





HarmonyOS鸿蒙Next应用崩溃闪退场景分析
HarmonyOS鸿蒙Next应用崩溃闪退场景分析
崩溃介绍
崩溃指应用/系统进程非预期的退出。目前常见有JS Crash、CppCrash、AppFreeze、资源泄露等故障导致崩溃。
日志获取
崩溃日志是一种故障日志,与Native进程崩溃、JS应用崩溃、系统进程异常等都由FaultLog模块管理,可通过以下方式获取日志:
方式一:通过DevEco Studio获取日志。
DevEco Studio会收集设备的故障日志并归档到FaultLog下。具体可参考DevEco Studio使用指南-FaultLog。
方式二:通过hiAppEvent接口订阅。
hiAppEvent 提供了故障订阅接口,可以订阅各类故障打点,详见HiAppEvent介绍。
CPPCrash(进程崩溃)案例分析
问题介绍
进程崩溃指C/C++运行时崩溃,当未处理以下信号时会导致cppcrash。

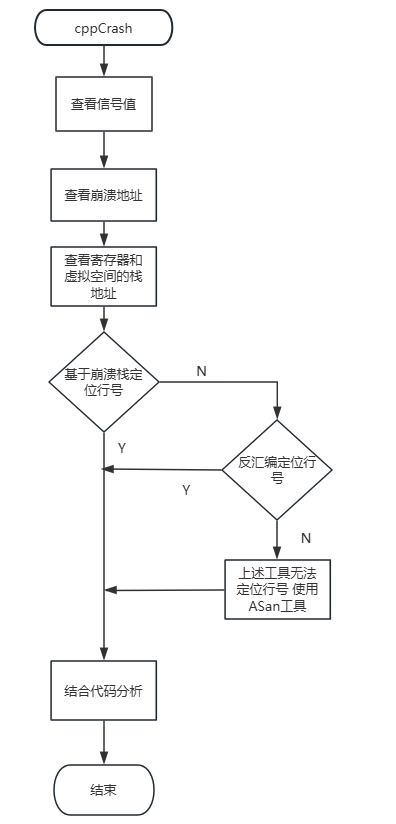
cppcrash日志查看思路:

流程图如下:
-
查看信号值
通过信号值可以分辨出cppcrash是属于哪个故障类型的,如果是SIGABERT,那就需要查看调用abort的代码,此处代码可能就是引发故障的地方。 -
查看崩溃地址
崩溃日志中Signal会携带崩溃访问的地址,如非法访问地址会触SIGSEGV、访问合法地址但地址指向的不是代码段会触发SIGILL 。例如图中0x00000004是一个很小的数,一般来说小于4096,基本是空指针的问题。 -
查看寄存器和虚拟空间的栈地址
检查sp(堆栈指针寄存器)是否不在栈地址范围内或靠近栈的低地址,应当考虑可能发生了栈溢出。 -
基于崩溃栈定位行号
方式一:DevEco Studio开发者环境下支持调用栈直接跳转到对应行号。
在应用开发场景,对于应用自身的动态库,生成的cppcrash堆栈可直接跳转到代码行处,支持Native栈帧和JS栈帧,无需开发者自行进行解行号操作。对于部分未能解析跳转到对应行号的栈帧,可参考方式二解析。
方式二:通过SDK llvm-addr2line工具定位行号,通过llvm-addr2line工具定位行号,1lvm-addr2line工具归档在:[SDK DIR PATH]\OpenHarmony\11\native\llvm\bin路径下,根据实际的SDK版本路径略有不同。
llvm-addr2line逐行解析的命令为:Ivm-addr2line.exe -/Cpie libutils.z.sO编移量,偏移量可以多个一起解:Ilvm-addr2line.exe -fCpie libxxx.so 0x1bc868 0x1be28cxxx。
- 反汇编(可选)
一般而言,如果是比较明确的问题,反编译定位到代码行就能够定位。较少数的情况,例如定位到某一行里面调用的方法有多个参数,参数又涉及到结构体等,就需要借助反汇编来进一步分析。objdump二进制是系统侧工具,开发者需要具备OpenHarmony编译环境。
命令如下:
llvm-objdump -d libark jsruntime.so > dump.txt- 使用地址越界检资工具(可选)
当以上步骤无法分析出问题,应当考虑是踩内存问题,借助检查工具做进一步分析:ASan检测。
场景分享:
场景一:重复释放致使空指针导致崩溃
日志表现:
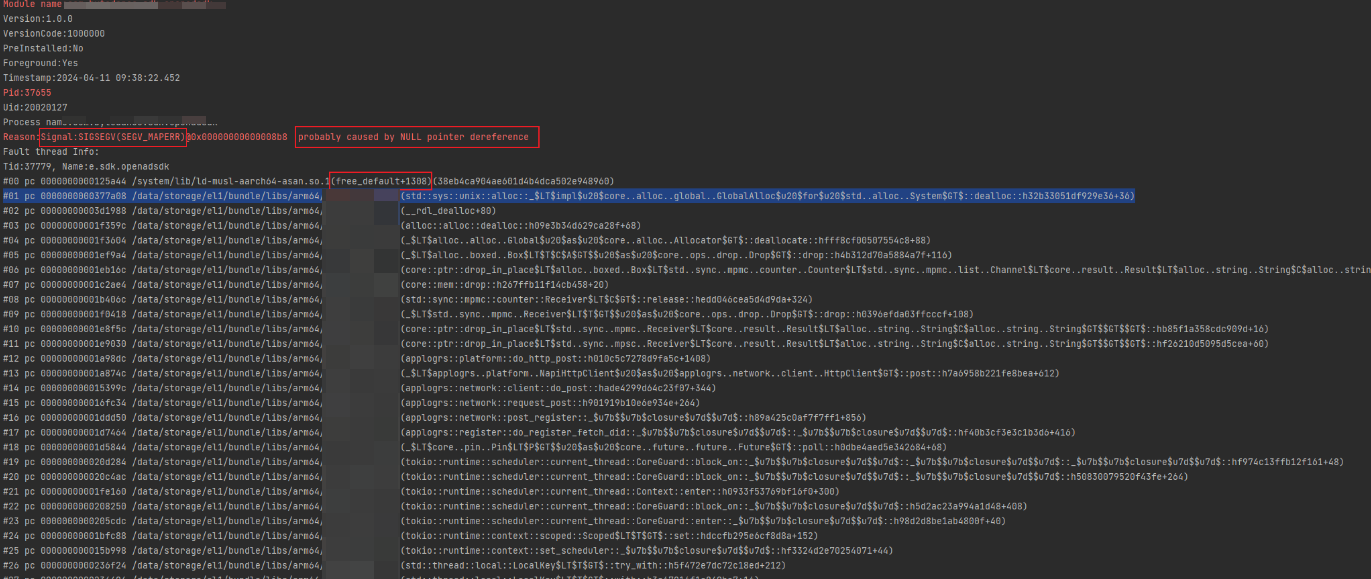
分析:
- 查看信号值,Reason 是Signal:SIGSEGV(SEGV_MAPERR) 、 提示信息probably caused by NULL pointer dereference,可能是空指针或非法地址。
- 查看崩溃地址,地址较小。
- 堆栈指针寄存器在栈地址范围内,结合2可排除栈溢出。
- 查看堆栈信息,未栈顶为开发者的 libapplogrs.so 里调的 free 操作,那么可以推测是开发者释放了空指针导致,大概率是重复释放的问题。
- 从第一行开始反编译,发现 [#01,#11] 的代码并不是开发者写,是由 librust 框架实现的,最后发现在崩溃栈的#12,发现里面有一个 remove 的方法释放,但是除了 remove 没有其他释放动作。
- 反汇编该部分代码,发现 do_http_post 中确实多了一些 drop_in_place 函数,说明是在编译代码时由 librust 框架添加了一批析构函数,崩溃栈中的 [#01,#11] 是由 drop_in_place 函数调下去的。
- 所以推测导致崩溃的原因为重复释放,代码先在 recv_timeout 中接收了一个返回对象,然后后面回调中使用 remove 手动释放了对象内的一个变量,导致在 librust 框架析构时,再次 free 释放了该变量的内存区域。
- 将 remove 注释后重新编译测试,没有出现启动崩溃问题。
场景二、踩内存导致崩溃
日志表现:
应用在使用中高概率崩溃,且生成的崩溃日志种类丰富。
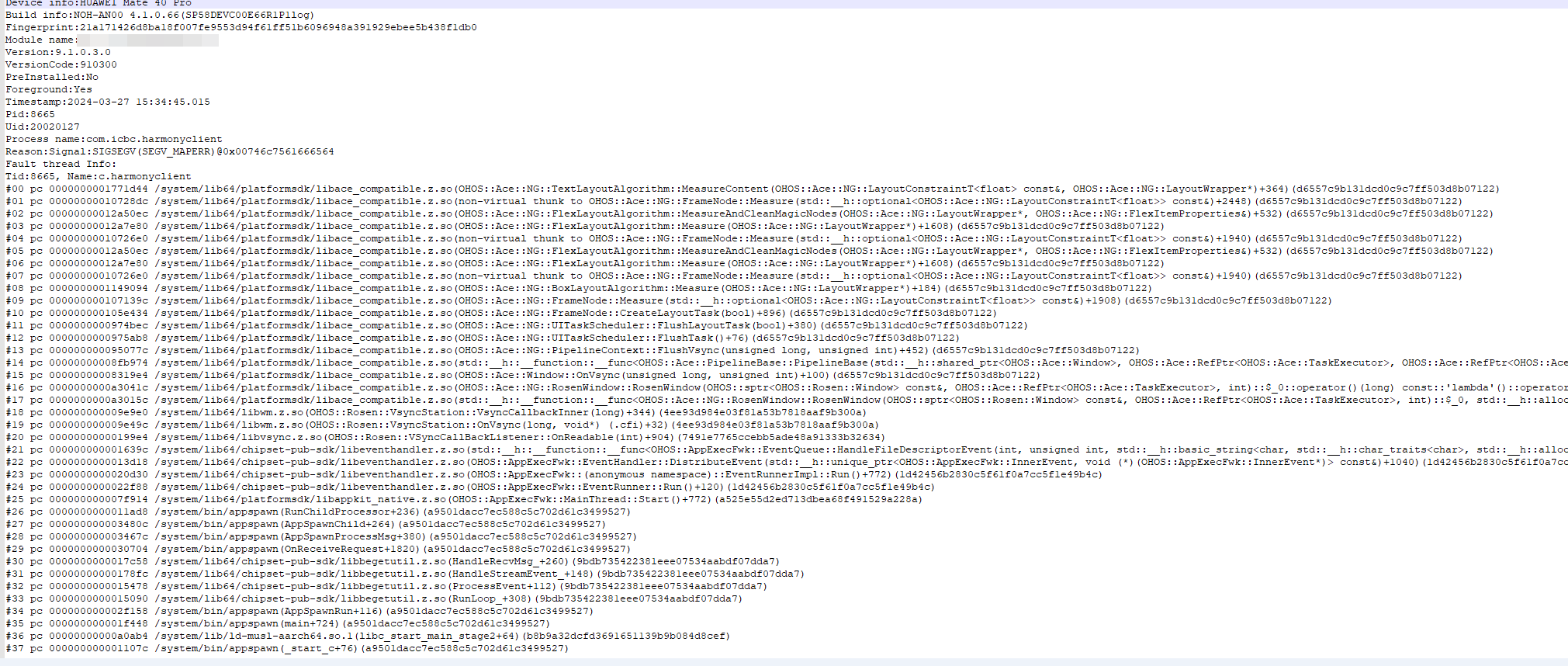
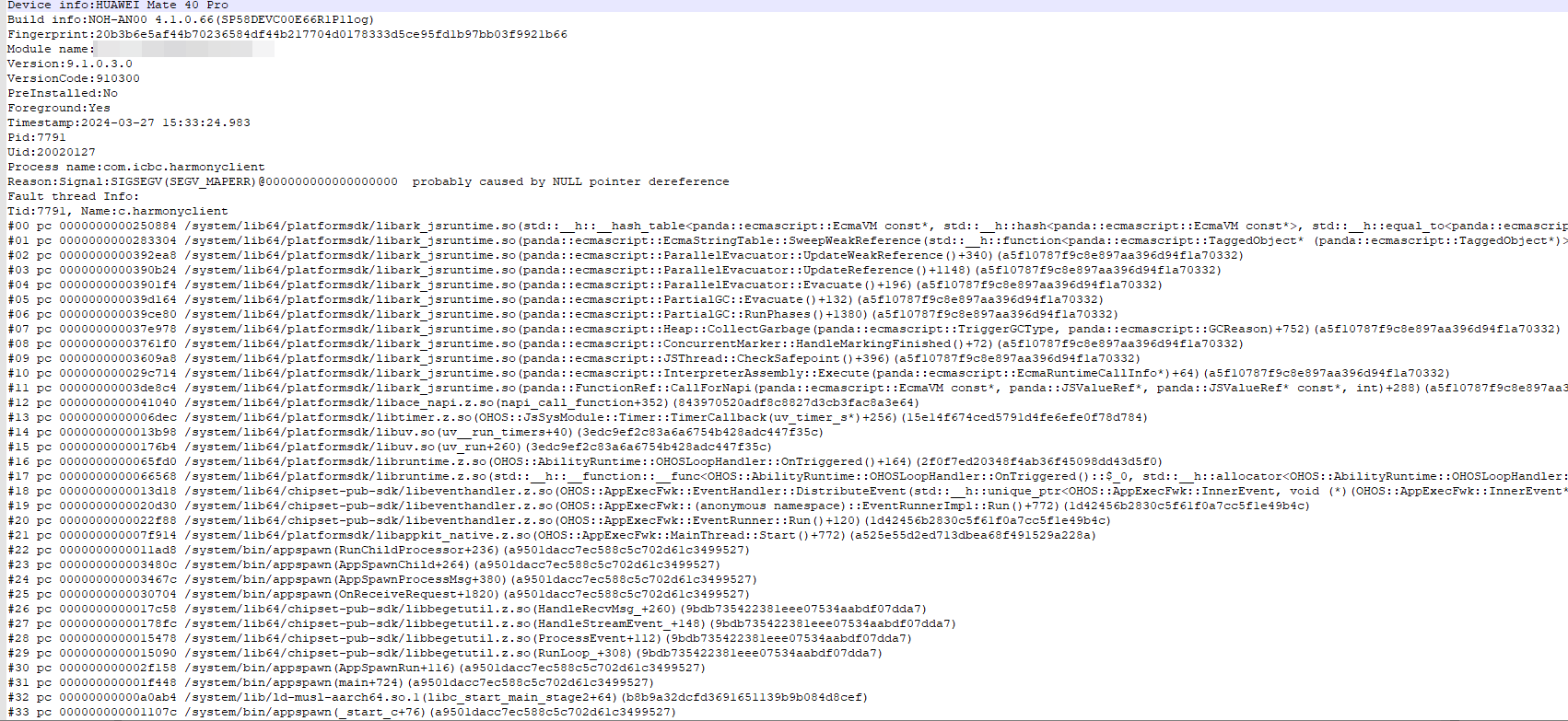
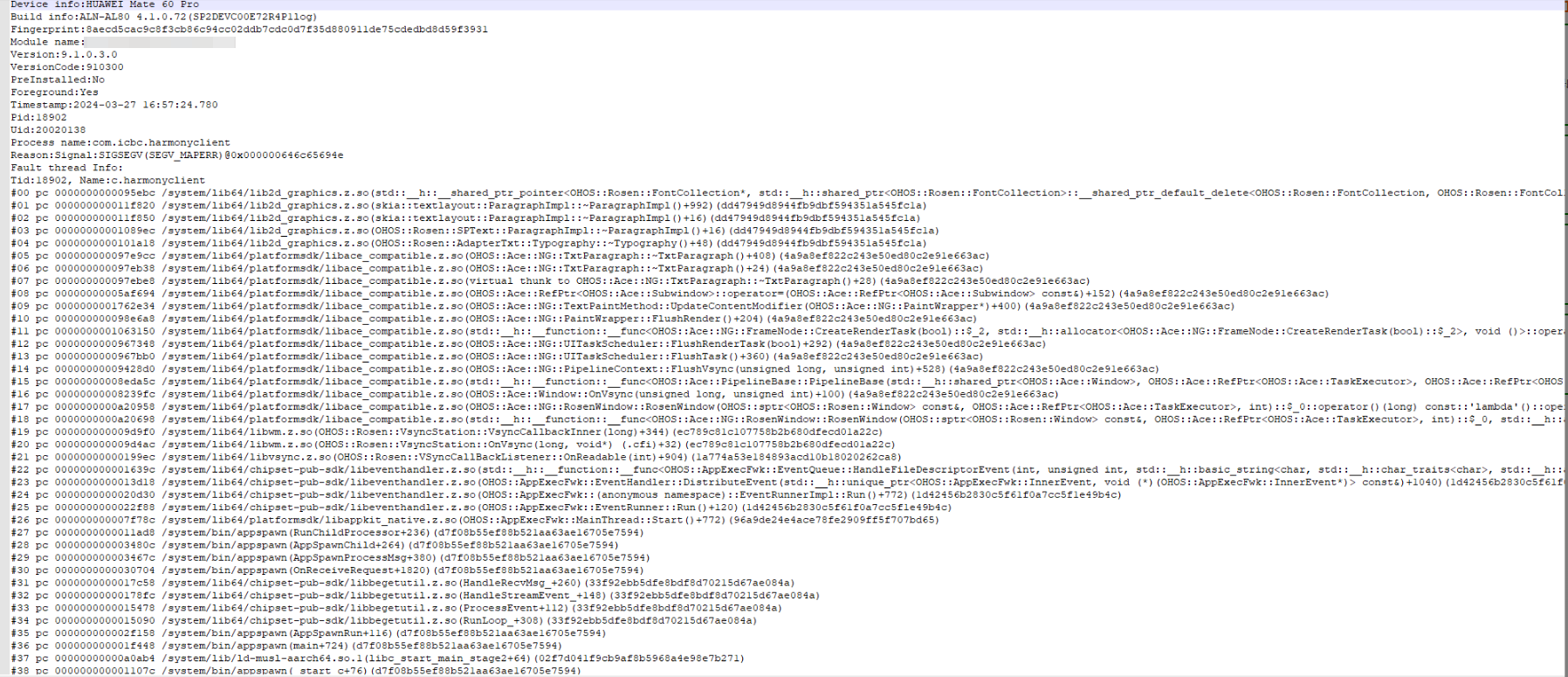
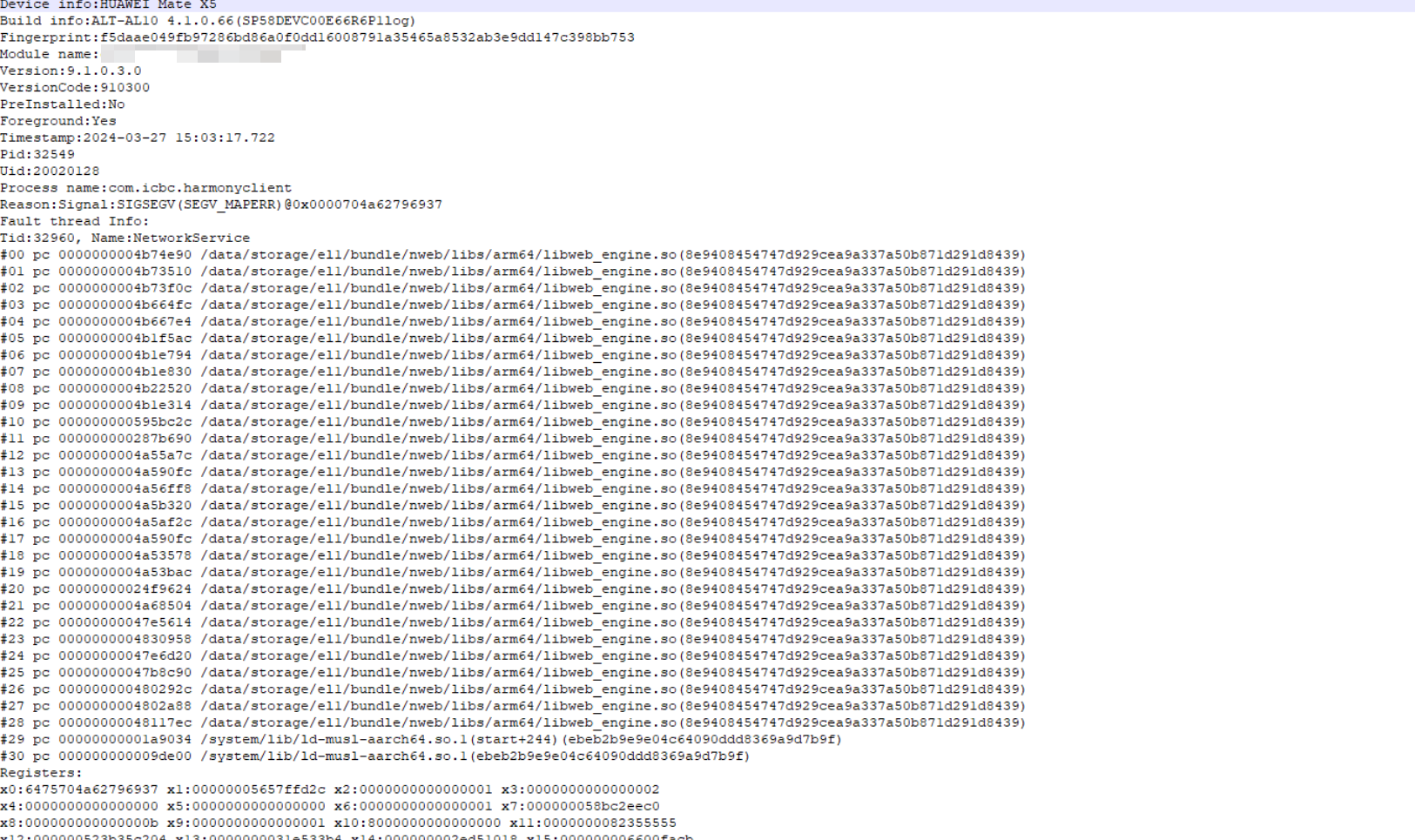
以上崩溃问题基本都是在同一场景下触发,崩溃日志太过随机,所以推测是踩内存导致崩溃,因为每次日志不同,所有不能直接使用上述1-4的定位流程,需要使用第6步的Asan压测。
案例1:引用了已释放的对象或变量
分析:
- 应用崩溃,通过ASAN压测出的日志,首行信息为:heap-use-after-free(ASAN),大致是引用已释放内存问题。
- 在崩溃日志中可以看到变量的申请、释放、引用都在线程T22中。
- 通过行号地址去找对应代码,结合代码分析,上图逻辑流程大致为: 1)src/dsf/source/dccadapter/adapter/CDiamContext.cpp:72 的 CDiamContext::InitDynamicData() 函数里创建对象m_pCtxData 2)src/dsf/source/dccadapter/adapter/CDiamContext.cpp:79 的 CDiamContext::UninitDynamicData() 函数里释放对象m_pCtxData 3)src/dsf/source/dccadapter/service/CDiamOM.cpp:907 的 CDiamOM::RefreshUpdateTimeMap() 函数里又引用已释放的对象变量m_pCtxData->m_tSrvFlowRoutInfo.m_tDccToSrvOut.pszServiceName
结合上述分析可以确定是引用已释放的对象导致崩溃
案例2:地址越界访问
分析:
- 应用崩溃,通过ASAN压测出的日志,首行信息为:heap-buffer-overflow(ASAN)。
- 通过日志由上往下看,GetInfoExecutor.cpp 第166行代码申请了一块9字节大小的空间[0x602000054170,0x602000054179),但是在221行却访问在0x602000054179的位置,造成地址越界访问。
- 结合代码分析,可以看到166行的 NEWA 函数创建了9个 char 的字符串空间,switch中只有1个case,没有完全覆盖nType的类型,导致下面if-else中存在 m_pRetMsg->m_MsgBody 没有赋值的情况,所以在221行打印日志时造成地址越界访问。
案例3:野指针指向内容异常
分析:
- 应用崩溃,通过ASAN压测出的日志,首行信息为:SEGV on unknown address(ASAN),Hint: address points to the zero page. ,说明是有指针指向了空内容导致的崩溃,一般是未初始化、所指的对象已消亡、指针释放后未置空等原因导致的。
- 结合代码分析,可以看到有 malloc 申请了一块内存给到 wd->items,但是未初始化赋值,而下面却使用了 wd->items[i]->state 判断,访问了野指针导致崩溃。
场景三、无故障日志场景分析
问题介绍
应用崩溃退出,但是并未抛出故障日志或者故障日志丢失,导致无法定位问题
定位思路:
排查流程图如下:
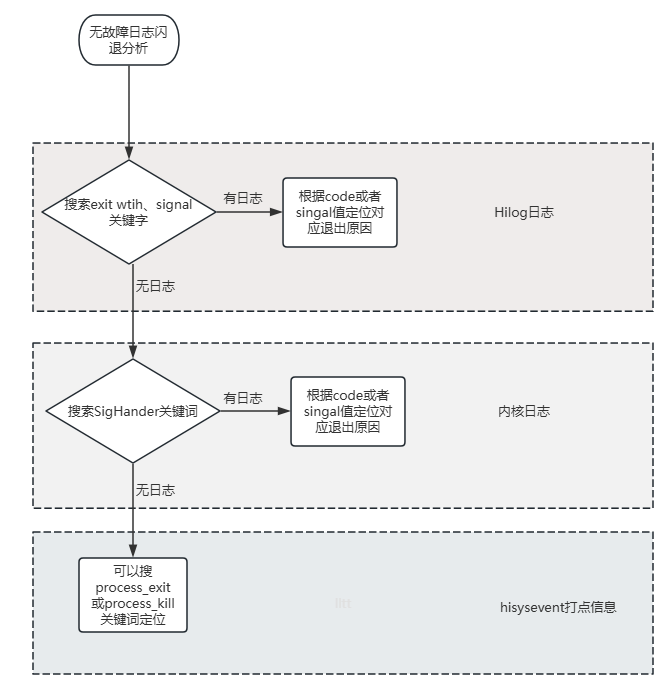
- Hilog搜索exit with code、signal关键字
进程退出日志打印:
进程退出不一定是cppcrash,,目前在appspawn/init中添加了进程退出的打印,具体可看下述关键字
AppSpawn打印Hilog中的日志如下:

signal13:是因为因为管道破裂,13是不会生成cppcrash。
管道破裂,这个信号通常在进程间通信产生,比如采用 FIFO(管道)通信的两个进程,读管道没打开或者意外终止就往管道写,写进程会收到 SIGPIPE 信号.此外用 Socket 通信的两个进程,写进程在写 Socket 的时候,读进程已经终止.另外, 在 send/write 时会引起管道破裂,关闭 Socket, 管道时也会出现管道破裂.使用 Socket 一般都会收到这个 SIGPIPE 信号。也就是说, 该信号是跟 Socket 的连接以及数据的读写相关联的。这种 Crash 大都数是在用户网络不好的情况下发生。
目前有两个方案可用:
方案1. 忽略这类信号。
方案2. 修改源码。
因为一般无法更改其源码, 所以采取了方案1: 忽略这类信号。
Code 0 :
1)由元能力主动调度的退出,例如操作了下滑、back健正常退出。
2)或者代码调用了exit的系统接口退出,例如Process.exit退出。
说明:关键字也可存在以下情景:
signal 6/signal 11: Native代码异常。
signal 9:系统管控(内存、功耗)。
- 内核日志搜索Signal_handler关键字。
对于服务进程来说,生命周期管理是由init来做的,Init打印到Hilog的日志如下:

如上图也可以通过code、signal的等关键字判断退出原因。
- 如果上述日志都丢失了还可以搜索HiSysEvent的打点
使用"hdc shell hisysevent -l"命令完成对已落盘的系统事件的查询。

对于进程退出可以搜process_exit上图可以看到status:9对应signal9是应用主动杀的。

或者搜索process_kill,会有详细信息。如上图是reason:Memory Pressure是因为低内存原因被杀掉。
更多关于HarmonyOS鸿蒙Next应用崩溃闪退场景分析的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


在HarmonyOS鸿蒙Next中,应用崩溃闪退的场景分析主要涉及以下几个方面:
-
资源管理问题:当应用在运行过程中未能正确管理内存、CPU等系统资源时,可能导致应用崩溃。例如,内存泄漏、频繁的内存分配与释放不当等。
-
API调用错误:应用在调用系统API时,若参数传递错误或调用了不支持的API,可能导致应用异常退出。
-
多线程同步问题:在多线程环境下,若线程同步处理不当,如出现死锁、竞态条件等,可能导致应用崩溃。
-
系统兼容性问题:应用在特定设备或系统版本上运行时,可能存在兼容性问题,导致应用无法正常运行。
-
第三方库或服务问题:应用集成的第三方库或服务若存在bug或不兼容问题,也可能导致应用崩溃。
-
UI渲染问题:在UI渲染过程中,若出现布局错误、视图层级问题等,可能导致应用界面无法正常显示,进而引发崩溃。
-
异常处理不当:应用中若未合理捕获和处理异常,可能导致应用在遇到异常情况时直接退出。
针对上述场景,开发者需通过日志分析、代码审查、性能监控等手段,定位并解决应用崩溃的根本原因。
更多关于HarmonyOS鸿蒙Next应用崩溃闪退场景分析的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html
