




HarmonyOS 鸿蒙Next fs.readText()中的参数为何是字节数而不是字符数
HarmonyOS 鸿蒙Next fs.readText()中的参数为何是字节数而不是字符数
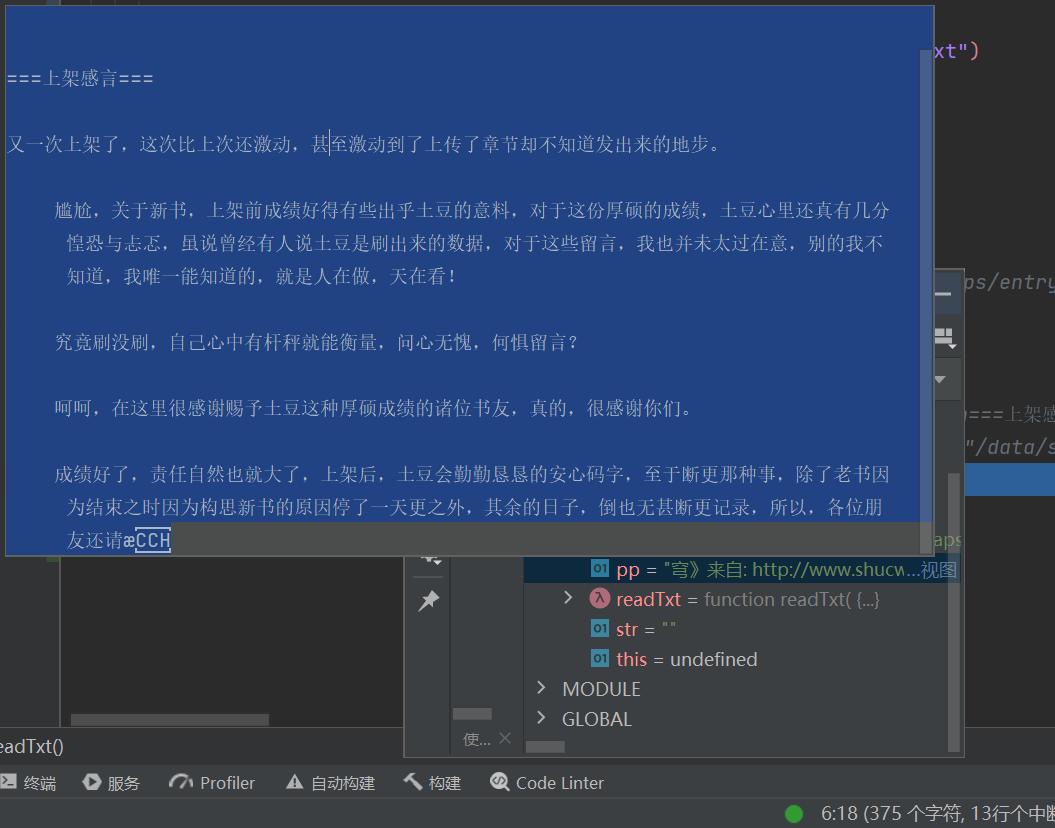
如题,我在使用fs.readText(filePath: string, options?: { offset?: number; length?: number; encoding?: string; }): Promise<string>读取文本时,传入的参数的offset和length实际是字节数,而不是编码后的字符串的长度和位置,效果如下图(出现乱码,实际读取数为375zi),如果offset和length显然是字节数,这是bug还是就是这样设计的呢,如果是字节数的话,那么这个位置和长度的确定就麻烦了呀

更多关于HarmonyOS 鸿蒙Next fs.readText()中的参数为何是字节数而不是字符数的实战教程也可以访问 https://www.itying.com/category-93-b0.html

readText接口原型对标nodejs的readFile和微信小程序的readFile(其支持可选项),这两种的规格都是字节数。业界(Android、IOS、nodejs等)基本所有读相关接口的长度的规格都是以字节为单位。此场景考虑基础库编解码进行处理,能够获取指定字符个数的数据长度。文件系统不关注编码格式
更多关于HarmonyOS 鸿蒙Next fs.readText()中的参数为何是字节数而不是字符数的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


在HarmonyOS鸿蒙Next中,fs.readText()方法的参数是字节数而非字符数的设计,主要是基于文件系统的底层处理机制。文件系统在读取文件时,通常以字节为单位进行操作,而不是直接处理字符。字符的编码方式(如UTF-8、UTF-16等)会导致字符占用的字节数不同,因此在读取文件时,直接指定字节数更为准确和高效。
例如,在UTF-8编码中,一个英文字符通常占用1个字节,而一个中文字符可能占用3个字节。如果以字符数为单位读取文件,系统需要先解析文件的编码方式,计算字符数对应的字节数,这会增加额外的计算开销。直接指定字节数可以避免这种复杂性,简化文件读取过程,并确保读取的准确性。
此外,fs.readText()方法在内部会根据文件的编码方式将读取的字节数据转换为字符串,因此开发者无需手动处理字节到字符的转换。这种设计使得API的使用更加简洁,同时保持了底层文件系统操作的高效性。