




Rust自然语言处理库lingua的使用,高效多语言检测和文本分析工具
Rust自然语言处理库lingua的使用,高效多语言检测和文本分析工具
![]()
1. 这个库是做什么的?
它的任务很简单:告诉你某段文本是用什么语言写的。这在自然语言处理应用中作为预处理步骤非常有用,比如文本分类和拼写检查。其他用例可能包括根据电子邮件的语言将电子邮件路由到正确的地理位置客户服务部门。
2. 为什么需要这个库?
语言检测通常作为大型机器学习框架或自然语言处理应用的一部分。在你不需要这些系统的全部功能或不想学习它们的使用方法时,一个灵活的小库就派上用场了。
3. 支持哪些语言?
相比其他语言检测库,Lingua更注重质量而非数量。目前支持以下75种语言:
- 从南非荷兰语到祖鲁语
4. 准确度如何?
Lingua能够为每种支持的语言报告准确度统计数据。测试数据分为三部分:
- 最小长度为5个字符的单词列表
- 最小长度为10个字符的单词对列表
- 各种长度的完整语法句子列表
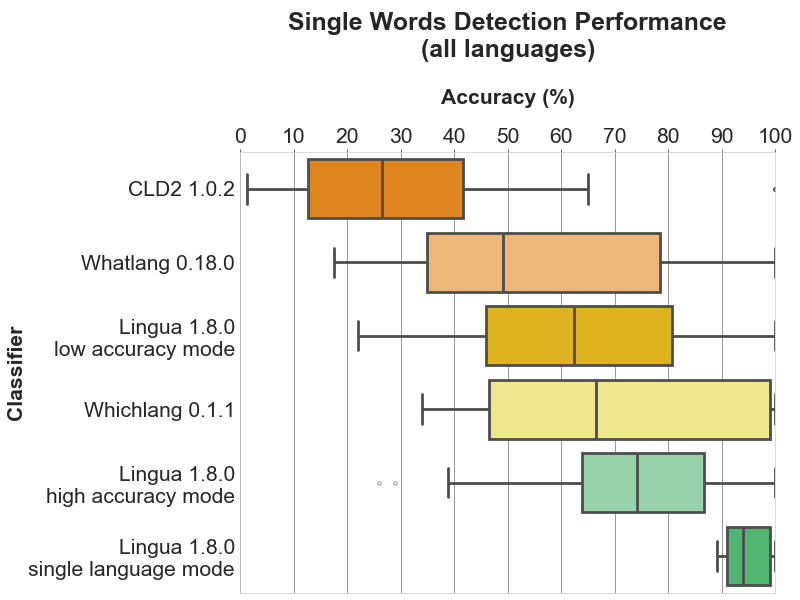
5. 速度如何?
在iMac 3.6 Ghz 8-Core Intel Core i9上进行基准测试:
- 单线程模式下处理2000个句子需要1.6021秒
- 多线程模式下需要183.82毫秒
示例代码
// 基本用法示例
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
use lingua::Language::{English, French, German, Spanish};
let languages = vec![English, French, German, Spanish];
let detector: LanguageDetector = LanguageDetectorBuilder::from_languages(&languages).build();
let detected_language: Option<Language> = detector.detect_language_of("languages are awesome");
assert_eq!(detected_language, Some(English));
// 计算置信度值示例
let confidence_values = detector
.compute_language_confidence_values("languages are awesome")
.into_iter()
.map(|(language, confidence)| (language, (confidence * 100.0).round() / 100.0))
.collect::<Vec<_>>();
assert_eq!(
confidence_values,
vec![
(English, 0.93),
(French, 0.04),
(German, 0.02),
(Spanish, 0.01)
]
);
完整示例
use lingua::{Language, LanguageDetectorBuilder};
fn main() {
// 1. 创建语言检测器,指定要检测的语言范围
let languages = vec![
Language::English,
Language::French,
Language::German,
Language::Spanish,
Language::Chinese,
];
let detector = LanguageDetectorBuilder::from_languages(&languages)
.with_preloaded_language_models() // 预加载语言模型
.build();
// 2. 检测单个文本的语言
let text1 = "Hello, how are you doing today?";
let detected_language = detector.detect_language_of(text1);
println!("Detected language: {:?}", detected_language);
// 3. 计算所有可能语言的置信度
let text2 = "今天天气真好";
let confidences = detector.compute_language_confidence_values(text2);
println!("Confidence values:");
for (lang, confidence) in confidences {
println!(" {:?}: {:.2}%", lang, confidence * 100.0);
}
// 4. 检测混合语言文本
let mixed_text = "Bonjour tout le monde. 今天天气真好。 How are you?";
let results = detector.detect_multiple_languages_of(mixed_text);
println!("\nMixed language detection results:");
for result in results {
println!(
"Language: {:?}, Text: '{}'",
result.language(),
&mixed_text[result.start_index()..result.end_index()]
);
}
}
如何添加到项目
在Cargo.toml中添加:
[dependencies]
lingua = "1.7.2"
或者只添加需要的语言:
[dependencies]
lingua = { version = "1.7.2", default-features = false, features = ["french", "italian", "spanish"] }
关键特性
- 支持75种语言的精确检测
- 可以检测混合语言文本
- 提供置信度分数
- 支持单线程和多线程模式
- 有高精度和低精度模式可选
- 可以构建为WebAssembly在浏览器中使用
Lingua特别适合需要高精度语言检测的场景,尤其是对短文本的检测,相比其他库有显著优势。
1 回复

Rust自然语言处理库lingua使用指南
介绍
lingua是一个高性能的Rust自然语言处理库,专注于多语言检测和文本分析。它支持75种语言的检测,具有极高的准确率和快速的检测速度。lingua特别适合需要处理多语言内容的应用程序,如国际化网站、聊天应用或文本分析工具。
主要特性
- 支持75种语言的检测
- 高准确率(平均99%以上)
- 快速检测(毫秒级别)
- 低内存占用
- 支持短文本检测
- 提供语言概率分析
安装方法
在Cargo.toml中添加依赖:
[dependencies]
lingua = "1.3"
基本使用
语言检测
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
fn main() {
// 创建检测器(包含所有支持的语言)
let detector: LanguageDetector = LanguageDetectorBuilder::from_all_languages().build();
let text = "This is a sample text to detect the language.";
// 检测最可能的语言
let detected_language = detector.detect_language_of(text);
println!("Detected language: {:?}", detected_language); // English
// 获取所有可能的语言及其概率
let confidence_values = detector.compute_language_confidence_values(text);
for (language, confidence) in confidence_values {
println!("{:?}: {:.4}", language, confidence);
}
}
特定语言检测
如果只需要检测特定几种语言,可以提高效率和准确性:
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
fn main() {
// 只检测英语、法语和西班牙语
let languages = vec![Language::English, Language::French, Language::Spanish];
let detector = LanguageDetectorBuilder::from_languages(&languages).build();
let text = "Bonjour tout le monde";
let detected_language = detector.detect_language_of(text);
println!("Detected language: {:?}", detected_language); // French
}
短文本检测
lingua对短文本也有很好的支持:
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
fn main() {
let detector = LanguageDetectorBuilder::from_all_languages().build();
let short_text = "Hola";
let detected_language = detector.detect_language_of(short_text);
println!("Detected language: {:?}", detected_language); // Spanish
}
高级用法
设置最小相对距离
可以设置最小相对距离来提高检测可靠性:
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
fn main() {
let detector = LanguageDetectorBuilder::from_all_languages()
.with_minimum_relative_distance(0.1) // 设置最小相对距离
.build();
let text = "This text is very short and ambiguous";
let detected_language = detector.detect_language_of(text);
// 如果最可能语言的概率没有显著高于其他语言,会返回None
println!("Detected language: {:?}", detected_language);
}
使用预加载的语言模型
对于频繁检测,可以预加载语言模型:
use lingua::{Language, LanguageDetectorBuilder};
fn main() {
// 预加载英语和法语模型
let detector = LanguageDetectorBuilder::from_languages(&[Language::English, Language::French])
.with_preloaded_language_models()
.build();
// 后续检测会更快
let text = "Le français est une belle langue";
let detected_language = detector.detect_language_of(text);
println!("Detected language: {:?}", detected_language);
}
性能优化建议
- 如果只需要检测特定几种语言,只加载这些语言的模型
- 对于批量检测,重用同一个检测器实例
- 对于已知主要语言的应用,优先加载这些语言
- 考虑使用
with_preloaded_language_models()来加速首次检测
支持的语言列表
lingua支持75种语言,包括但不限于:
- 英语 (English)
- 中文 (Chinese)
- 西班牙语 (Spanish)
- 法语 (French)
- 德语 (German)
- 俄语 (Russian)
- 日语 (Japanese)
- 韩语 (Korean)
- 阿拉伯语 (Arabic)
- 印地语 (Hindi)
完整列表请参考官方文档。
lingua是一个强大且高效的语言检测工具,特别适合需要处理多语言内容的Rust应用程序。它的高准确率和快速检测使其成为自然语言处理任务中的优秀选择。
完整示例代码
下面是一个完整的lingua使用示例,展示了多种功能:
use lingua::{Language, LanguageDetector, LanguageDetectorBuilder};
fn main() {
// 1. 初始化检测器 - 只加载常用语言以提高性能
let languages = vec![
Language::English,
Language::Chinese,
Language::Spanish,
Language::French,
Language::German,
];
let detector = LanguageDetectorBuilder::from_languages(&languages)
.with_preloaded_language_models() // 预加载模型
.with_minimum_relative_distance(0.01) // 设置最小相对距离
.build();
// 2. 测试不同语言的文本
let test_cases = vec![
("Hello world!", "短英文文本"),
("你好,世界!", "短中文文本"),
("Bonjour le monde", "法语句子"),
("这是一段较长的中文文本,用于测试lingua库对中文的检测能力。", "长中文文本"),
("This is a longer English text to test the accuracy of the language detection for longer content.", "长英文文本"),
];
// 3. 检测语言并显示结果
for (text, description) in test_cases {
println!("\n测试用例: {}", description);
println!("文本内容: {}", text);
// 检测最可能的语言
if let Some(language) = detector.detect_language_of(text) {
println!("检测到的语言: {:?}", language);
} else {
println!("无法确定语言 (概率差异不足)");
}
// 获取所有语言的置信度
let confidences = detector.compute_language_confidence_values(text);
println!("语言置信度:");
for (lang, confidence) in confidences {
println!(" {:?}: {:.4}", lang, confidence);
}
}
// 4. 批量处理示例
let batch_texts = vec![
"Hello",
"Hola",
"你好",
"Bonjour"
];
println!("\n批量检测结果:");
for text in batch_texts {
let lang = detector.detect_language_of(text).unwrap_or(Language::Unknown);
println!("'{}' => {:?}", text, lang);
}
}
这个完整示例展示了:
- 如何初始化一个优化的语言检测器
- 测试不同长度和语言类型的文本
- 获取单一检测结果和置信度分析
- 批量处理多文本的示例
您可以根据实际需求调整加载的语言列表和参数设置,以达到最佳的性能和准确性平衡。