




Nodejs豆瓣爬虫
Nodejs豆瓣爬虫
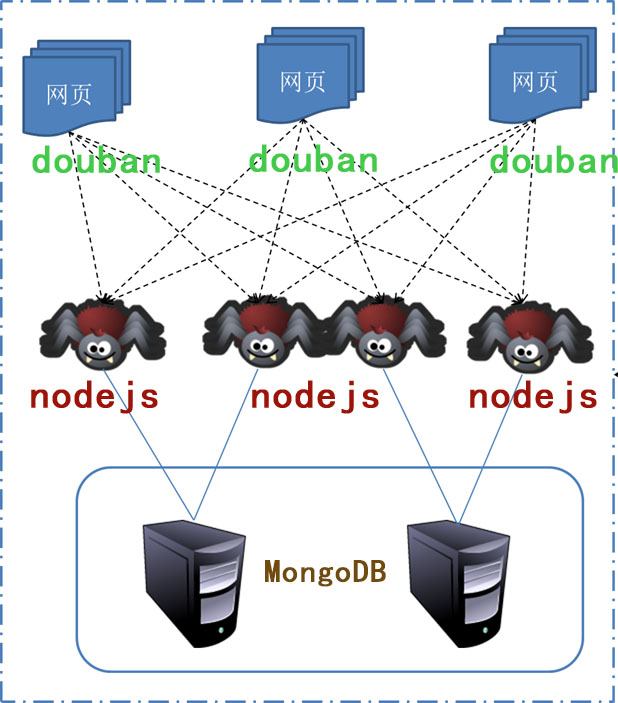
从零开始nodejs系列文章,将介绍如何利Javascript做为服务端脚本,通过Nodejs框架web开发。Nodejs框架是基于V8的引擎,是目前速度最快的Javascript引擎。chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的web开发框架Express,可以帮助我们迅速建立web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站,个性化网站,我们自己的Geek网站!!
目录:
使用类库介绍 win7安装jquery – 失败 ubuntu安装jQuery – 成功 豆瓣爬虫

Nodejs豆瓣爬虫
从零开始Nodejs系列文章,将介绍如何利用JavaScript作为服务端脚本,通过Nodejs框架进行Web开发。Nodejs框架是基于V8的引擎,是目前速度最快的JavaScript引擎。Chrome浏览器就基于V8,同时打开20-30个网页都很流畅。Nodejs标准的Web开发框架Express,可以帮助我们迅速建立Web站点,比起PHP的开发效率更高,而且学习曲线更低。非常适合小型网站、个性化网站,以及我们自己的Geek网站。
目录:
- 使用类库介绍
- win7安装jQuery - 失败
- ubuntu安装jQuery - 成功
- 豆瓣爬虫
豆瓣爬虫
豆瓣是一个非常受欢迎的社交网络平台,提供了丰富的数据资源。本文将展示如何使用Node.js编写一个简单的豆瓣爬虫,抓取电影信息。
首先,我们需要安装一些必要的依赖包。这里我们将使用axios来发送HTTP请求,cheerio来解析HTML页面。
npm install axios cheerio
接下来,我们创建一个简单的爬虫程序来抓取豆瓣电影Top250的信息。
const axios = require('axios');
const cheerio = require('cheerio');
async function fetchMovieList() {
const url = 'https://movie.douban.com/top250';
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
// 选择器用于提取电影列表
const movieItems = $('.item');
movieItems.each((index, element) => {
const title = $(element).find('.title').text();
const ratingNum = $(element).find('.rating_num').text();
console.log(`电影名: ${title}, 评分: ${ratingNum}`);
});
} catch (error) {
console.error('请求失败:', error);
}
}
fetchMovieList();
上述代码中,我们首先使用axios发送HTTP GET请求到豆瓣电影Top250页面。然后,使用cheerio加载返回的HTML内容,并通过CSS选择器提取电影名称和评分信息。
注意:在实际应用中,频繁访问豆瓣可能会导致IP被封禁。因此,建议添加适当的延时或使用代理服务器来避免这种情况。
总结
通过上面的示例代码,我们可以看到使用Node.js进行简单的网页爬虫开发是非常方便的。通过引入合适的库,可以快速地实现数据抓取功能。当然,实际项目中可能还需要处理更多复杂的情况,比如登录验证、反爬虫策略等。希望这篇教程能帮助你入门Nodejs爬虫开发。
请查看博客文章以获取更多详细信息和源代码。






-
URL改个参数,就可以传各种URL了 http://movie.douban.com/subject/11529526/
-
解析网页与jquery
-
代理服务器,自动切换IP,是完善的事情不是础功能。
-
cookie,不需要登陆的网页,不用做cookie

爬豆瓣的话,其实用https://github.com/MatthewMueller/cheerio 更合适。。
感觉能用得上jsdom的地方,只有cheerio实在搞不定的情况下。。。

关于“Nodejs豆瓣爬虫”的帖子内容,我可以提供一个简单的示例来展示如何用Node.js抓取豆瓣的数据。这里我们将使用axios库来发送HTTP请求,并用cheerio库来解析HTML。
首先,你需要安装这两个库:
npm install axios cheerio
然后你可以创建一个简单的爬虫脚本,比如叫做doubanCrawler.js,用来抓取豆瓣电影页面的信息。下面是一个基本的例子:
const axios = require('axios');
const cheerio = require('cheerio');
async function fetchDoubanMovie(url) {
try {
const response = await axios.get(url);
const $ = cheerio.load(response.data);
const movieTitle = $('.title').text();
console.log(`电影名称: ${movieTitle}`);
} catch (error) {
console.error(`获取页面失败: ${error.message}`);
}
}
// 使用函数抓取指定URL的数据
fetchDoubanMovie('https://movie.douban.com/top250?start=0');
这段代码会抓取豆瓣电影Top 250页面中的第一个电影标题,并打印出来。
请注意,豆瓣和其他大型网站通常有反爬虫机制,频繁或大量请求可能会导致IP被封禁。因此,在实际应用中,建议增加延迟、处理cookies和headers等,以模拟正常用户行为,并且遵守网站的robots.txt规则。此外,如果你需要处理更复杂的数据或者进行更深入的分析,可能还需要学习更多关于数据处理、错误处理以及异步编程的知识。