




我不是很懂 Node.js 社区的 DRY 文化
我不是很懂 Node.js 社区的 DRY 文化
原文在知乎,欢迎交(tu)流(cao)
我终于知道为什么 npm install 总是动不动就下载 300 Mb 的东西了,Node.js 社区强调的 DRY 文化使得
node_modules臃肿不堪,因为有的库引用了 is-object,有的库引用了 isobject,还有的库引用了 isObject,每个包看起来很 DRY,但是合起来就 wet 得不行了,呵呵。
我一直以为 npm 里下载量较大的 package 是 React 这样不错的包。
今天我才知道我错了。
目前 React 每周下载量是 240 万次。
然而下面我要说的几个包的下载量全都大于 React !
is-odd,每周下载 300 万次
源代码如下:
'use strict';
var isNumber = require(‘is-number’);
module.exports = function isOdd(i) {
if (!isNumber(i)) {
throw new TypeError(‘is-odd expects a number.’);
}
if (Number(i) !== Math.floor(i)) {
throw new RangeError(‘is-odd expects an integer.’);
}
return !!(~~i & 1);
};
你没有看错,五行核心代码,还依赖了一个 is-number 库。
这个 is-number 库更厉害,每周下载 1000 万次
源代码如下:
'use strict';
module.exports = function isNumber(num) {
var number = +num;
if ((number - number) !== 0) {
// Discard Infinity and NaN
return false;
}
if (number === num) {
return true;
}
if (typeof num === ‘string’) {
// String parsed, both a non-empty whitespace string and an empty string
// will have been coerced to 0. If 0 trim the string and see if its empty.
if (number === 0 && num.trim() === ‘’) {
return false;
}
return true;
}
return false;
};
后来我发现这两个库的作者是同一个人(该作者水平很高),这个人还写了另外几个库:
- is-plain-object,每周下载量 330 万
- is-primitive,每周下载量 350 万,源代码你自己可以看看
- isobject,每周下载量 750 万
需要指出的是
- webpack、babel 等库都有「间接地」依赖上面的一些包。
- 这些包的 markdown 代码远远多于 JS 代码,可能它们的 markdown 更值得我们学习
这件事对我的启发:
- 原来有这么多 JS 程序员不会判断奇数
- 只要 markdown 写得漂亮,就能迷倒 JS 程序员
- 1 + '1' 的问题一直在困扰 JS 程序员,我要不要写一个 add() 库解决这个问题呢
我终于知道为什么 npm install 总是动不动就下载 300 Mb 的东西了,Node.js 社区强调的 DRY 文化使得 node_modules 臃肿不堪,因为有的库引用了 is-object,有的库引用了 isobject,还有的库引用了 isObject,每个包看起来很 DRY,但是合起来就 wet 得不行了,呵呵。
Node 社区跟我想得不太一样,说不上好也说不上坏,反正不是很适合我。
以下是扯淡。
我是看到 Medium 上的一篇《混乱又危险的 Node.js 生态》才知道这些的,这篇文章里的一个评论我很赞同:
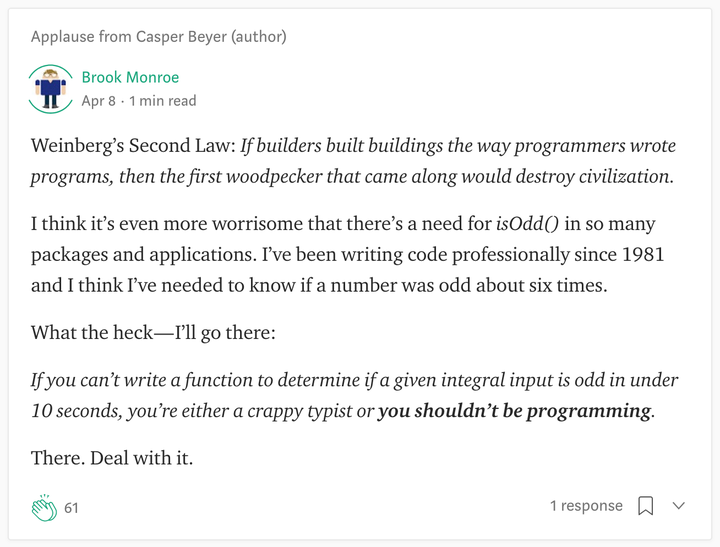
如果你不能在十秒钟内写出一个判断奇数的函数,要么你是一个糟糕的打字员,要么你就不应该当程序员!
还有一些颇为搞笑的评论:


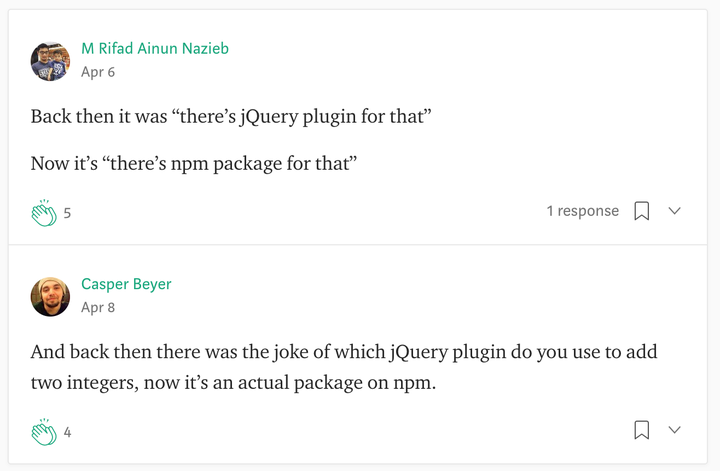
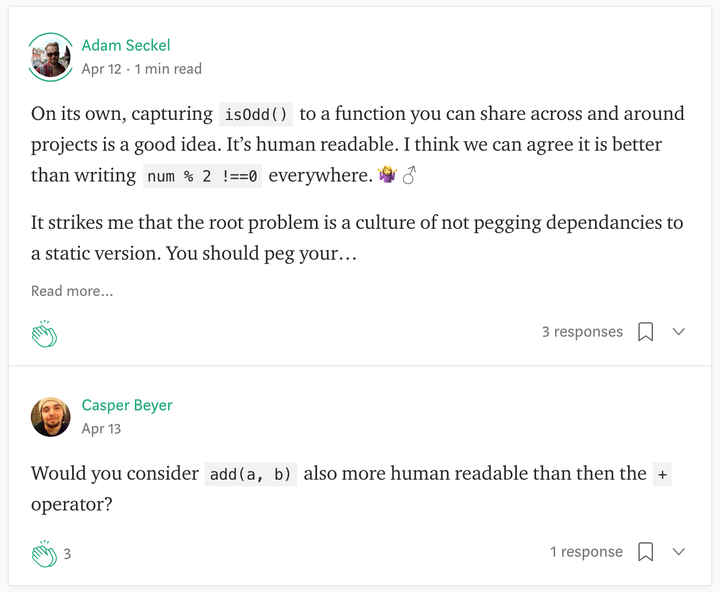



讽刺 JS 程序员写代码不带脑子哈哈,说实话我从写代码第一天就是用 n % 2 === 1 来判断奇数,到底是什么人才会想要去引用一个库……是因为不会 % 运算符吗……

有找包的时间早写了,我这俩月上业务一些 nodejs 就连续碰到三次因为基础库的基础库的基础库更新不兼容故障,就是几行代码,结果自下而上崩塌了。我现在很喜欢用 docker 包装 go








好多都是 JS 语法本身的坑,比如判断是不是字符串,是不是函数这种最基本的,都没有简单的方法。再加上早期核心对象的方法缺失,虽然后来补上了,导致某些常用功能要做额外的判断方法是否存在,或者要做 polyfill,比如字符串的 trim 这种。还有现在 ES2015+更新的语法和标准函数对象的快速增加,不得不同时采用 polyfill 和 babel 这种语法转换工具,以兼容比较老的浏览器版本。

顺便一提,你以为动不动就下载 300M 是 node 特有的问题?
事实上每个包管理工具都是这样的。pip,maven,npm 无一例外。这种现象的出现时由于依赖库太多或太重。另外,包括 npm 在内的所有包管理工具都是有本地仓库做缓存的。所以事实上日常使用中大部分情况都是走缓存,很少需要下载新包。
npm 真正存在的问题是所有依赖文件全部会复制一份到项目文件夹,项目启动时所有依赖资源打包在项目内。而不是其他工具一样,将包留在本地仓库中,解析依赖时从仓库进行加载。
这种库一般来说都是严格按照 ES6 或者 ES5 的规范实现的
为什么需要个库
因为 ES 规范就这么定义的 如果要把这些稍微超前一点的东西在 IE 上运行 你少写一行他不就不满足规范




神烦那些什么都要引入一个包的人,为了一个方法引入整个 lodash。还有一些很简单的库,明明写一个也不用多少时间。他引入了,为了确保准确,还得去找这个包来看 api 作用。🙄
> 1.原来有这么多 JS 程序员不会判断奇数
is-odd 每周下载 300 万是因为[nanomatch]( https://www.npmjs.com/package/nanomatch) 中引用了, 引用的原因看这个(pul requests)[https://github.com/micromatch/nanomatch/pull/7]
> 讽刺 JS 程序员写代码不带脑子哈哈…
明显是编程风格问题, 楼主提高到 JS 程序员的角度不知道楼主提问题带不带脑子
工具集不符合社区推崇的是最小化 import,如果 is-odd 被项目里的 100 个包引用了,那最终产出的相关逻辑代码只有一份,但如果每个包自己实现了 is-odd,你在最后项目里就有 100 份相同代码

驳《我不是很懂 Node.js 社区的 DRY 文化》
https://mp.weixin.qq.com/s/OQsXOeah0ENK7Y6anAbXgg
我只是转一下,大家别打我。。
用不用这种总结前人经验的库,看你自己对自己的期望了。如果只是为了完成一份工作,那就自己写个简单的功能代码即可,万一出问题了,debug 解决呗。
如果是想成为一个优秀的开发者,这种库肯定要用啊,这是别人的经验,都已经帮你把坑都填了,非要自己再去踩坑?
转发:驳《我不是很懂 Node.js 社区的 DRY 文化》
https://segmentfault.com/a/1190000014480379?utm_source=index-hottest
#72
“在回过头来看看 is-number 库,不仅仅有 100 多行的 test case,还有一个目录 benchmark。这里面的代码我没有数,但是光看文件数量就有 10 个以上。也就是说作者不仅仅保证了这个函数的运行结果没有问题,更保证了这个函数的性能。
我们为什么要使用这个库,因为作者为了他的 10 行代码,写了几百行的其它代码来保证质量。”
惊呆了。。。
#72
http://zhuanlan.zhihu.com/p/35870240 驳《驳《我不是很懂 Node.js 社区的 DRY 文化》》
https://zhuanlan.zhihu.com/p/35880323 请 Node.js 社区正面回答
楼主说的挺好
就是那三句结论,全文最大的败笔呀,程序猿写结论的时候不应该开这种逻辑明显错误还迎战的玩笑
所以我的结论是
楼主文章没错,指出了 node 社区的问题,但是结论涉及引战
这对讨论问题没有任何帮助,你要是真想好好讨论问题,就别写这种槽点满满的结论
除非,你只是为了制造热度
可能是缺少一个大头来做库收集和论证
就像 C++的的 stl 和 boost 库一样,每个轮子都需要先进 boost 论证完才能进入 stl 库
有权威人士为其使用代价来背书
而 node.js 则是过于强调个人,这个作用用了 XXX 库,“你看作者这么牛逼,应该采用他写的库”;
而且第二天另外一个作者也做了相同功能,"你看那个作者写的这么牛逼,这些库我们也得引用"
实际上通过权威来论证他们合理性和坑点之后,其他人看到之后也就会自然而然的规范自己使用方式
(当然很多开发都是喜欢自己造轮子的,比如很多著名的 C/C++都是自己搞自己的字符串库)
1。250 多万 is-odd 的下载量得出这个结论我不觉得很过分,他们就是不会写判断奇数……
s-odd 300W 的下载量来自 nanomatch, 很明显 nanomatch 的人不会判断奇偶性(虽然是一个人写的。。。
2. 动不动就下载 300 Mb 的东西,
是的,引用 4000 多字节的 is-odd 会让我们的依赖越来越大,所以我们要多用 24K 的 lodash.
3. 我终于知道为什么 npm install 总是动不动就下载 300 Mb 的东西了,Node.js 社区强调的 DRY 文化使得 node_modules 臃肿不堪,因为有的库引用了 is-object,有的库引用了 isobject,还有的库引用了 isObject,
麻烦楼主给个分析, 你 300 Mb 的依赖到底是来自各种各样的 isobject,is-number 这种仓库还是来自别的地方
4. 成堆的 one-line lib,用的人还贼多,
142 引用 的 is-number 用的人贼多
65955 引用 的 lodash 没人用
你们 node 社区都爱用 is-number 这种 one-line lib
5.关键是大部分库名称类似、质量还不高
module.exports = function isOdd(i) {
if (!isNumber(i)) {
throw new TypeError(‘is-odd expects a number.’);
}
if (Number(i) !== Math.floor(i)) {
throw new RangeError(‘is-odd expects an integer.’);
}
return !!(~~i & 1);
};
这种质量太差了, 明显不如 %2 质量高
6. 每个库引用了不同的 one-line lib,导致代码非常重复,而且使用者还没法分析重复在哪
麻烦楼主贴一下, 到底这些 one-line lib 怎么重复的,让你的依赖到了 300m

js 为了在浏览器里怎么也不崩溃 代码依赖都没下完都能跑 所以才那么乱的
从骨子里就不适合严格的编程
那个奇数计算里的各种判断就是 tm 多余的
哪个动态语言每次计算有要先判断类型的
要判断也是数据入口做 独立出 type 验证方法 而不是写在计算里
这种库就是在浪费性能
看完了 is-number 解释为什么要建立这个库:
https://gist.github.com/jonschlinkert/e30c70c713da325d0e81
我决定以后开始用它了 
js 的用法好像机器语言阿 …
其他人为了解决机器语言不好写的问题,发明了高级语言
M$ 为了解决机器语言不好写的问题 发明了 高级语言 TypeScript
“另一些人” (也就是 Node.js 社区的人) 为了解决机器语言不好写的问题,发明了 “高级机器语言”
https://zh.m.wikipedia.org/wiki/TypeScript
不同方向走向了不同的地方 …
关于Node.js社区的DRY(Don’t Repeat Yourself)文化,这是一个旨在提高代码复用性和维护性的理念。下面我将从几个方面来解释这一概念,并附上简单的代码示例。
DRY原则的核心思想是避免重复代码。在Node.js社区,这通常通过npm(Node Package Manager)上的第三方库来实现。例如,一个常见的任务是检查一个数字是否为奇数,你可以自己写一个函数:
function isOdd(num) {
return num % 2 !== 0;
}
然而,按照DRY原则,如果这个功能已经被广泛使用的库(如is-odd)实现,那么最好直接使用这个库,而不是自己重写。这样做的好处包括:
- 减少代码量:避免重复代码,使项目更简洁。
- 提高可维护性:依赖经过验证的库,减少因自己实现的错误而引入的bug。
- 社区支持:使用广泛的库通常有更好的文档和社区支持。
此外,Node.js社区的DRY文化还鼓励开发者分享自己的代码作为库,供其他人使用。这有助于建立一个丰富且不断增长的生态系统,使开发者能够更高效地构建应用程序。
综上所述,Node.js社区的DRY文化是一种促进代码复用和维护性的重要理念,通过npm上的第三方库实现,有助于开发者构建更高效、更可靠的应用程序。