




Golang Go语言中计算两个字符串相似度,它来了,后端集成多种算法
Golang Go语言中计算两个字符串相似度,它来了,后端集成多种算法
strsim
strsim 是 golang 实现的字符串相识度库,后端集成多种算法,主要解决现有相似度库不能很好的处理中文
![]()
![]()
项目地址
https://github.com/antlabs/strsim
构架
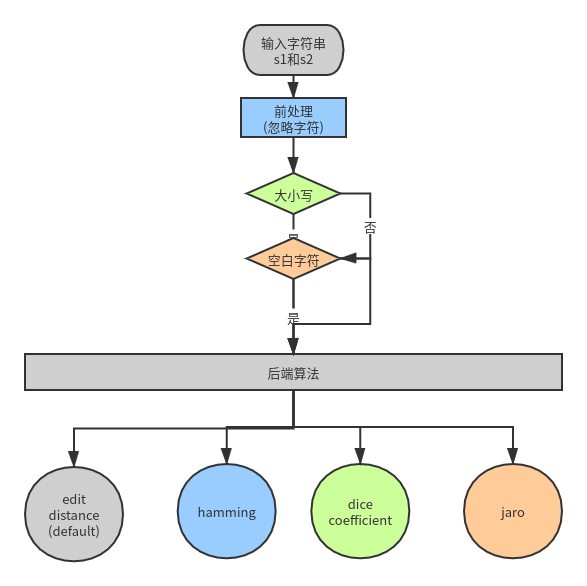
功能
- 可以忽略空白字符
- 可以大小写
多种算法支持
- 莱文斯坦-编辑距离(Levenshtein)
- Hamming
- Dice's coefficient
- Jaro
内容
- 比较两个字符串相识度
- 从字符串数组里面找到相似度最高的字符串
- 选择不同算法
- 莱文斯坦-编辑距离(Levenshtein)
- [选择 Dice's coefficient](#选择 Dice's-coefficient)
- [选择 jaro](#选择 jaro)
- [选择 Hamming](#选择 Hamming)
比较两个字符串相识度
strsim.Compare("中国人", "中")
// -> 0.333333
从数组里找到相似度最高的字符串
strsim.FindBestMatchOne("海刘", []string{"白日依山尽", "黄河入海流", "欲穷千里目", "更上一层楼"})
选择不同算法
莱文斯坦-编辑距离(Levenshtein)
strsim.Compare("abc", "ab")
// -> 0.6666666666666667
选择 Dice's coefficient
strsim.Compare("abc", "ab", strsim.DiceCoefficient(1))
//-> 0.6666666666666666
选择 jaro
strsim.Compare("abc", "ab", strsim.Jaro())
选择 Hamming
strsim.Compare("abc", "ab", strsim.Hamming())
更多关于Golang Go语言中计算两个字符串相似度,它来了,后端集成多种算法的实战教程也可以访问 https://www.itying.com/category-94-b0.html

最后一个例子,两个不等长的字符串计算 Hamming distance ?
更多关于Golang Go语言中计算两个字符串相似度,它来了,后端集成多种算法的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html






刷题的时候写过 Levenshtein 算法,实现起来不难,20 行不到,很多用在命令行工具上,当你敲错了命令,就可以提示 command not found, did you mean “xxxxx xxxxx”




几个意见:
1. 编辑距离有更快的 Ukkonen 算法: https://github.com/sunesimonsen/ukkonen
2. best_result 在不同算法下有不同的解法。比如在编辑距离下,相似度最高的字符串可以用前缀数拿到: https://www.microsoft.com/en-us/research/wp-content/uploads/2016/02/sigmod513.pdf


在Go语言中计算两个字符串的相似度是一个常见的需求,特别是在文本处理、信息检索和自然语言处理等领域。Go语言以其简洁、高效和强大的标准库著称,为这种需求提供了多种解决方案。
后端集成多种算法来计算字符串相似度,可以大大提升系统的灵活性和准确性。常见的字符串相似度算法包括:
-
余弦相似度:通常用于计算两个文本向量在向量空间中的夹角余弦值,适用于大规模文本数据集。
-
Jaccard相似度:通过计算两个集合交集与并集的比例来衡量相似度,适用于布尔型数据或集合型数据。
-
Levenshtein距离:又称编辑距离,通过计算将一个字符串转换成另一个字符串所需的最少编辑操作数来衡量相似度,适用于精确匹配需求。
-
Longest Common Subsequence (LCS):最长公共子序列算法,通过计算两个字符串的最长公共子序列长度来衡量相似度,适用于需要捕捉字符串部分匹配的场景。
在Go语言中,你可以使用现有的库(如github.com/agonopole/go-stringdistance)来实现这些算法,也可以自行编写代码来实现特定需求。选择哪种算法取决于你的具体应用场景和数据特点。
综上所述,Go语言为计算字符串相似度提供了丰富的工具和算法,通过后端集成多种算法,可以灵活应对各种文本处理需求。