




HarmonyOS鸿蒙Next中有什么办法通过当前书籍中的当前页面来定位朗读的起始段落。
HarmonyOS鸿蒙Next中有什么办法通过当前书籍中的当前页面来定位朗读的起始段落。 可以通过什么属性定位到Reader Kit中的当前页面的文字的,现在只能通过BookParserHandler.getSpineItemContent(spineIndex)获取单个书脊资源里的内容,但却没办法通过当前书脊中的当前页面来定位朗读的起始段落。

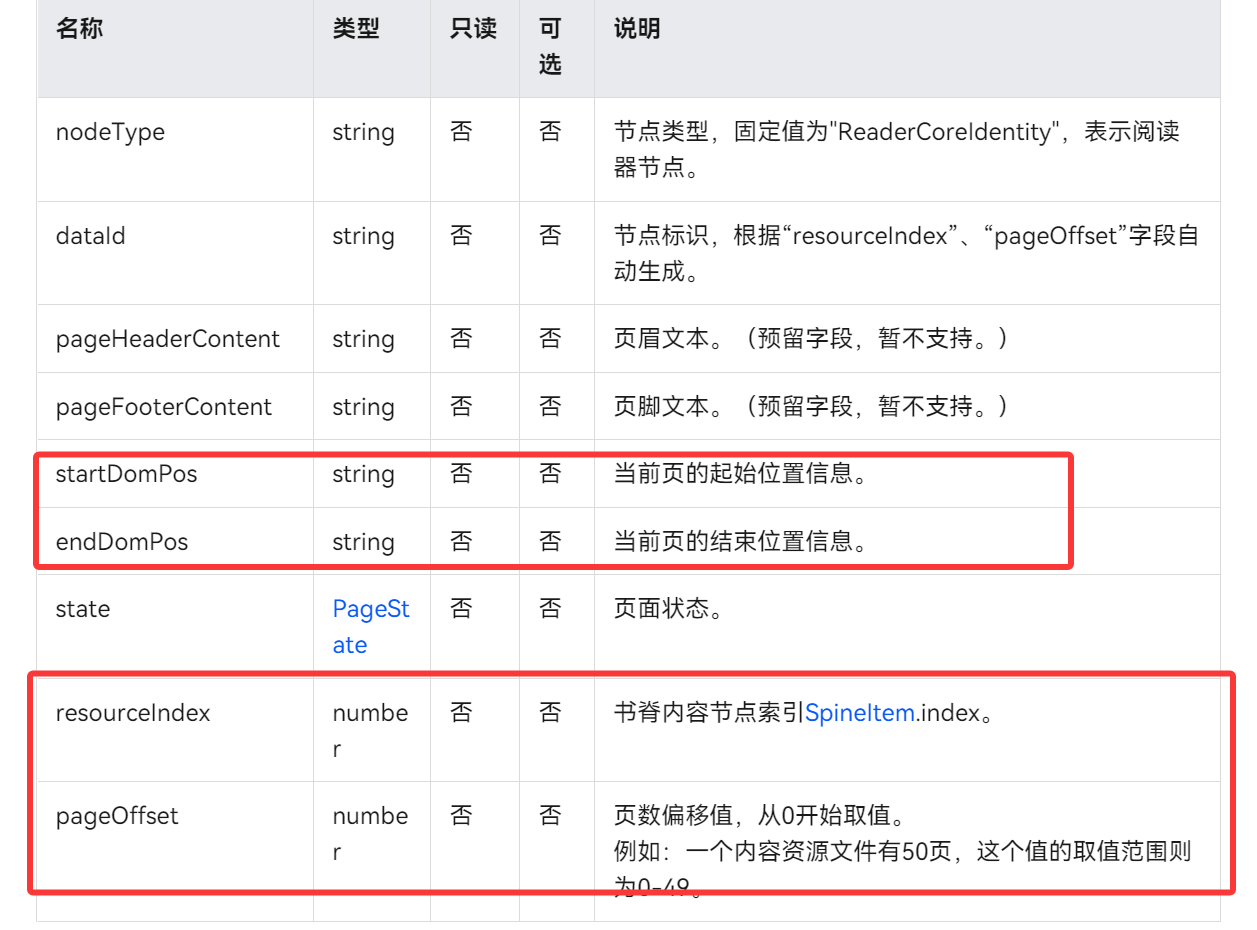
监听pageShow事件,获取PageDataInfo中的startDomPos和resourceIndex、pageOffset,然后使用这些属性来定位当前页的起始段落。可能还需要结合其他方法,如保存这些信息以便后续恢复或定位。开发者可在此保存内容分布排版数据,利用data.resourceIndex及data.startDomPos数据调用startPlay接口继续阅读。
import { readerCore } from '@kit.ReaderKit';
import { common } from '@kit.AbilityKit';
import { hilog } from '@kit.PerformanceAnalysisKit';
private async registerListener(){
try {
let context = this.getUIContext().getHostContext() as common.UIAbilityContext;
let readerComponentController: readerCore.ReaderComponentController = new readerCore.ReaderComponentController();
await readerComponentController.init(context)
readerComponentController.on('pageShow', (data: readerCore.PageDataInfo): void => {
// 开发者可在此保存内容分布排版数据,利用data.resourceIndex及data.startDomPos数据调用startPlay接口继续阅读
hilog.info(0x0000, 'testTag', 'pageshow: data is: ' + JSON.stringify(data));
})
} catch (err) {
hilog.error(0x0000, 'testTag', `failed to registerListener, Code is ${err.code}, message is ${err.message}`);
}
}
更多关于HarmonyOS鸿蒙Next中有什么办法通过当前书籍中的当前页面来定位朗读的起始段落。的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html

在HarmonyOS鸿蒙Next中,可通过TextContentInfo和TextParagraphInfo实现基于页面定位朗读起始段落。使用getTextContentInfo()获取书籍文本内容,结合getPageStart()和getPageEnd()确定当前页面范围。通过TextParagraphInfo的段落索引与页面字符位置匹配,调用SpeechPlayer的startSpeaking()指定段落起始位置。需利用TextAnalyzer进行文本段落划分,确保朗读定位准确。

在HarmonyOS Next的Reader Kit中,可以通过BookParserHandler.getPageContent()方法结合页面索引来获取当前页面的文本内容。具体步骤如下:
- 使用
BookParserHandler.getCurrentPageIndex()获取当前页面的索引值。 - 调用
BookParserHandler.getPageContent(pageIndex)传入页面索引,返回当前页面的结构化文本数据。 - 解析返回的页面内容对象(通常包含段落列表),通过段落偏移量定位朗读起始位置。
若需精确定位到段落级别,可结合TextParagraph对象的startOffset属性确定段落起始位置。示例代码框架:
int currentPageIndex = bookParserHandler.getCurrentPageIndex();
PageContent pageContent = bookParserHandler.getPageContent(currentPageIndex);
List<TextParagraph> paragraphs = pageContent.getParagraphs();
// 根据业务逻辑选择起始段落
TextParagraph startParagraph = paragraphs.get(targetIndex);
注意:需确保已正确初始化BookParserHandler并加载书籍内容。页面索引与书脊索引需对应正确的书籍解析状态。