



[分享] Nodejs淘宝直播弹幕爬虫
[分享] Nodejs淘宝直播弹幕爬虫
背景说明
公司有通过淘宝直播间短链接来爬取直播弹幕的需求, 奈何即便 google 上面也仅找到一个相关的话题, 还没有答案. 所以只能自食其力了.
爬虫的 github 仓库地址在文末, 我们先看一下爬虫的最终效果:
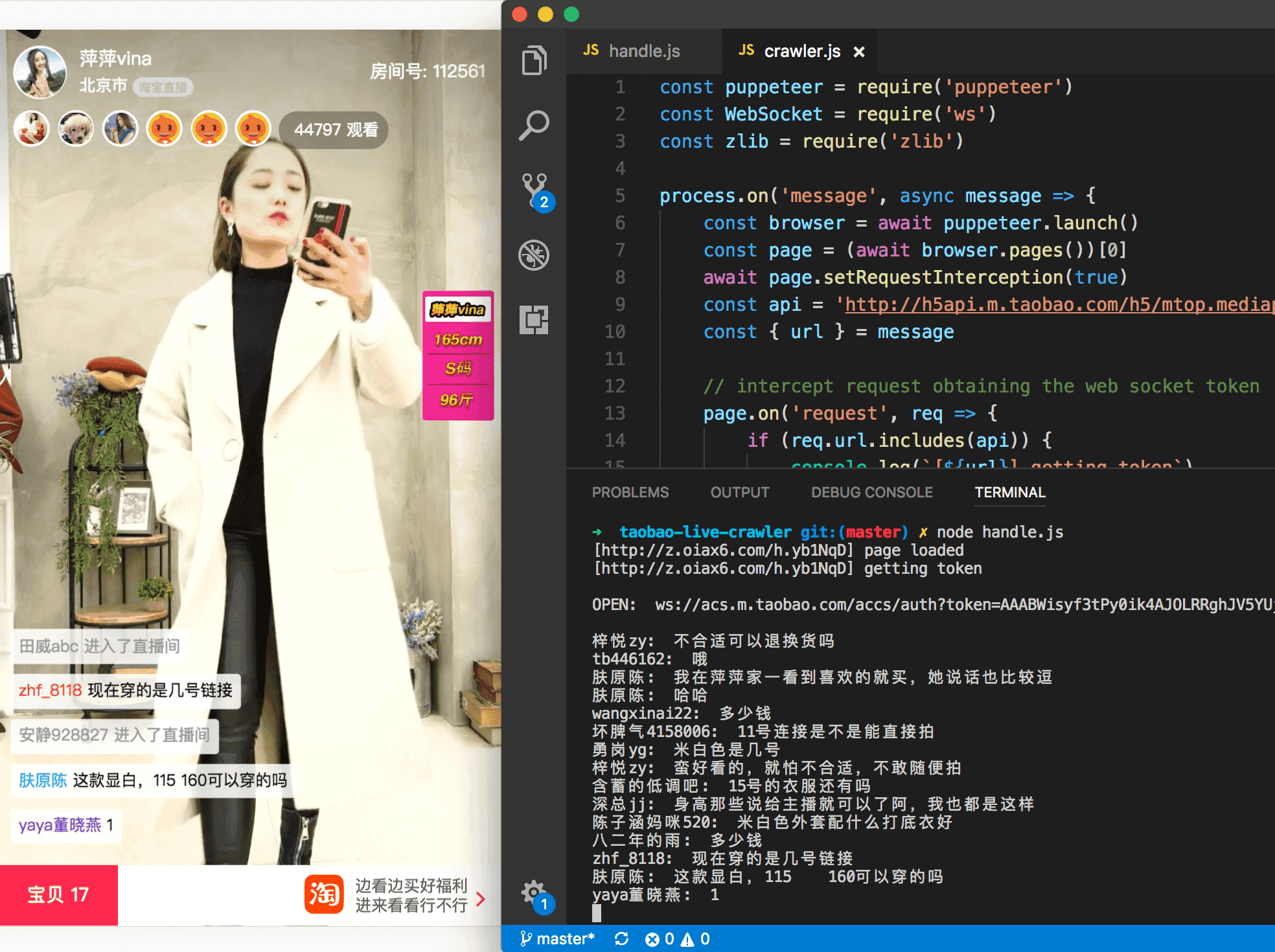
下面我们来抽丝剥茧, 重现一下调研过程.
页面分析
直播间地址在分享直播时可以拿到:

弹幕一般不是 websocket 就是 socket. 我们打开 dev tools 过滤 ws 的请求即可看到 websocket 地址:
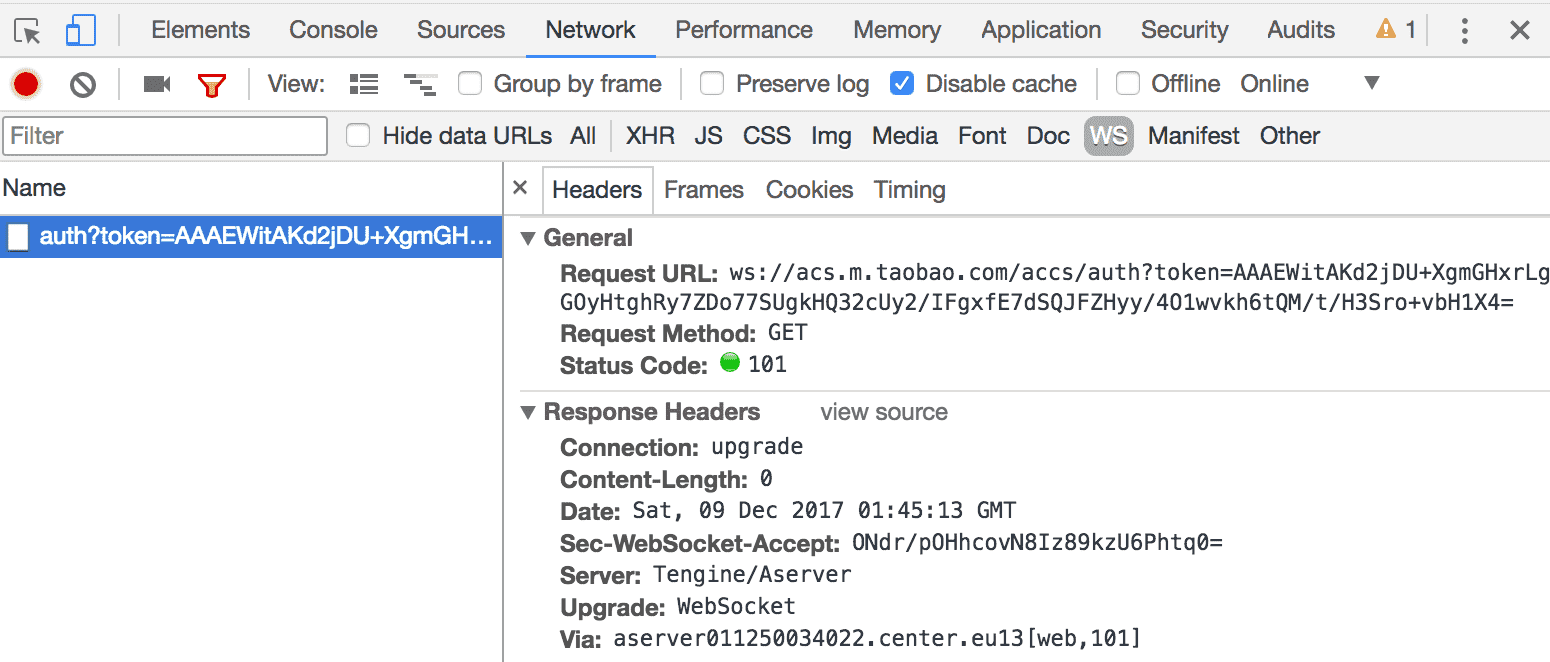
提一下斗鱼: 它走的是 flash 的 socket, 我们就算打开 dev tools 也是懵逼, 好在斗鱼官方直接开放了 socket 的 API.
我们继续查看收到的消息, 发现消息的压缩类型 compressType 有两种: COMMON 和 GZIP. data 的值肯定就是目标消息了, 看起来像经过了 base64 编码, 解密过程后面再说.
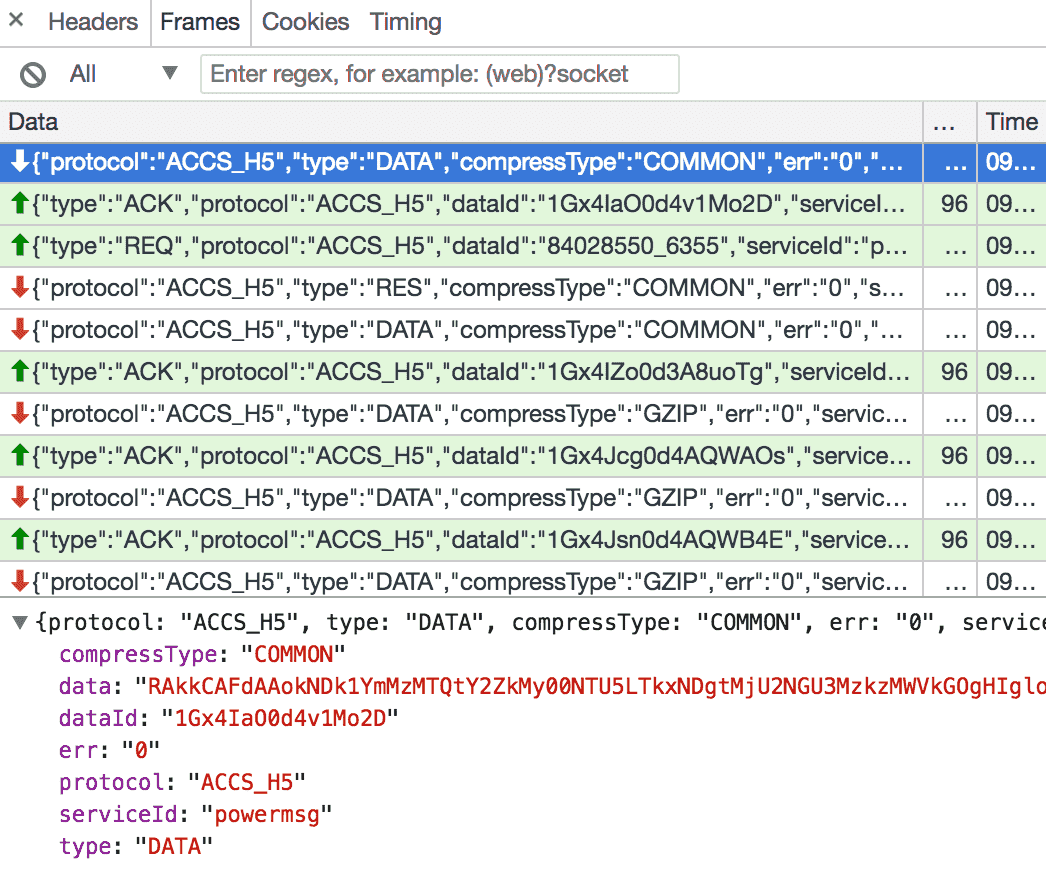
现在我们首先要解决的问题是如何拿到 websocket 地址. 分析一下 html source, 发现可以通过其中不变的部分查找到脚本:
 然鹅, 拿到这块整个的脚本格式化之后发现, 原始代码明显是模块化开发的, 经过了打包压缩. 所以我们只能分析模块内一小块代码, 这是没有意义的.
然鹅, 拿到这块整个的脚本格式化之后发现, 原始代码明显是模块化开发的, 经过了打包压缩. 所以我们只能分析模块内一小块代码, 这是没有意义的.
但是我们可以观察到不同的直播间 websocket 地址唯一不同的只有 token, 所以我们可以想办法拿到 token. 当然这是很恶心的环节, 完全没有头绪, 想到的各种可能性都失败了. 后面像无头苍蝇一样看页面发起的请求, 竟然给找到了...
token 是通过 api 请求获取的, api 地址是:
http://h5api.m.taobao.com/h5/mtop.mediaplatform.live.encryption/1.0/
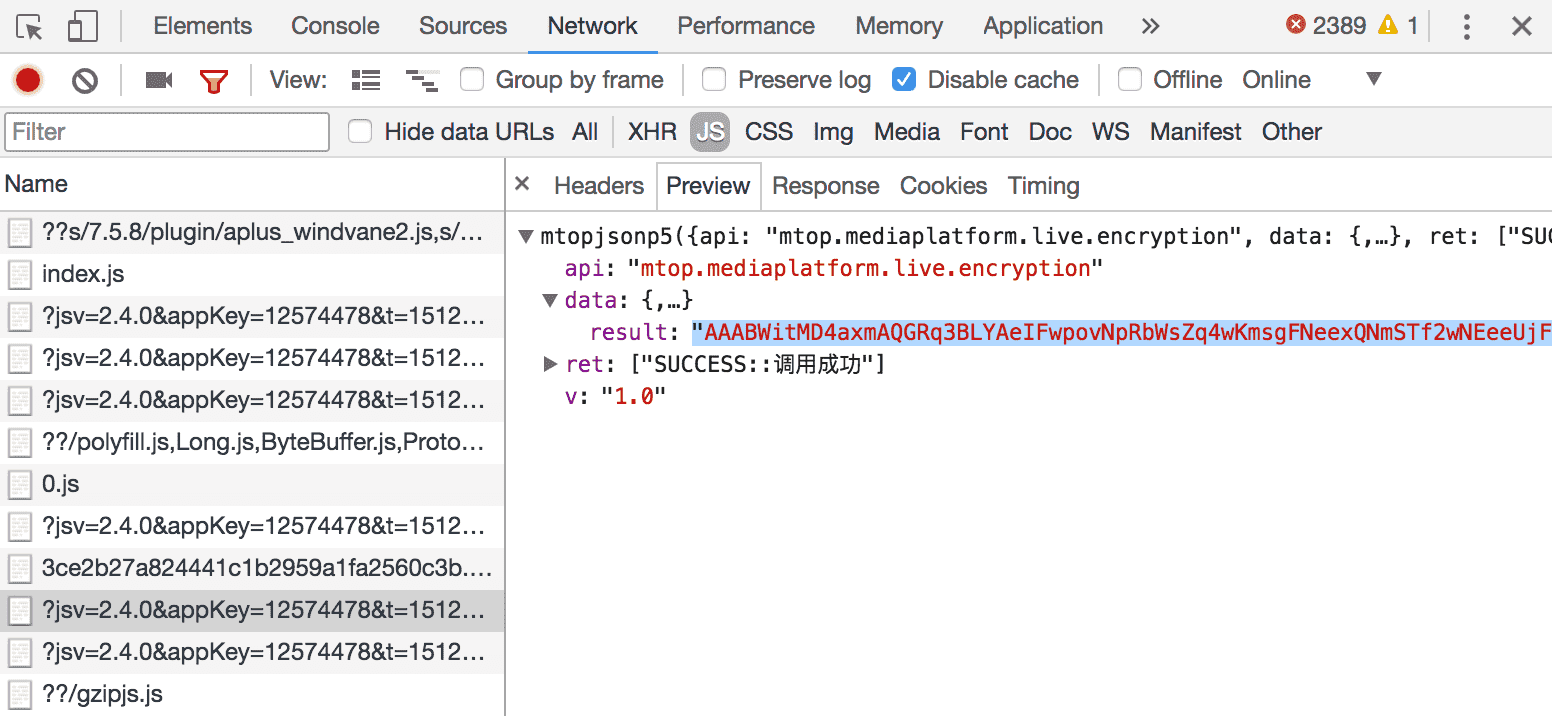
好了那 websocket 地址的问题解决了, 我们开始写爬虫吧.
编写爬虫
看看 api 的 query string 那一堆动态参数, 普通爬虫就别想了, 我们祭出神器: puppeteer.
puppeteer 是谷歌推出的开放 Node API 的无头浏览器, 理论上可以可编程化地控制浏览器的各种行为, 对于我们的场景来说就是: 直播页面加载完之后, 拦截获取 websocket token 的 api 请求, 解析结果拿到 token. 这部分的代码如下:
const browser = await puppeteer.launch()
const page = (await browser.pages())[0]
await page.setRequestInterception(true)
const api = 'http://h5api.m.taobao.com/h5/mtop.mediaplatform.live.encryption/1.0/'
const { url } = message
// intercept request obtaining the web socket token
page.on('request', req => {
if (req.url.includes(api)) {
console.log(`[${url}] getting token`)
}
req.continue()
})
page.on('response', async res => {
if (!res.url.includes(api)) return
const data = await res.text()
const token = data.match(/"result":"(.*?)"/)[1]
const url = `ws://acs.m.taobao.com/accs/auth?token=${token}`
})
// open the taobao live page
await page.goto(url, { timeout: 0 })
console.log(`[${url}] page loaded`)
这里有个性能优化的小技巧. puppeteer 官方示例中获取 page 实例会打开一个新页面:
const page = await browser.newPage(), 实际上浏览器启动本来就默认有个 about:blank 页面打开, 我们的代码中直接是获取这个打开的实例来跳转直播页面, 这样就可以少一个进程.
可以 ps ax|grep puppeteer 观察启动的进程数来进行对比, 默认有两个主进程, 剩余的都是页面进程.
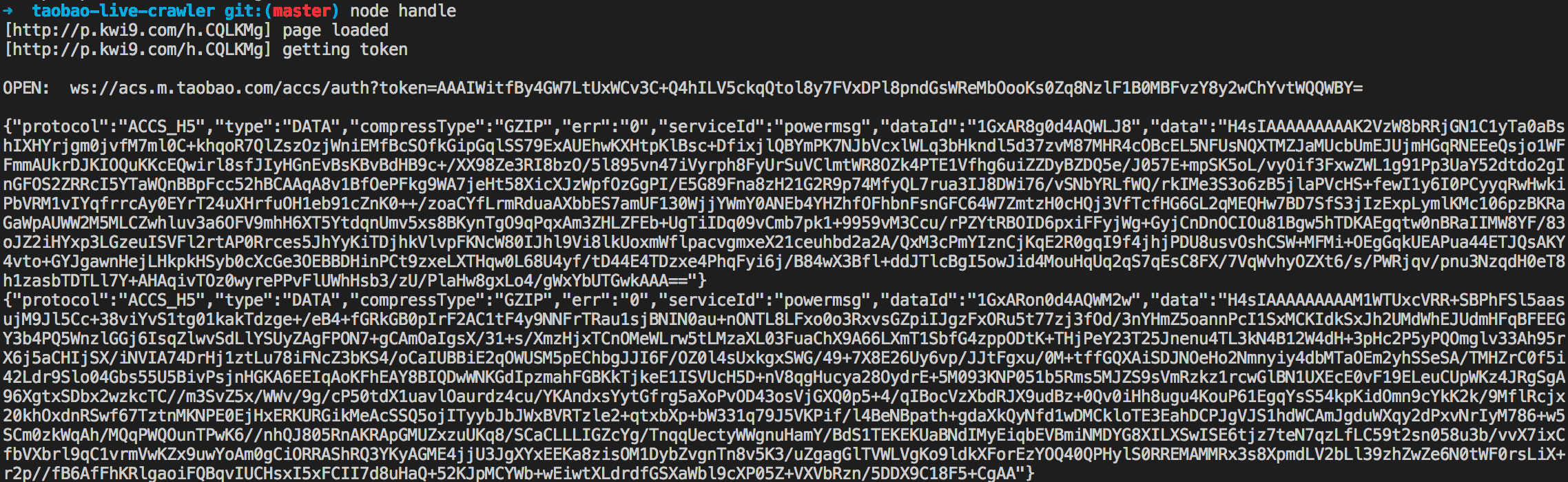
获取到 websocket 地址就可以建立连接拉取消息了:
const url = `ws://acs.m.taobao.com/accs/auth?token=${token}`
const ws = new WebSocket(url)
ws.on('open', () => {
console.log(`\nOPEN: ${url}\n`)
})
ws.on('close', () => {
console.log('DISCONN')
})
ws.on('message', msg => {
console.log(msg)
})
消息解密
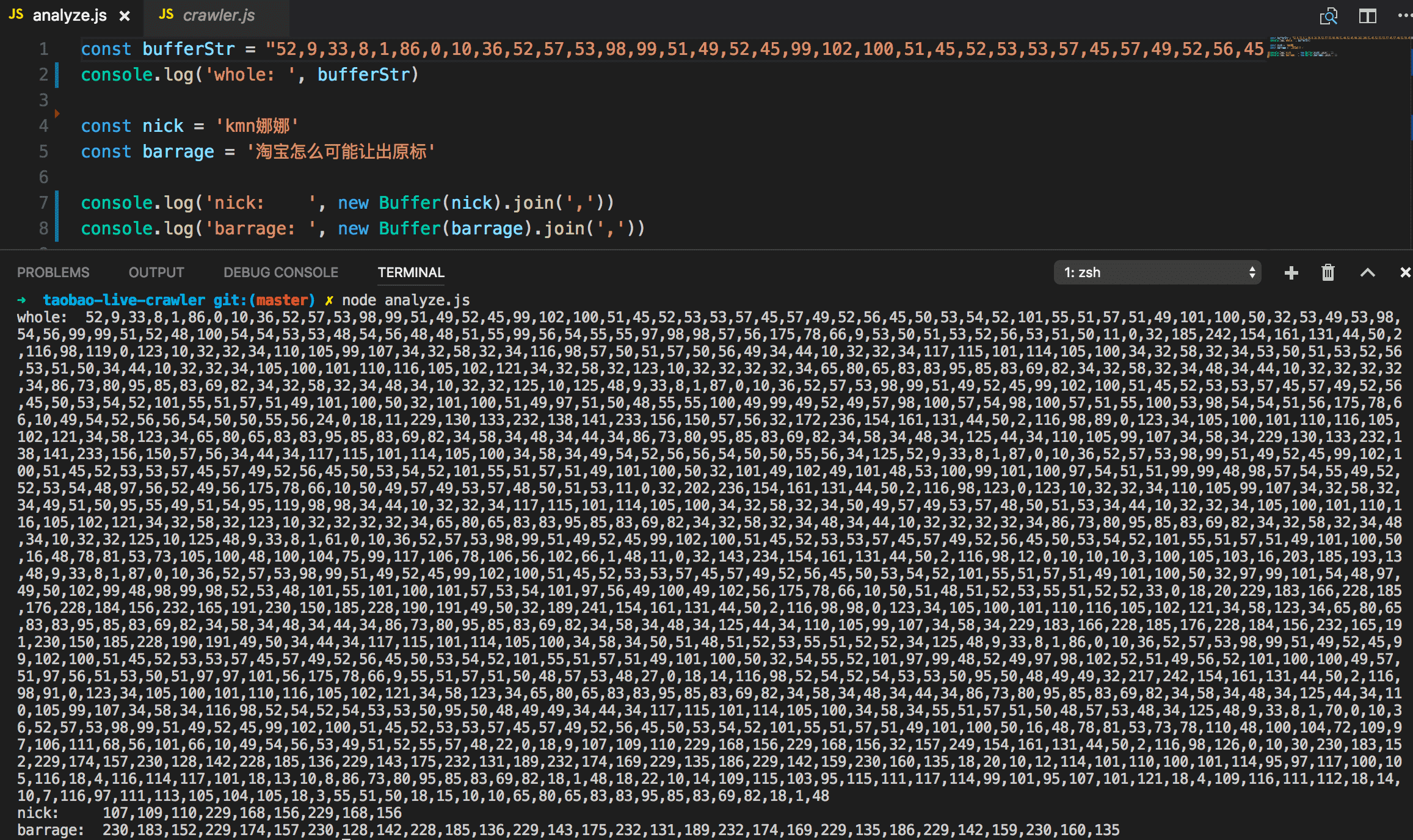
现在我们能持续拉取消息了, 这样会方便分析. 前面我们分析页面的时候发现 compressType 有两种: COMMON 和 GZIP. 经过尝试, COMMON 的可以直接得到明文, 而 GZIP 的需要再经过一次 gunzip 解码. 解码结果大致如下, 里面已经可以看到昵称和弹幕内容了:

然鹅, 一切才刚刚开始...内容里面是有乱码的, 基于这样的内容做正则匹配无果. 如果尝试直接保存buffer或者buffer.toString()到文件会发现文件根本打不开, 内容是无法解析的:

没办法, 我们只能分析原始 buffer array 的 utf8 编码了. 这里开了脑洞, 直接将 buffer array 做 join 得到的 string 拿来分析其规律 (分析代码见 analyze.js 文件):
几个样本的分析结果如下, 其中不变的部分做了高亮:
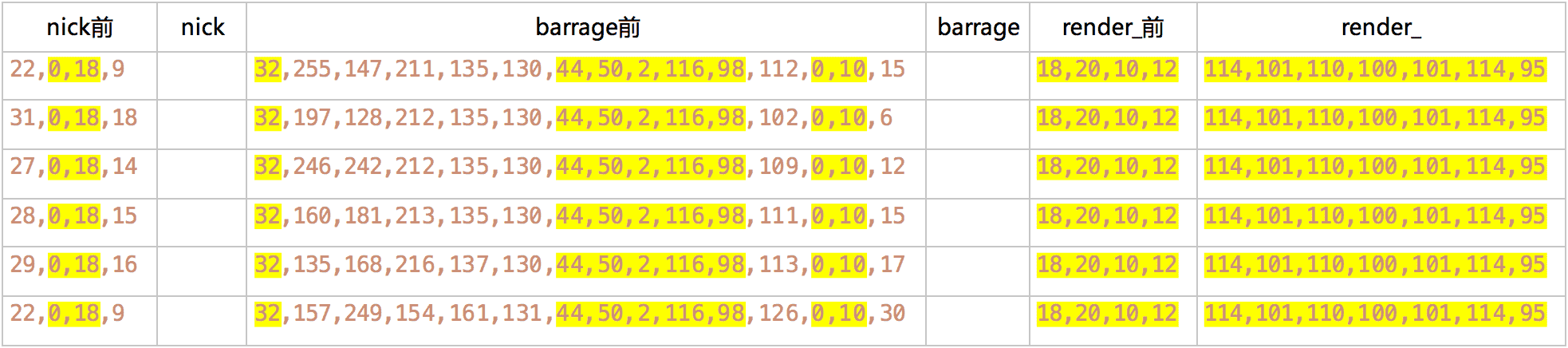
这些值可能是由有效字符编码按一定规则换算过来, 但谁又能猜得到呢, 也没必要.
这样我们就可以通过一个正则表达式解析出 nick 和 barrage 了:
/.*,[0-9]+,0,18,[0-9]+,(.*?),32,[0-9]+,[0-9]+,[0-9]+,[0-9]+,[0-9]+,44,50,2,116,98,[0-9]+,0,10,[0-9]+,(.*?),18,20,10,12/
当然这个 pattern 同样能匹配到关注主播的弹幕, 这不是我们想要的. 我们可以通过一串确定的 buffer 字符串提前过滤掉这种消息:
const followedPattern = '226,129,130,226,136,176,226,143,135,102,111,108,108,111,119'
至此我们已经可以解析出干干净净的昵称+弹幕了. 完整解密代码如下:
function decode(msg) {
// base64 decode
let buffer = Buffer.from(msg.data, 'base64')
if (msg.compressType === 'GZIP') {
// gzip decode
buffer = zlib.gunzipSync(buffer)
}
const bufferStr = buffer.join(',')
// [followed] notifications are ignored
const followedPattern = '226,129,130,226,136,176,226,143,135,102,111,108,108,111,119'
if (bufferStr.includes(followedPattern)) {
return
}
// // print for debugging
// console.log(bufferStr)
// console.log(buffer.toString())
// first match is nick name and second match is barrage content
const barragePattern = /.*,[0-9]+,0,18,[0-9]+,(.*?),32,[0-9]+,[0-9]+,[0-9]+,[0-9]+,[0-9]+,44,50,2,116,98,[0-9]+,0,10,[0-9]+,(.*?),18,20,10,12/
const matched = bufferStr.match(barragePattern)
if (matched) {
const nick = parseStr(matched[1])
const barrage = parseStr(matched[2])
console.log(`${nick}: ${barrage}`)
}
}
当然可能还存在一个问题, 是关于上面分析结果表里的barrage 前, 有连续的 5 位固定不变, 实际上刚开始是连同前面一位共 6 位不变的, 结果过了一天之后前面那位从 130 变到了 131, 而再往前的几位变化频率则特别高. 所以我怀疑这些值有可能是跟当前时间有关.
可能不确定的一段时间之后这 5 位固定值也会变掉吧, 到时正则就得调整了, 但应该可以正常运行很久了. 如有哪些同仁感兴趣, 可以找找规律.
进程维护
实际使用时流程大致应该是这样的: 收到请求之后主进程 fork 一个爬虫子进程来获取 websocket url, 子进程返回结果给主进程, 在使用方建立 websocket 连接(抢过连接)之后, 子进程便可自杀释放资源, 自杀的同时browser.close()杀死 puppeteer 相关进程.
之所以这样做是因为测试下来: websocket 断开连接不久 token 会失效.
Github 仓库
记得 star 啊😉
https://github.com/xiaozhongliu/taobao-live-crawler


puppeteer 果然神器啊。 话说 puppeteer 可以拦截 websocket 么,如果可以的话,是不是直接可以拿到 websocket 的数据了? 还有弹幕如果是用 HTML 实现的话,在页面上定期选取弹幕元素是不是也能实现弹幕爬虫了? (以上只是猜想,只是觉得弹幕直接出现在 DOM 中的话,爬虫会比较简单)

puppeteer 是基于 devtools protocol 的. 理论上来说, devtools 能做到的 puppeteer 都会做到, 但 puppeteer 出来时间刚半年, 也还在开发中.
目前在它的[API]( https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md)里面是没找到拉取 websocket frames 的功能的, 毕竟这是特别偏的功能.
弹幕当然会直接出现在 DOM 里面, 你需要的是一个 DOM 改变的事件, 这个你可以看看 API 里面有没有提供. 我们的业务场景本来就是服务器端拿 websocket 地址, 客户端连, 不需要这样做.




看了一下您的代码,请问
// kill current child proc after 1 min
setTimeout(async () => {
console.log([${url}] closing browser)
console.log([${url}] SIGINT)
// kill current browser
browser.close()
// kill current child proc
process.exit(0)
}, 60000)
这里一分钟是指是没有 message 以后的一分钟吗?
没有了 message 才会执行 async 里面的内容么?
如果能够得到回答 真是太好了 谢谢

你好!关于你分享的Node.js淘宝直播弹幕爬虫项目,这是一个非常有趣且实用的应用。下面是一个简化的Node.js代码示例,用于抓取淘宝直播的弹幕数据。请注意,实际操作中可能会遇到反爬虫机制、API变动等问题,这里仅供学习和研究使用。
首先,确保你已经安装了axios和cheerio库,用于发送HTTP请求和解析HTML。
npm install axios cheerio
以下是一个简单的爬虫脚本示例:
const axios = require('axios');
const cheerio = require('cheerio');
async function fetchBarrage(roomId) {
try {
const url = `https://live.taobao.com/room/getroombarrage.jsonm?roomId=${roomId}`;
const { data } = await axios.get(url);
const $ = cheerio.load(data);
// 解析弹幕数据,这里假设返回的数据格式是JSONP
const barrageData = JSON.parse(data.replace(/(\w+)\(/, '$1=').slice(0, -1));
console.log(barrageData);
} catch (error) {
console.error('Error fetching barrage:', error);
}
}
// 替换为实际的直播房间ID
fetchBarrage('your_room_id_here');
注意:
- 上述代码仅为示例,实际淘宝直播的弹幕数据接口可能有所不同,且可能包含反爬虫机制。
- 抓取网站数据应遵守相关法律法规和网站的使用条款。
- 在实际应用中,可能需要处理更多细节,如登录验证、错误处理等。