



🔥 掘金小册爬虫(使用Nodejs实现)
🔥 掘金小册爬虫(使用Nodejs实现)

采用 node https 模块,获取已购买小册 html 代码,并将 html 代码转换为 markdown 格式文件保存本地。
注意:目前本项目有两个版本,v2 不需要使用 chromium 作为无头浏览器; v1 则使用 chromi 作为无头浏览器模拟用户登录网站;
根据需要选择不同版本
- v2:
- v1 不再维护:
使用方法
⚠️ 注意:掘金不支持境外网络访问,因此不要使用代理
方法一:npx 直接执行
在本地某目录中执行 npx [@oliyg](/user/oliyg)/juejinxiaoce 按照提示输入用户名密码以及小册 ID 当提示 all done 完成
➜ Desktop npx [@oliyg](/user/oliyg)/juejinxiaoce
npx: 98 安装成功,用时 10.748 秒
email: 输入你的用户名密码
password: 输入你的用户名密码
bookId: 小册 ID
===navagating to main page
===login...
===getting book section list
===getting book HTML content
面试常用技巧
===writing html...
===getting book HTML content
===write html file success
===writing markdown...
===write markdown file success
前方的路,让我们结伴同行
===writing html...
===write html file success
===writing markdown...
===write markdown file success
======
All Done…Enjoy.
在执行命令的这个目录中可以找到一个名为 md xxx 的文件夹,内包含 md 文档;在上面这个例子中,我们在 Desktop 桌面目录执行命令,因此在桌面目录中会生成这个文件夹:
➜ md 1548483715543 ls -al
total 40
drwxr-xr-x 4 oli staff 128 1 26 14:22 .
drwx------+ 9 oli staff 288 1 26 14:21 ..
-rw-r--r-- 1 oli staff 4915 1 26 14:21 面试常用技巧.md
-rw-r--r-- 1 oli staff 8465 1 26 14:22 前方的路,让我们结伴同行.md
方法二:npm i 命令
使用 npm i -g 安装,并使用 juejinxiaoce 命令执行:
➜ Desktop npm i -g [@oliyg](/user/oliyg)/juejinxiaoce
/Users/oli/.nvm/versions/node/v8.12.0/bin/juejinxiaoce -> /Users/oli/.nvm/versions/node/v8.12.0/lib/node_modules/[@oliyg](/user/oliyg)/juejinxiaoce/bin/juejinxiaoce
+ [@oliyg](/user/oliyg)/[email protected]
added 98 packages from 201 contributors in 5.89s
➜ Desktop juejinxiaoce
email:
password:
bookId:
===navagating to main page
===login...
...
...
小册 ID 见 URL 链接:
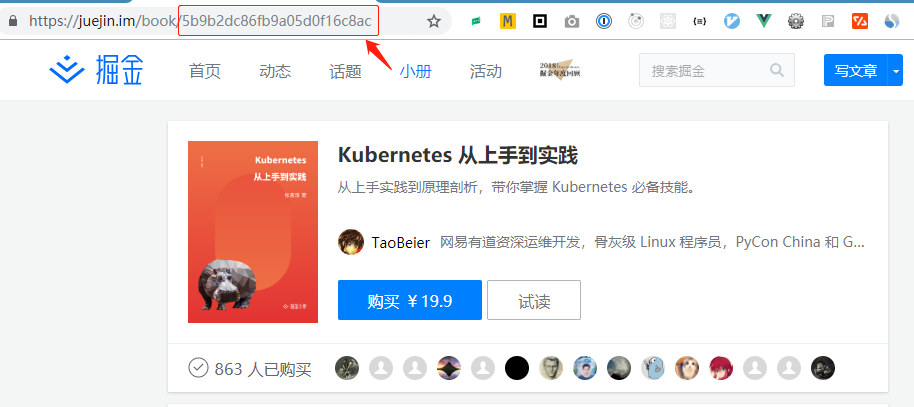
执行后等待出现消息 all done. enjoy. 完成转换,效果如下:
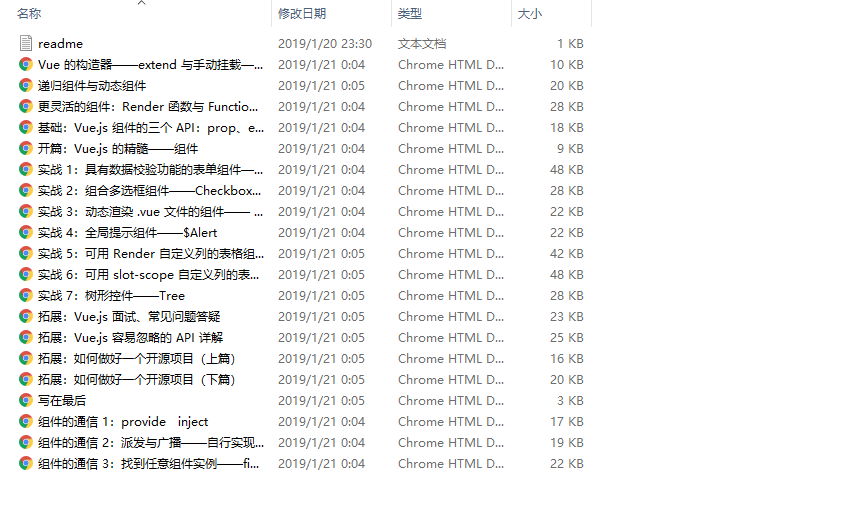
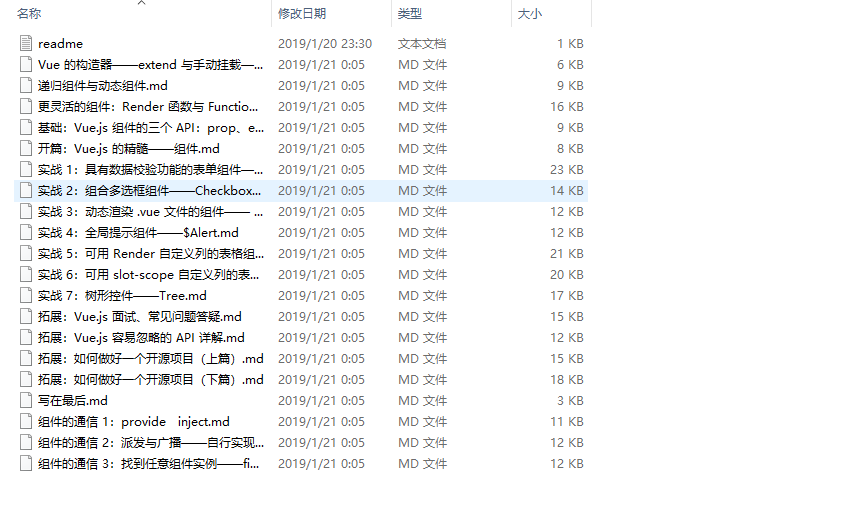
更新日志
- v2.2.0 增加命令行模式
- v2.0.0 使用 node 原生 https 模块,发送请求数据获取内容,不需要安装 chromium,没有软件权限问题
- v1.1.2 使用谷歌 puppeteer 作为无头浏览器获取内容,需要安装 chromium,macOS 中可能有权限问题
常见问题
- v1.1.2
- 报错:spawn EACCES
- 常见于 macOS,请保证 chromium 已被正常安装
- 报错:spawn EACCES
免责
- 不提供用户名和密码,需使用用户自己的账号密码登录
- 仅作为技术讨论,学习和研究使用
隐私
- 该项目不会存储和发送任何用户隐私数据
License
The MIT License (MIT) Copyright (c) 2019 OliverYoung
Permission is hereby granted, free of charge, to any person obtaining a copy of this software and associated documentation files (the "Software"), to deal in the Software without restriction, including without limitation the rights to use, copy, modify, merge, publish, distribute, sublicense, and/or sell copies of the Software, and to permit persons to whom the Software is furnished to do so, subject to the following conditions:
The above copyright notice and this permission notice shall be included in all copies or substantial portions of the Software.
THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE.

针对您提到的掘金小册爬虫项目,使用Node.js实现一个基本的爬虫可以遵循以下步骤。由于直接抓取网站内容可能涉及法律问题和网站的使用条款,请确保您有权访问并处理目标网站的数据。
以下是一个简单的Node.js爬虫示例,使用axios库来发起HTTP请求,cheerio库来解析HTML:
- 首先,安装必要的库:
npm install axios cheerio
- 创建一个JavaScript文件(如
crawler.js),并编写以下代码:
const axios = require('axios');
const cheerio = require('cheerio');
async function fetchData(url) {
try {
const { data } = await axios.get(url);
const $ = cheerio.load(data);
// 示例:抓取所有文章标题
const titles = $('.article-title').map((i, el) => $(el).text()).get();
console.log(titles);
} catch (error) {
console.error('Error fetching data:', error);
}
}
// 替换为掘金小册的实际URL
fetchData('https://juejin.cn/bookshelf');
- 运行爬虫:
node crawler.js
此代码会抓取指定页面上的所有文章标题。请注意,这只是一个基础示例,实际项目中可能需要处理更多细节,如分页、反爬虫机制、数据存储等。同时,务必遵守目标网站的使用条款和法律法规。