




HarmonyOS 鸿蒙Next中富文本编辑器组件内容如何保存
HarmonyOS 鸿蒙Next中富文本编辑器组件内容如何保存 使用官方提供的组件,https://developer.huawei.com/consumer/cn/market/prod-detail/837623efe716444a83898a19b253c5a0/2adce9bbd4cb42d58a87e6add45594b3
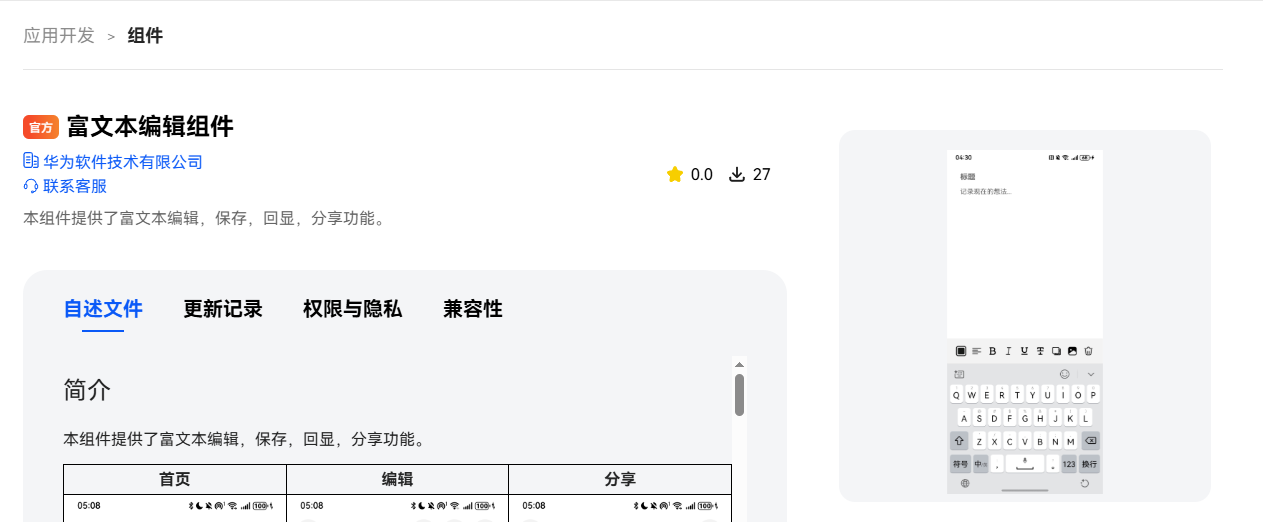
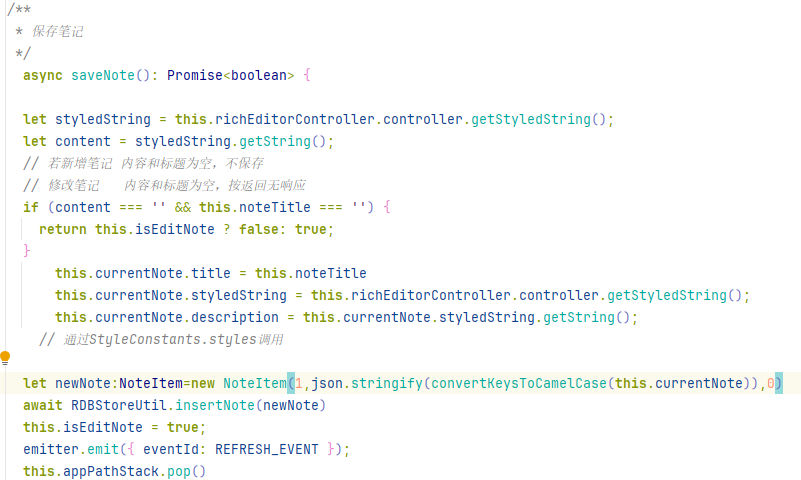
把文本内容序列化后保存进数据库中,再反序列读取时就会报错,主要是styledString属性会报错,要怎么才能解决

更多关于HarmonyOS 鸿蒙Next中富文本编辑器组件内容如何保存的实战教程也可以访问 https://www.itying.com/category-93-b0.html

可以参考使用三方库:[@easy/tinymce](https://ohpm.openharmony.cn/#/cn/detail/@easy%2Ftinymce)。
更多关于HarmonyOS 鸿蒙Next中富文本编辑器组件内容如何保存的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html

直接使用 JSON.stringify 序列化 styledString 会丢失富文本样式对象(如字体、颜色等)。建议将内容与样式分离存储:
interface NoteItem {
id: number;
content: string; // 纯文本内容
styles: string; // 序列化后的样式数据
}
通过 StyleConstants.styles 获取样式配置并转换为可序列化格式
const styledString = this.richEditorController.controller.getStyledString();
const styles = styledString.getStyles(); // 假设存在获取样式方法
const serializedStyles = JSON.stringify(styles);

styledString属性报错是因为直接序列化富文本组件内部对象时丢失了类型信息。RichEditor组件的样式属性包含特殊数据结构,直接JSON序列化会导致类型信息丢失。
解决方案:
1/ 使用富文本控制器提取可序列化数据结构:
const contentData = {
text: this.controller.getText(),
spans: this.controller.getAllSpans().map(span => ({
start: span.start,
end: span.end,
style: {
color: span.style.color?.toString(),
fontSize: span.style.fontSize,
fontWeight: span.style.fontWeight
}
}))
};
2/ 自定义序列化方法
function serializeContent(content) {
return JSON.stringify({
...content,
spans: content.spans.map(span => ({
...span,
style: Object.keys(span.style).reduce((acc, key) => {
acc[key] = String(span.style[key]);
return acc;
}, {})
}))
});
}
3/ 反序列化恢复
function deserializeContent(data) {
const parsed = JSON.parse(data);
parsed.spans.forEach(span => {
this.controller.addSpanStyle(span.start, span.end, {
color: Color.fromString(span.style.color),
fontSize: Number(span.style.fontSize),
fontWeight: span.style.fontWeight
});
});
this.controller.setText(parsed.text);
}

在HarmonyOS鸿蒙Next中,富文本编辑器组件的内容可通过调用其API方法获取并保存。使用getHtml()或getText()方法获取内容,然后通过文件系统或数据库接口存储。具体操作需参考鸿蒙SDK中关于富文本编辑器的文档。
