



HarmonyOS 鸿蒙Next NativeBuffer申请DMA buffer在CPU端性能非常慢
HarmonyOS 鸿蒙Next NativeBuffer申请DMA buffer在CPU端性能非常慢
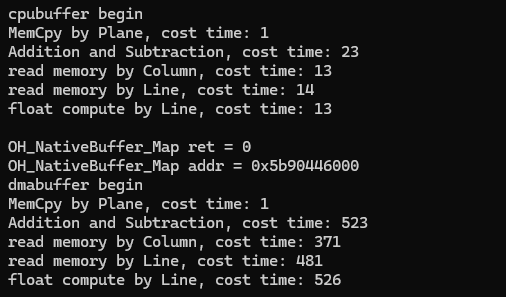
NativeBuffer在CPU端操作对比直接malloc出来的Buffer慢了几十倍。
#include <stdio.h>
#include <dlfcn.h>
#include <string.h>
#include <errno.h>
#include <sys/time.h>
#include <unistd.h>
#include <sys/mman.h>
#include <iostream>
#include <fstream>
#include <pthread.h>
#include <fcntl.h>
#include "native_buffer.h"
typedef struct __tag_ImageData
{
int i32Width;
int i32Height;
unsigned char* ppu8Plane[2];
int pi32Pitch[2];
} ImageData;
long now_ms(void) {
struct timeval res;
gettimeofday(&res, NULL);
return (long)(res.tv_sec * 1000 + res.tv_usec / 1000);
}
void test(ImageData *pImgSrc, ImageData *pImgDst, std::ofstream& outfile, std::string type) {
outfile << type << "buffer begin" << std::endl;
long lBeginTime;
long lPerformenceTime;
unsigned char* pSrcY, *pSrcVU;
unsigned char* pDstY, *pDstVU;
pDstY = pImgDst->ppu8Plane[0];
pSrcY = pImgSrc->ppu8Plane[0];
pDstVU = pImgDst->ppu8Plane[1];
pSrcVU = pImgSrc->ppu8Plane[1];
int i=0, j=0, k=0;
int lYSize = pImgSrc->pi32Pitch[0] * pImgSrc->i32Height;
int lVUSize = pImgSrc->pi32Pitch[1] * (pImgSrc->i32Height>>1);
lBeginTime = now_ms();
pDstY = pImgDst->ppu8Plane[0];
pSrcY = pImgSrc->ppu8Plane[0];
pDstVU = pImgDst->ppu8Plane[1];
pSrcVU = pImgSrc->ppu8Plane[1];
memcpy(pDstY, pSrcY, lYSize);
memcpy(pDstVU, pSrcVU, lVUSize);
lPerformenceTime = now_ms() - lBeginTime;
outfile << "MemCpy by Plane, cost time: " << lPerformenceTime << std::endl;
//按列读取,做加减运算+-
lBeginTime = now_ms();
#define LIMIT(x) (x>255?x=255:x)
int nY, nVU;
unsigned char* pNV12Y = pImgDst->ppu8Plane[0];
unsigned char* pNV12VU = pImgDst->ppu8Plane[1];
for (i = 0; i<pImgSrc->pi32Pitch[0]; i++) {
for (j = 0; j < pImgSrc->i32Height; j++) {
k = i + j * pImgSrc->pi32Pitch[0];
nY = pNV12Y[k];
pNV12Y[k] = nY + (nY>>1) - (nY>>3);
LIMIT(pNV12Y[k]);
}
}
for (i = 0; i < pImgSrc->pi32Pitch[1]; i++) {
for (j = 0; j < (pImgSrc->i32Height >> 1); j++) {
k = i + j * pImgSrc->pi32Pitch[1];
nVU = pNV12VU[k];
pNV12VU[k] = nVU + (nVU >> 1) - (nVU >> 3);
LIMIT(pNV12VU[k]);
}
}
lPerformenceTime = now_ms() - lBeginTime;
outfile << "Addition and Subtraction, cost time: " << lPerformenceTime << std::endl;
//按列读取
lBeginTime = now_ms();
pNV12Y = pImgDst->ppu8Plane[0];
pNV12VU = pImgDst->ppu8Plane[1];
for (i=0; i<pImgSrc->pi32Pitch[0]; i++) {
for (j = 0; j < pImgSrc->i32Height; j++) {
k = i + j * pImgSrc->pi32Pitch[0];
nY = pNV12Y[k];
pNV12Y[k] = 128;
}
}
for (i=0; i < pImgSrc->pi32Pitch[1]; i++) {
for (j = 0; j < (pImgSrc->i32Height >> 1); j++) {
k = i + j * pImgSrc->pi32Pitch[1];
nVU = pNV12VU[k];
pNV12VU[k] = 128;
}
}
lPerformenceTime = now_ms() - lBeginTime;
outfile << "read memory by Column, cost time: " << lPerformenceTime << std::endl;
//按行读取
lBeginTime = now_ms();
pNV12Y = pImgDst->ppu8Plane[0];
pNV12VU = pImgDst->ppu8Plane[1];
for (i=0; i<pImgSrc->i32Height; i++) {
for (j=0; j < pImgSrc->pi32Pitch[0]; j++) {
k = j + i * pImgSrc->pi32Pitch[0];
nY = pNV12Y[k];
pNV12Y[k] = 205;
}
}
for (i = 0; i < (pImgSrc->i32Height >> 1); i++) {
for (j=0; j<pImgSrc->pi32Pitch[1]; j++) {
k = j + i * pImgSrc->pi32Pitch[1];
nVU = pNV12VU[k];
pNV12VU[k] = 85;
}
}
lPerformenceTime = now_ms() - lBeginTime;
outfile << "read memory by Line, cost time: " << lPerformenceTime << std::endl;
//浮点运算(2加法+2乘法)
lBeginTime = now_ms();
pNV12Y = pImgDst->ppu8Plane[0];
pNV12VU = pImgDst->ppu8Plane[1];
for (i = 0; i<pImgSrc->i32Height; i++) {
for (j = 0; j<pImgSrc->pi32Pitch[0]; j++) {
k = j + i * pImgSrc->pi32Pitch[0];
nY = pNV12Y[k];
pNV12Y[k] = (float)nY * 0.1+(nY + 1.2) * 2.0;
}
}
for (i = 0; i < (pImgSrc->i32Height >> 1); i++) {
for (j = 0; j < pImgSrc->pi32Pitch[1]; j++) {
k = j + i * pImgSrc->pi32Pitch[1];
nVU = pNV12VU[k];
pNV12VU[k] = (float)nVU * 0.1+(nVU + 1.2) * 2.0;
}
}
lPerformenceTime = now_ms() - lBeginTime;
outfile << "float compute by Line, cost time: " << lPerformenceTime << std::endl;
outfile << std::endl;
}
int main(int argc,const char **argv)
{
std::ofstream outfile;
outfile.open("/data/1/file.txt", std::ios::app);
ImageData imgSrc = {0};
imgSrc.i32Width = 1440;
imgSrc.i32Height = 1080;
imgSrc.pi32Pitch[0] = 1440;
imgSrc.pi32Pitch[1] = 1440;
imgSrc.ppu8Plane[0] = (unsigned char *)malloc(imgSrc.pi32Pitch[0] * imgSrc.i32Height * 3 / 2);
imgSrc.ppu8Plane[1] = imgSrc.ppu8Plane[0] + imgSrc.pi32Pitch[0] * imgSrc.i32Height;
ImageData imgDst = {0};
imgDst.i32Width = 1440;
imgDst.i32Height = 1080;
imgDst.pi32Pitch[0] = 1440;
imgDst.pi32Pitch[1] = 1440;
imgDst.ppu8Plane[0] = (unsigned char *)malloc(imgDst.pi32Pitch[0] * imgDst.i32Height * 3 / 2);
imgDst.ppu8Plane[1] = imgDst.ppu8Plane[0] + imgDst.pi32Pitch[0] * imgDst.i32Height;
FILE* fp = fopen("/data/1/1440x1080.nv12", "rb");
if (fp) {
fread(imgSrc.ppu8Plane[0], 1, 1440 * 1080 * 3 / 2, fp);
fclose(fp);
} else {
printf("load image failed!");
return -1;
}
test(&imgSrc, &imgDst, outfile, "cpu");
free(imgDst.ppu8Plane[0]);
OH_NativeBuffer_Config config;
config.width = imgSrc.i32Width;
config.height = imgSrc.i32Height;
config.format = NATIVEBUFFER_PIXEL_FMT_YCRCB_420_SP;
config.usage = NATIVEBUFFER_USAGE_CPU_READ | NATIVEBUFFER_USAGE_CPU_WRITE | NATIVEBUFFER_USAGE_MEM_DMA | NATIVEBUFFER_USAGE_CPU_READ_OFTEN;
config.stride = imgSrc.i32Width * imgSrc.i32Height * 3/ 2;
OH_NativeBuffer* nativeBuffer = OH_NativeBuffer_Alloc(&config);
if (nativeBuffer == NULL) {
outfile << "OH_NativeBuffer addr = " << nativeBuffer << std::endl;
outfile.close();
return - 1;
}
void *addr = NULL;
int ret = OH_NativeBuffer_Map(nativeBuffer, &addr);
outfile << "OH_NativeBuffer_Map ret = " << ret << std::endl;
outfile << "OH_NativeBuffer_Map addr = " << addr << std::endl;
if (addr == NULL || ret != 0) {
outfile.close();
return -1;
}
imgDst.ppu8Plane[0] = (unsigned char *)addr;
imgDst.ppu8Plane[1] = imgDst.ppu8Plane[0] + imgDst.pi32Pitch[0] * imgDst.i32Height;
test(&imgSrc, &imgDst, outfile, "dma");
OH_NativeBuffer_Unmap(nativeBuffer);
OH_NativeBuffer_Unreference(nativeBuffer);
outfile.close();
free(imgSrc.ppu8Plane[0]);
return 0;
}
更多关于HarmonyOS 鸿蒙Next NativeBuffer申请DMA buffer在CPU端性能非常慢的实战教程也可以访问 https://www.itying.com/category-93-b0.html

更多关于HarmonyOS 鸿蒙Next NativeBuffer申请DMA buffer在CPU端性能非常慢的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html

在HarmonyOS鸿蒙系统中,Next NativeBuffer申请DMA buffer在CPU端性能缓慢的问题,通常与DMA buffer的管理和分配机制有关。HarmonyOS对DMA buffer的管理设计旨在优化系统资源利用和安全性,但特定场景下可能会引入性能开销。
性能缓慢可能由以下几个因素导致:
-
资源竞争:多个进程或线程同时申请DMA buffer时,系统资源竞争可能导致申请过程延迟。
-
内存分配策略:DMA buffer通常要求物理连续内存,这可能导致系统需要更多时间来找到合适的内存块。
-
驱动层开销:DMA buffer的申请和映射过程涉及与硬件驱动的交互,驱动层的处理效率也会影响整体性能。
-
系统负载:系统当前负载较高时,处理DMA buffer申请的响应时间也会相应增加。
针对此问题,可以尝试优化应用层面的内存使用策略,减少不必要的DMA buffer申请,或者调整申请时机以避开系统高峰期。同时,确保系统驱动和固件均为最新版本,以获得最佳性能和兼容性。
如果问题依旧没法解决请联系官网客服,官网地址是:https://www.itying.com/category-93-b0.html