
│ ├─hash // hash 算法实现
│ ├─logger // 日志打印
│ ├─lru // lru 缓存实现
│ ├─mq_nsq // nsq 封装
│ ├─rpc // rpc 封装, 基于 rpcx
│ └─timingwheel // 定时器, 时间轮算法实现
├─protobuf //////////// protobuf 消息定义
│ ├─gen // 编译好的文件
│ ├─im // im 消息定义
│ └─rpc // rpc 通讯消息定义
├─service /////////// 微服务
│ ├─api_service // api 微服务实现
│ ├─broker // 群路由 broker 服务
│ ├─dispatch // 网关消息路由服务
│ ├─gateway // 网关服务实现
│ ├─group_messaging // 群服务
│ ├─messaging_service // im 消息路由服务
├─sql // 数据库表结构 SQL
- 项目查看指南
IM 核心逻辑在根目录下 im 中, 除了微服务相关, IM 主要业务逻辑实现均在这个目录下, im 下包的划分大致可以看做是后面微服务的划分, im/conn 包中是长连接服务器启动和连接对象接口的逻辑, 新的连接将交由 im/client 包中管理, 这个包大致是管理连接, 读写解析消息的, 收到链接中的消息将交由 im/messaging 包处理, 这个包工具消息类型交给不同的模块, 例如: 认证消息给 api 模块处理, 群消息分发给 group, 单聊消息则 im/client 下发. im 下涉及业务逻辑的包下基本都有一个 interface.go 文件, 这个文件定义了这个包的依赖以及向外部提供的接口.
微服务相关的代码都在根目录 service 包下面, IM 核心业务相关的服务逻辑都在 im 下, 服务只是对其接口使用 rpc 服务的方式进行实现, 并在 im 包中对应接口的默认实现进行替换, 例如 messaging_service 服务(消息路由)则是将 im/messaging 包下的 Interface 接口的实现替换为 messaging_service 的 Server, 而 messaging 依赖的其他包则是对应服务下的 Client, 查阅每个服务包下的 run.go 即可找到服务启动代码, 其中包含了其依赖的和实现设置.
对于将核心逻辑和微服务剥离的这种模式是因为一开始并将微服务的划分定型(也经过了几次较大的改动), 或者为了方便将 IM 部分核心逻辑先实现和理清, 所以将两者放在两个不同的地方, 但在我实践的过程中, 对于服务的改动和 im 下核心逻辑(模块接口改动除外)的改动并不会互相牵连, 这点给我很大的便利, 我还有一定的自由度划分添加服务, 例如在 group 服务中间加一个 broker, 或者可以针对特定 im 中某个模块的接口中的一个方法进行特殊处理.
但是上面所说的便利仅仅是因为我当时对微服务不太熟悉, 项目开发过程改动较大, 分开改动的时候稍微方便一些. 这样做代价就是, 两者分开不利于代码查看, 这其实是一种分层, im 下定义接口及默认实现, 上层service定义接口的实现, 但这些接口之间的依赖关系, 还是要去 im 中寻找, 后面可能会考虑将这两个包合并在一起.
项目主要依赖
- BurntSushi/toml: 这是一款优秀的配置文件格式, 个人比较喜欢
- gin: 优秀的 HTTP Web 框架
- protobuff: Google 出品二进制数据传输协议
- gorilla/websocket: Golang 中最多 star 的 WebSocket 库
- nsq: 简单, 高性能, 分布式 MQ
- rpcx: 高性能, 功能丰富的微服务框架
- gorm: ORM
- go-redis/redis: Redis 客户端
- ants: 协程池
构建和运行
根目录下 cmd/run 下的包为程序入口, 包名表示其服务 /模式, 例如 api_http 包为以 HTTP 服务启动 API 的接口(提供给客户端 HTTP 方式调用), api_rpc 为启动 API RPC 服务(提供给其他服务调用), 为了快速调试, 这里还有一个单实例模式 singleton, 这个入口会同时启动 IM 长连接服务和 HTTP API 服务, 方便调试 im 核心逻辑, 或者调试客户端用.
环境依赖
-
单实例
- redis
- mysql
-
微服务
- nsq
- etcd
- 包含单实例的所有依赖
配置文件
- 单实例模式在
singleton包中config.toml修改相关配置 - 微服务模式需要将
service/example_config.toml文件复制到对于服务入口下, 并根据环境修改相关配置
如果依赖或者其他原因无法在 IDE 中运行代码, 可以在 下载已经编译好的
singleton 模式的可执行文件.
2.7 现存问题
协议相关
- 客户端协议选择
目前为了方便客户端使用 json 进行通信, 也是因为浏览器对二进制协议的支持不友好, 但后端对二者都有实现, 协议动态选择并没有实现, 或者区分 websocket 和 tcp 网关, 将二者区分, 浏览器的与移动端环境有差异, 但未做处理.
- Protobuf 和 Json 的兼容
微服务使用 protobuf 协议, 而客户端消息可能以 json 协议, 部分使用同一个由 protoc 编译生成的 struct 在兼容上存在一些问题, 暂未处理.
- 消息解析性能
使用 go 中的 json.Marshal 性能极差, 在整个消息流转过程中占用了大量时间, 暂未优化, 目前有多种第三方方案可以选择.
- 协议版本
消息协议可能会升级, 新老客户端使用不同协议版本兼容上为做处理.
数据库相关
- 消息 ID 生成
项目中目前使用 Redis Incr 生成递增 ID, 存在性能问题, 后面可以考虑使用 Leaf 等方案.
- 数据库, 表, 查询优化
未对这方面做任何优化, dao 层均只是简单实现了 CRUD 功能.
微服务相关
- 配置管理
目前启动服务是通过本地配置文件加载配置启动, 部署管理起来不太方便, 后面考虑使用配置中心.
- 包结构
目前微服务和 IM 逻辑是分层设计, 不方便维护和查看, 后面需要调整.
群聊的相关
- 消息风暴
群消息存在扩散问题, 尤其是大群一个成员发消息扩散几千上万次, 群数量稍微多一点或者消息稍微频繁一点, 消息数量非常容易失控. 在微服务模式下需要对系统网关的用户消息进行合并打包成一条消息.
- 群聊服务故障
群聊属于带状态服务, 当群所在服务宕机后如何不影响群消息的分发, 这点暂未处理, 对于恢复可以新增一个群聊服务监控服务, 监控到某一个群聊服务掉线立马恢复, 但这仅是故障恢复而不是对故障转移.
三. 设计细节
由于 GlideIM 的设计细节较多, 限于时间和篇幅, 这里只列举了几个较为重要的环节来做简单的说明, 详细情况或其他未说明的地方可以查看源码或加入讨论群一起讨论.
3.1 消息类型
IM 消息类型指的是聊天协议消息类型, 注意区别聊天内容的消息类型, IM 消息类型关联前后端双方的业务逻辑, 聊天消息类型只需要在前端处理.
-
IM 消息类型
- 聊天消息: 重发, 重试, 撤回, 群聊, 单聊
- ACK 消息: 服务器确认收到, 接受者确认通知, 接受者确认送达
- 心跳消息: 客户端心跳, 服务端心跳
- API 消息: 令牌认证, 退出等
- 通知消息: 新联系人, kickout, 多端登录等
-
聊天内容消息类型
- 图片
- 文本
消息类型由客户端定义及处理, 二进制消息例如语音, 图片则上传到服务器再发送 URL. 例如红包这种互动型消息, 一样可以使用这种方法.
客户端之间定义约定消息类型即方便了后期添加消息类型, 也方便了后端维护, 后端并不需要知道消息内容的类型.
3.2 送达机制
虽说 TCP 是可靠传输, 但在消息传递过程并不是万无一失的, 例如, 接受者在线但网络不好, 客户端在重连, 则消息可能不能及时送达接受者, 设计一个送达机制提高送达率是必要的. GlideIM 采用了单条消息两次确认(服务端和接收者)的送达机制.
A 发送一条消息给 B, 如果 B 在线, 服务端则回复 A 一条服务端确认收到消息告诉 A 服务端已收到, 已经入库保存了, 然后服务端发送给 B, B 收到则发送一条确认收到消息给服务端, 服务端收到后再发送一条确认送达消息给 A, 若 B 不在线则直接发送给 A 确认送达, A 此时就知道这条消息一定被 B 收到了, 在此过程中 A 如果没有收到 B 确认收到则多次重试.
在客户端做重发避免了服务端逻辑复杂化, 而客户端做则大大简化了逻辑. 有了这个送达机制, 不管是消息丢了还是网络环境不好的时候, 都能提高送达率和消息及时率, 再者若我们使用 UDP, 有了这个机制也可以确保消息的送达率.
GlideIM 消息 ACK 机制几种消息丢失情况下的时序图如下:
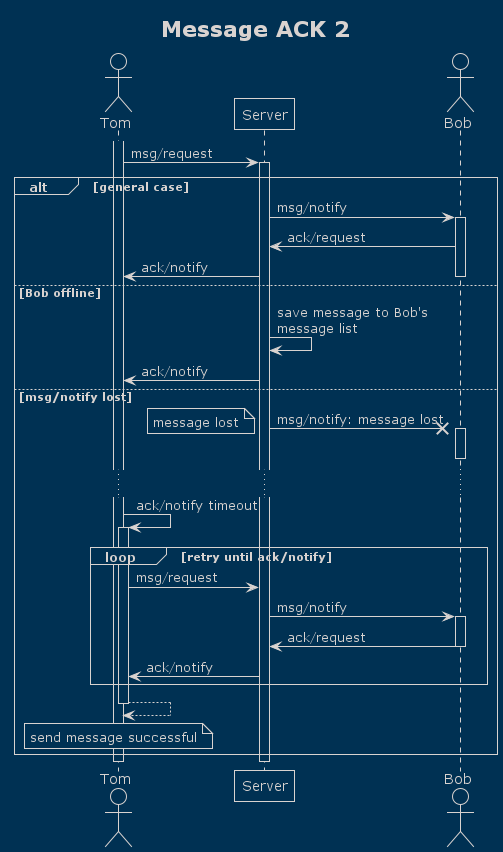
以上只是 GlideIM 保障送达的一部分, 实际上还有接收端根据 Seq 判断是否消息缺失等其他措施.
3.3 消息路由
在分布式环境下, 用户连接到不同的网关上, 我们必须知道用户所在的网关才能准确的投递消息, 因此, 必须在用户连接到网关的时候缓存所在网关信息, 在投递消息的时候才能准确地投递到用户所在网关.
GlideIM 的设计是在用户登录时在 Redis 中缓存网关信息, 我们当然不能每次发消息都查询 Redis, 可以在内存中缓存一份, 内存中没有则查询 Redis. 用户登录聊天服务后根据联系人列表所在不同网关, 通知网关更新自己的路由信息.
为了避免客户端频繁切换网关, 客户端接入网关由服务端在用户登录时返回, 这样做还可以为制定负载均衡策略, 多端登录连接同网关等做考虑.
3.4 保活机制
TCP 虽有 KeepAlive, 但其默认时间太长, 且不能判断服务是否可用或客户端是否可用, KeepAlive 仅仅保证 TCP 处于连接状态, 如果应用层发生错误, 服务端连接却依旧通畅明显是不行的.
心跳分为服务端心跳和客户端心跳, 大部分情况是客户端侧网络不通畅, 例如进电梯, 息屏省电模式, 而服务端一般只会在宕机的情况才会网络不通畅, 因此 GlideIM 在客户端进行主动心跳, 若在指定时间内服务端未收到心跳则服务端开始发送心跳包, 指定次数没有收到客户端心跳则断开连接.
客户端心跳为 30s, 但并不是每隔 30s 都发心跳, 而是 30s 内客户端没有主动发送任何消息, 则进行一次心跳, 服务端也是根据这个规则判断, 这样减少了心跳的次数的同时也能确保存活.
3.5 消息协议
消息协议需要考虑到消息编码后的大小, 可读性, 编码速度, 支持的语言等. 可以选择二进制协议和文本协议两种, 二进制例如 Protobuff, 或者自定义, 文本协议例如 JSON, XML.
GlideIM 同时实现了 Protobuff 和 JSON 两种消息协议. 客户端可以自由选择使用哪种协议, 在测试结果中显示 Protobuff 比 JSON 至少快 10 倍, 在使用 JSON 时整个流程中, 消息解析占用了很大一部分时间.
3.6 消息去重和排序
GlideIM 的消息去重依靠全局消息 ID, 消息 ID 暂时使用 Redis Incr, 后面会使用美团 Leaf, 在 GlideIM 中替换消息 ID 生成策略非常简单, 消息 ID 由客户端发送消息时获取, 发送时附带该 ID 以实现去重, 和发送方消息的排序.
在一对一单聊的情况, GlideIM 只保障发送方有序, 而一个会话内的所有消息是不必保障顺序的, 相对其付出的代价和带来的收益. 而群聊则是保障所有消息有序的, 群消息下发会附带当前群的连续递增 Seq, 收到群消息根据 Seq 排序, 若发现不连续则拉取不连续部分的消息.
四. 性能测试
GlideIM 消息面对高并发吞吐量压力测试:
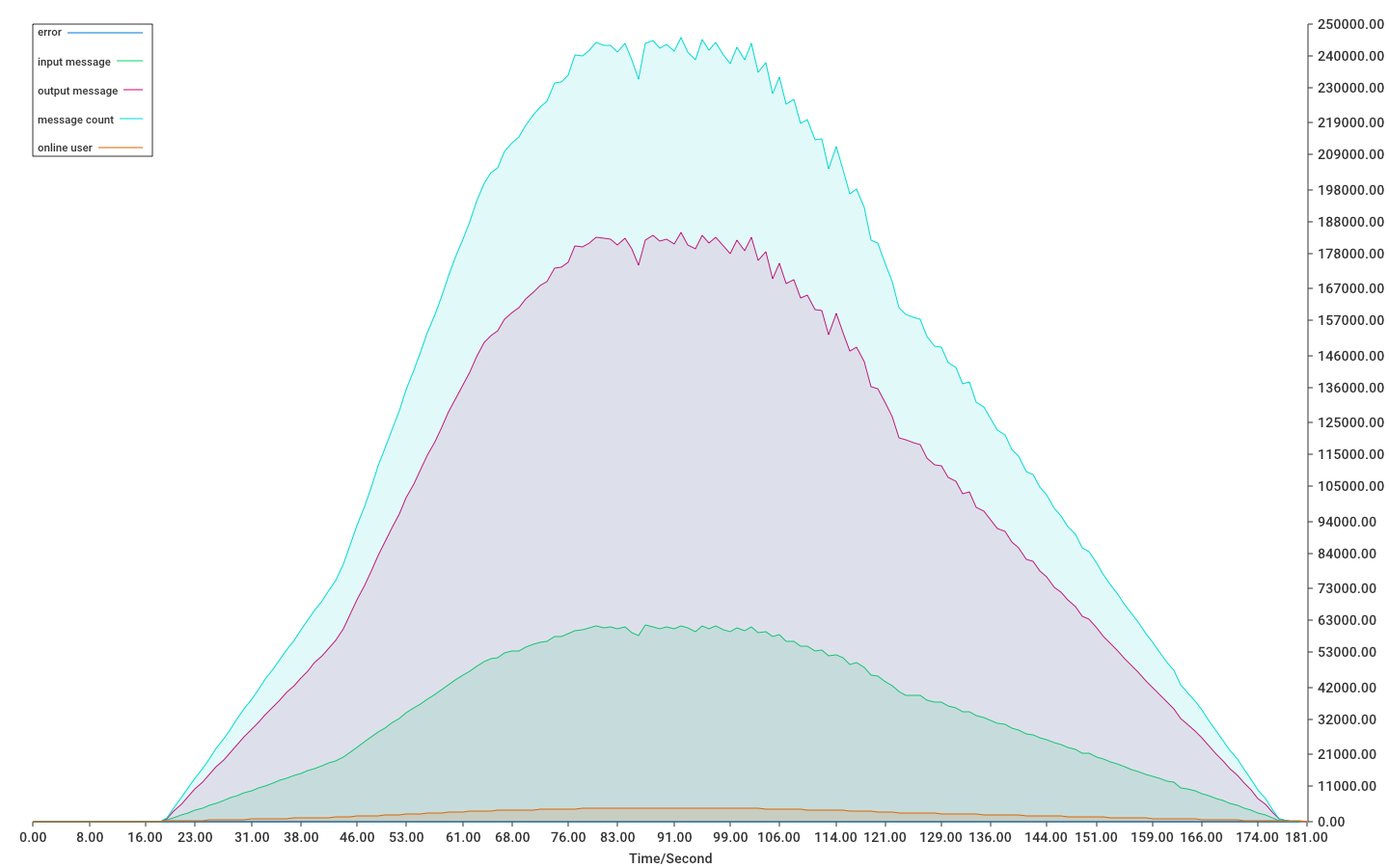
4.1 测试结果
单实例部署模式下, 4H8G, 100Mbps 宽带理论上支持 20w 活跃用户在线同时聊天, 此时带宽是性能的瓶颈.
4.2 测试过程
服务端配置
Windows 10
AMD R5 3600 6 核 12 线程
16GB 内存
100Mbps 网卡
案例 1 测试过程
A 机器运行服务端, B 模拟客户端连接登录发消息的过程, 并运行数据库
同时模拟 2000 客户端, 每间隔 60ms-200ms 发送一条消息, 每个客户端发送 600 条消息, 共计 1200_000 条消息.
网卡负载平均 90% (100Mbps), 每秒约 30_000 条消息吞吐量, 每秒上下行各 15k 条, 送达率 100%, 所有消息延时<=20ms, 参考结果 1 图.
测试情况:
网络 100%
2000 连接
5-20 条消息 /秒 /连接
30k 消息 /tps
送达率 100%
案例 2 测试过程
这个案例只为了测试程序在高并发情况下的运行情况, 参考价值也仅限于程序本身的短板和代码逻辑极限, 在实际情况中我们无法忽略网络速率等因素的影响.
由于需要去除网卡速率限制, 服务和模拟客户端都在同一台设备上运行则不受网络因素影响, 模拟 10000 个链接, 每个连接 50ms-100ms 发送一条消息, 总共发送 800 条.
此案例消息吞吐量极限为 28w, 此时已达到 cpu 性能极限, 占用率约 98%, 客户端模拟 cpu 占用率高于服务端, 但无关紧要.
测试案例 pprof CPU 使用情况分析数据: cpu.out
测试情况:
CPU 98 %
内存约 3 GB
10000 连接峰值, 每 10ms 开始一个连接
10-20 条消息 /秒 /连接, 累计发送 800 条
280k 消息 /tps 峰值
送达率 100%
测试环境限制
由于测试只有两台电脑, 存在端口数限制(部署到服务器, 用户连接不存在这个限制), 为了提高 MySQL 连接池的大小提高并发, 必须尽量用更少的连接数和每个连接更密集的发送消息来进行测试
百兆网卡上限速率只有 12.5MB/s, 一条消息包含 20 个汉字则至少需要 40B, 再加上报头其他占用, 假设 100B, 则实际百兆网卡最大的消息并发是 12.5 x 1024 x 1024 / 100 = 13w 条, 而去除 ACK, 再上下行消息数量对半, 实际可能就 6w/s 消息就是 GlideIM 在 100Mbps 环境下的理论极限.
测试代码
单机性能测试
测试代码路径: /cmd/performance_test/
1.启动服务器
go test -v -run=TestServerPerf
2.开始用户模拟
go test -v -run=TestRunClient
4.3 性能参考指标说明
连接数
很多 IM 项目喜欢用类似于 "百万连接" 之类的字眼, 很多人可能是受常规 HTTP 服务 "百万并发" 的影响, 认为百万连接与百万并发具有一致的性能参考价值, 开发者为了吸引眼球使用百万连接的字眼, 也确实支持百万链接.
事实上, TCP(或 WS) 连接数的限制并不在于程序本身, 系统最大可打开 文件描述符 和 内存 限制了最大连接数, 一个 TCP 连接大约需要占用 4-10KB 内存, 一台 16GB 的服务器理论上最大支持约 16 * 1024 * 1024 / 5 ≈ 335w 连接.
活跃用户数则比单纯的连接数更有参考价值, 例如支持 100w 活跃连接, 每个活跃连接 10s 发送一条消息.
消息吞吐量
相比连接数, 消息吞吐量更具有参考价值, 消息吞吐量需要结合网络速率做参考. 消息吞吐量受限点主要有一下几个:
- 消息送达保障机制的性能(即保障送达又不冗余)
- 消息数据传输协议的性能(单条消息尽可能减小体积)
- 非用户消息的数据包数量控制(例如心跳包, 内容同步包等)
- 网络速率和质量(外部因素)
- 程序本身消息下发设计缺陷
其他指标
考量一款 IM 的性能的意义大部分可能只在于揭示它自身的性能短板, 横向对比其他项目在大部分情况都无法得出正确的对比结果, 单项指标也不能完全衡量整个项目的优劣, 我们应该结合其业务逻辑, 设计思想, 学习其优点才能有所收获.
- 消息送达率
- 消息延迟和消息顺序的准确性
- 链接保活和去死链(心跳)
4.4 性能指标估算
1.连接数
假设设内存为 M GB
理论连接数 = M * 1024m * 1024k / (4k/tcp)
保守估算连接数 = M * 1024m * 1024k / (10k/tcp)
2.消息吞吐量估算
设网卡速率为 S Mbps, 平均每条消息为 K 字节(写入 TCP 连接时的总大小).
消息吞吐量 = S / 8 * 1024k * 1024b / K
3.活跃用户数估算
设吞吐量 T, 设平均每个用户每 N 秒发送一条消息.
- 在确认送达机制下 (每条消息的发送, 假设收发双方读在线, 服务端客户都需 ACK, 共需要 5 条消息上下行)
活跃用户数 = T / 5 * N
- 仅确认送达服务端
活跃用户数 = T / 3 * N
Golang Go语言实现的高性能分布式IM:GlideIM
更多关于Golang Go语言实现的高性能分布式IM:GlideIM的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html


请问怎么入门写一个 IM 系统? ( 搜了下似乎没有相关的中文书籍
更多关于Golang Go语言实现的高性能分布式IM:GlideIM的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

gorilla/websocket 或者其他基于标准库 net.Conn 的,一个连接 1-3 协程,面对海量连接数都吃力,可以试试我的:
github.com/lesismal/nbio
rpc ,我也写了个,性能更强一些、内存占用更少,扩展性、支持的功能更丰富甚至可以直接用于 IM 的通讯。但是服务之间 rpc 的连接数一般不大,所以用哪个也都还好,只是其他的框架 qps/tps 要差一些,如果有兴趣可以试下我的:
github.com/lesismal/arpc
benchmark 可以参考这些,最好是自己亲自跑、别直接参考库作者自己给出的结果:
github.com/micro-svc/go-rpc-framework-benchmark
github.com/rpcxio/rpcx-benchmark
github.com/cloudwego/kitex-benchmark



类似这样子go<br>func (a *App) Handle(method string, group string, path string, handler Handler, mw ...Middleware) {<br><br> // First wrap handler specific middleware around this handler.<br> handler = wrapMiddleware(mw, handler)<br><br> // Add the application's general middleware to the handler chain.<br> handler = wrapMiddleware(<a target="_blank" href="http://a.mw" rel="nofollow noopener">a.mw</a>, handler)<br><br> // The function to execute for each request.<br> h := func(w http.ResponseWriter, r *http.Request) {<br><br> // Pull the context from the request and<br> // use it as a separate parameter.<br> ctx := r.Context()<br><br> // Capture the parent request span from the context.<br> span := trace.SpanFromContext(ctx)<br><br> // Set the context with the required values to<br> // process the request.<br> v := Values{<br> TraceID: span.SpanContext().TraceID().String(),<br> Now: time.Now().UTC(),<br> }<br> ctx = context.WithValue(ctx, key, &v)<br><br> // Call the wrapped handler functions.<br> if err := handler(ctx, w, r); err != nil {<br> a.SignalShutdown()<br> return<br> }<br> }<br><br> finalPath := path<br> if group != "" {<br> finalPath = "/" + group + path<br> }<br> a.mux.Handle(method, finalPath, h)<br>}<br>




例如 web app, handle 到 业务逻辑 到 执行 db , 每个不同 package 的 function 都要求带入 ctx context.Context . ctx 里面包括请求的时间, id 等等信息。

关于Golang Go语言实现的高性能分布式IM——GlideIM,以下是我的专业回复:
GlideIM是一款基于Go语言实现的高性能分布式即时通讯系统,它以其卓越的性能和分布式架构,成为了众多开发者构建实时通讯应用的理想选择。
GlideIM支持单实例部署和分布式部署,能够轻松应对不同规模的用户需求。它采用了先进的协议处理和消息路由机制,确保了低延迟和高吞吐量的消息传递。同时,GlideIM还支持多种消息交换协议,如JSON和ProtoBuff,并提供了丰富的API接口,方便开发者进行集成和扩展。
在架构设计上,GlideIM采用了微服务架构,将IM业务拆分为多个核心主模块,每个模块可以水平扩展,提高了系统的伸缩性和稳定性。它还巧妙地融合了Redis、MySQL等数据库技术,以及ETCD和NSQ等分布式系统工具,进一步强化了服务发现和消息队列功能。
此外,GlideIM还提供了详尽的文档和示例代码,以及活跃的社区支持,帮助开发者快速上手和解决问题。无论是构建企业级内部通讯工具,还是社交应用、在线协作平台等场景,GlideIM都能提供稳定、高效、易于集成的实时通信解决方案。
综上所述,GlideIM以其高性能、分布式架构和丰富的功能特性,成为了Go语言实现分布式IM的佼佼者。