




Golang GraphQuery:强大的文本查询语言
Golang GraphQuery:强大的文本查询语言
GraphQuery 






GraphQuery 是一种查询语言和执行引擎,可与任何后端服务绑定。它是后端语言无关的。
项目地址:GraphQuery
相关项目:
- GraphQuery-PlayGround : 在交互式演练中学习和测试 GraphQuery
- 文档 : GraphQuery 的详细文档
- GraphQuery-http : GraphQuery 的跨语言解决方案
目录
概述
GraphQuery 是一种易于使用的查询语言,它内置了 Xpath/CSS/Regex/JSONpath 选择器和足够的内置文本处理函数。
最神奇的是,您可以使用极简的 GraphQuery 语法来获取您想要的任何数据结构。
语言无关性
使用 GraphQuery 可以让您在任何后端语言上统一文本解析逻辑。 您无需在不同语言之间寻找 Xpath/CSS/Regex/JSONpath 选择器的实现,熟悉它们的语法或探索它们的兼容性。
多选择器语法支持
您可以使用 GraphQuery 解析任何文本并使用您熟练的选择器。GraphQuery 目前支持以下选择器:
Jsonpath用于解析 JSON 字符串Xpath和CSS用于解析 XML/HTML正则表达式用于解析任何文本。
您可以在 GraphQuery 中任意组合使用这些选择器。
完整的功能
Graphquery 有一些内置的文本处理函数,如 trim、template、replace。如果您认为这些函数不能满足您的需求,可以在管道中注册新的自定义函数。
开始使用
GraphQuery 由查询语言和管道组成。为了引导您了解这些组件,我们编写了一个示例,旨在说明 GraphQuery 的各个部分。这个示例并不全面,但旨在快速介绍 GraphQuery 的核心概念。该示例的前提是我们希望使用 GraphQuery 查询图书馆书籍的信息。
1. 第一个示例
<library>
<!-- Great book. -->
<book id="b0836217462" available="true">
<isbn>0836217462</isbn>
<title lang="en">Being a Dog Is a Full-Time Job</title>
<quote>I'd dog paddle the deepest ocean.</quote>
<author id="CMS">
<?echo "go rocks"?>
<name>Charles M Schulz</name>
<born>1922-11-26</born>
<dead>2000-02-12</dead>
</author>
<character id="PP">
<name>Peppermint Patty</name>
<born>1966-08-22</born>
<qualification>bold, brash and tomboyish</qualification>
</character>
<character id="Snoopy">
<name>Snoopy</name>
<born>1950-10-04</born>
<qualification>extroverted beagle</qualification>
</character>
</book>
</library>
面对这样的文本结构,我们自然会想到从文本中提取以下数据结构:
{
bookID
title
isbn
quote
language
author{
name
born
dead
}
character [{
name
born
qualification
}]
}
这很完美,当您知道要提取的数据结构时,您实际上已经成功了 80%,以上是我们想要的数据结构,我们暂时称它为 DDL(数据定义语言)。让我们看看 GraphQuery 是如何做到的:
{
bookID `css("book");attr("id")`
title `css("title")`
isbn `xpath("//isbn")`
quote `css("quote")`
language `css("title");attr("lang")`
author `css("author")` {
name `css("name")`
born `css("born")`
dead `css("dead")`
}
character `xpath("//character")` [{
name `css("name")`
born `css("born")`
qualification `xpath("qualification")`
}]
}
如您所见,GraphQuery 的语法在 DDL 中添加了一些用 ** 包裹的字符串。这些由 ** 包裹的字符串称为 管道。我们将在后面介绍管道。
让我们先看看 GraphQuery 引擎返回给我们什么数据。
{
"bookID": "b0836217462",
"title": "Being a Dog Is a Full-Time Job",
"isbn": "0836217462",
"quote": "I'd dog paddle the deepest ocean.",
"language": "en",
"author": {
"born": "1922-11-26",
"dead": "2000-02-12",
"name": "Charles M Schulz"
},
"character": [
{
"born": "1966-08-22",
"name": "Peppermint Patty",
"qualification": "bold, brash and tomboyish"
},
{
"born": "1950-10-04",
"name": "Snoopy",
"qualification": "extroverted beagle"
}
],
}
哇,太棒了。就像我们想要的一样。 我们将上面的示例称为 Example1,现在让我们简要看一下什么是管道。
2. 管道
管道是一个函数集合,它使用父元素文本作为入口参数,依次执行集合中的函数。 例如,我们前面示例中的 language 字段定义如下:
language `css("title");attr("lang")`
language 是字段名,css("title"); attr("lang") 是管道。在这个管道中,GraphQuery 首先使用 CSS 选择器从文档中查找 title 节点,然后获取到的 title 节点将被传入 attr() 函数并获取其 lang 属性。整个过程如下:
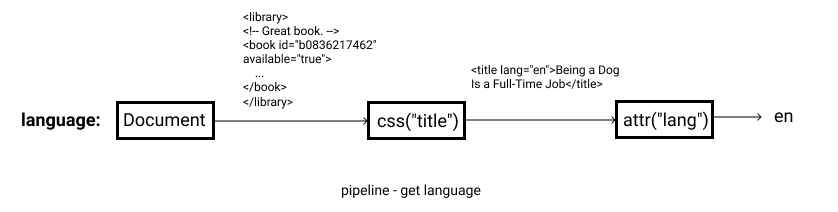
在 Example1 中,我们不仅使用了 css 和 attr 函数,还使用了 xpath()。很容易联想到,Xpath() 就是使用 Xpath 选择器来选择元素。 以下是当前版本 graphquery 内置的管道函数列表:
| 管道 | 原型 | 示例 | 介绍 |
|---|---|---|---|
| css | css(CSSSelector) | css(“title”) | 使用 CSS 选择器选择元素 |
| json | json(JSONSelector) | json(“title”) | 使用 json path 选择元素 |
| xpath | xpath(XpathSelector) | xpath("//title") | 使用 Xpath 选择器选择元素 |
| regex | regex(RegexSelector) | regex("(.*?)") | 使用正则表达式选择器选择元素 |
| trim | trim() | trim() | 清除字符串前后的空格和换行符 |
| template | template(TemplateStr) | template("[{$}]") | 在变量前后添加字符 |
| attr | attr(AttributeName) | attr(“lang”) | 提取当前节点的属性 |
| eq | eq(Index) | eq(“0”) | 获取当前节点集合中的第 n 个元素 |
| string | string() | string() | 提取当前节点原生字符串 |
| text | text() | text() | 提取当前节点的文本 |
| link | link(KeyName) | link(“title”) | 返回指定键的当前文本 |
| replace | replace(A, B) | replace(“a”, “b”) | 将当前节点中的所有 A 替换为 B |
有关管道和函数的更详细介绍,请访问文档。
安装
GraphQuery 目前仅原生支持 Golang,但对于其他语言,它可以作为服务调用。
1. Golang:
go get github.com/storyicon/graphquery
创建一个新的 go 文件:
package main
import (
"encoding/json"
"log"
"github.com/storyicon/graphquery"
)
func main() {
document := `
<html>
<body>
<a href="01.html">Page 1</a>
<a href="02.html">Page 2</a>
<a href="03.html">Page 3</a>
</body>
</html>
`
expr := "{ anchor `css(\"a\")` [ content `text()` ] }"
response := graphquery.ParseFromString(document, expr)
bytes, _ := json.Marshal(response.Data)
log.Println(string(bytes))
}
运行 go 文件,输出如下:
{"anchor":["Page 1","Page 2","Page 3"]}
2. 其他语言
我们使用 HTTP 协议提供跨语言解决方案,供开发人员在启动服务后使用任何想要使用的后端语言访问指定端口来查询 GraphQuery。
GraphQuery-http : GraphQuery 的跨语言解决方案
您也可以使用 RPC 进行通信,但目前您可能需要自己完成这项工作,因为 GraphQuery 上的 RPC 项目仍在开发中。 同时,我们欢迎贡献者为 GraphQuery 编写其他语言的原生支持代码。
更多关于Golang GraphQuery:强大的文本查询语言的实战教程也可以访问 https://www.itying.com/category-94-b0.html

更多关于Golang GraphQuery:强大的文本查询语言的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html
GraphQuery 确实是一个功能强大的文本查询语言,它在 Go 语言中的集成非常直观和高效。以下是一个更详细的 Go 示例,展示如何使用 GraphQuery 解析 HTML 文档并提取结构化数据。假设我们有一个 HTML 文档,包含书籍信息,我们将提取书名、作者和价格。
首先,确保已安装 GraphQuery 包:
go get github.com/storyicon/graphquery
然后,创建一个 Go 文件(例如 main.go),编写以下代码:
package main
import (
"encoding/json"
"fmt"
"log"
"github.com/storyicon/graphquery"
)
func main() {
// 示例 HTML 文档
document := `
<html>
<body>
<div class="book">
<h1 class="title">The Go Programming Language</h1>
<p class="author">Alan A. A. Donovan & Brian W. Kernighan</p>
<span class="price">$34.99</span>
</div>
<div class="book">
<h1 class="title">Mastering Go</h1>
<p class="author">Mihalis Tsoukalos</p>
<span class="price">$29.99</span>
</div>
</body>
</html>
`
// GraphQuery 表达式,用于提取书籍列表
expr := `
{
books ` + "`css(\".book\")`" + ` [{
title ` + "`css(\".title\");text()`" + `
author ` + "`css(\".author\");text();trim()`" + `
price ` + "`css(\".price\");text();replace(\"$\", \"\")`" + `
}]
}
`
// 解析文档
response := graphquery.ParseFromString(document, expr)
if response.Error != "" {
log.Fatalf("GraphQuery parsing error: %s", response.Error)
}
// 将结果序列化为 JSON 并打印
bytes, err := json.MarshalIndent(response.Data, "", " ")
if err != nil {
log.Fatalf("JSON marshaling error: %v", err)
}
fmt.Println(string(bytes))
}
运行此代码(使用 go run main.go),输出将是一个 JSON 对象,包含书籍列表:
{
"books": [
{
"author": "Alan A. A. Donovan & Brian W. Kernighan",
"price": "34.99",
"title": "The Go Programming Language"
},
{
"author": "Mihalis Tsoukalos",
"price": "29.99",
"title": "Mastering Go"
}
]
}
在这个示例中:
- 我们使用
css选择器来定位 HTML 元素,例如css(".book")选择所有书籍的 div 元素。 - 管道函数如
text()提取元素的文本内容,trim()去除前后空格,replace("$", "")移除价格中的美元符号。 - GraphQuery 自动处理数组结构,通过
[]语法提取多个书籍条目。
GraphQuery 的语法简洁,结合了多种选择器(如 CSS、XPath、JSONPath 和正则表达式),使得在 Go 中处理复杂文本解析任务变得高效。对于跨语言使用,可以通过 GraphQuery-http 服务暴露 HTTP 端点,其他语言通过 REST API 调用。例如,使用 curl 测试:
curl -X POST http://localhost:8080/query \
-H "Content-Type: application/json" \
-d '{
"document": "<html>...</html>",
"expression": "{ books `css(\".book\")` [{ title `css(\".title\");text()` author `css(\".author\");text()` }] }"
}'
这将返回类似的 JSON 响应。GraphQuery 的设计避免了在不同语言中重复实现解析逻辑,提高了开发效率。