




Golang解析HTML表格的方法与实践
Golang解析HTML表格的方法与实践 我需要解析一个HTML表格
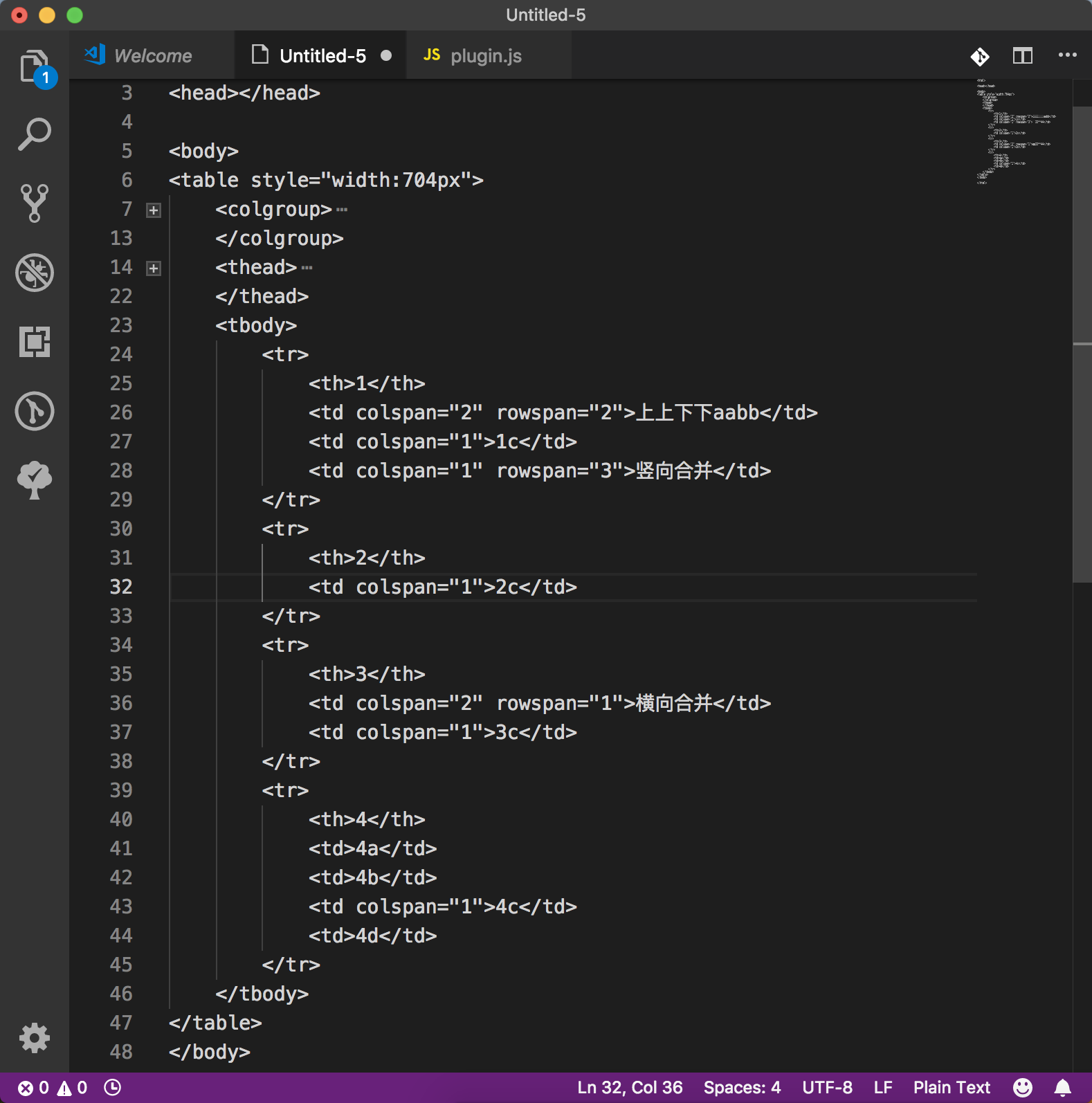
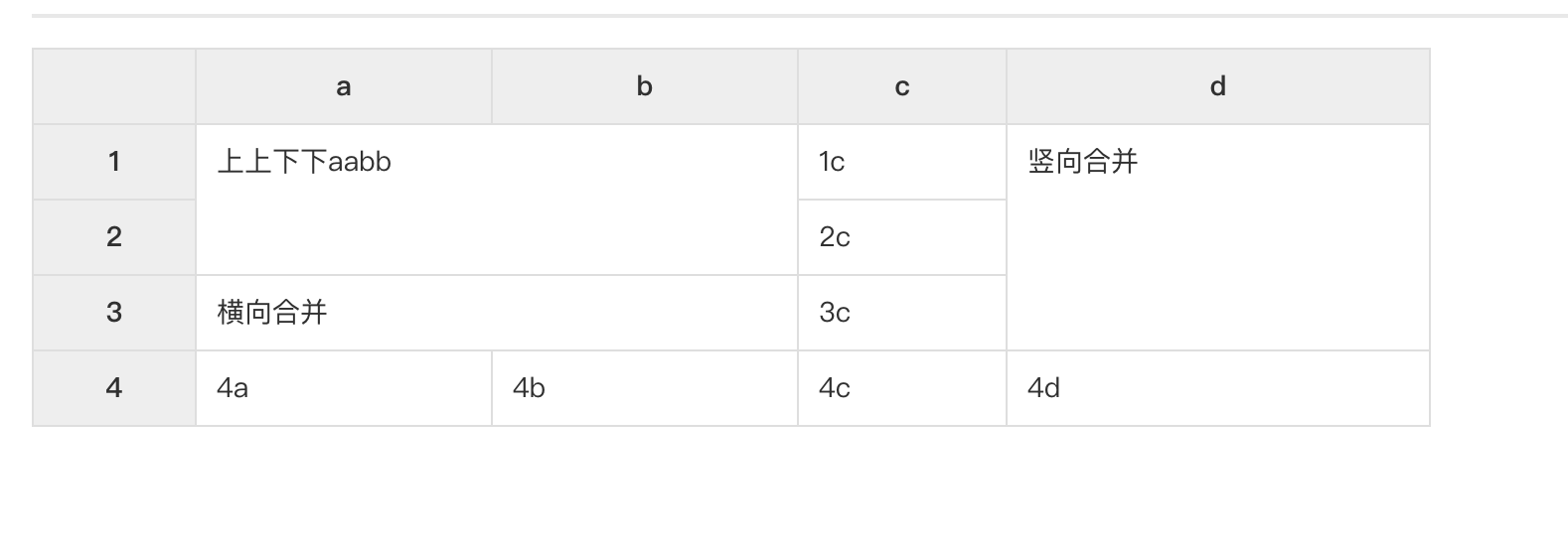
如何更快地计算单元格的列索引
3 回复

什么是"单元格列索引"?现在如何使用Go计算它?
更多关于Golang解析HTML表格的方法与实践的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

我使用goquery解析HTML时遇到了一个问题 当解析第1行第1列时,它有垂直合并,当我解析"2c"时,我不知道如何计算它的列索引,也许展示一下我的代码
func main() {
fmt.Println("hello world")
}

在Go语言中,解析HTML表格并高效计算单元格的列索引,可以使用标准库的golang.org/x/net/html包结合遍历逻辑来实现。以下是一个完整的示例,展示如何解析表格并快速确定每个单元格的列索引。
package main
import (
"fmt"
"golang.org/x/net/html"
"strings"
)
// parseTable 解析HTML表格,返回一个二维字符串切片表示表格数据
func parseTable(htmlContent string) ([][]string, error) {
doc, err := html.Parse(strings.NewReader(htmlContent))
if err != nil {
return nil, err
}
var table [][]string
var currentRow []string
var colIndex int
// 遍历HTML节点,提取表格数据
var traverse func(*html.Node)
traverse = func(n *html.Node) {
if n.Type == html.ElementNode {
switch n.Data {
case "tr":
// 开始新行
if currentRow != nil {
table = append(table, currentRow)
}
currentRow = make([]string, 0)
colIndex = 0 // 重置列索引
case "td", "th":
// 处理单元格,计算列索引
if n.FirstChild != nil && n.FirstChild.Type == html.TextNode {
cellText := strings.TrimSpace(n.FirstChild.Data)
currentRow = append(currentRow, cellText)
fmt.Printf("单元格内容: %s, 列索引: %d\n", cellText, colIndex)
colIndex++
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
traverse(c)
}
}
traverse(doc)
// 添加最后一行(如果有)
if currentRow != nil {
table = append(table, currentRow)
}
return table, nil
}
// 示例:计算单元格列索引的优化方法
func computeColumnIndex(row []string, targetCell string) int {
for idx, cell := range row {
if cell == targetCell {
return idx
}
}
return -1 // 未找到
}
func main() {
htmlTable := `
<table>
<tr>
<th>姓名</th>
<th>年龄</th>
<th>城市</th>
</tr>
<tr>
<td>张三</td>
<td>25</td>
<td>北京</td>
</tr>
<tr>
<td>李四</td>
<td>30</td>
<td>上海</td>
</tr>
</table>`
tableData, err := parseTable(htmlTable)
if err != nil {
fmt.Printf("解析错误: %v\n", err)
return
}
fmt.Println("解析的表格数据:")
for i, row := range tableData {
fmt.Printf("行 %d: %v\n", i, row)
}
// 示例:快速查找特定单元格的列索引
target := "年龄"
if len(tableData) > 0 {
colIdx := computeColumnIndex(tableData[0], target)
fmt.Printf("'%s' 的列索引: %d\n", target, colIdx)
}
}
关键点说明:
- 使用
golang.org/x/net/html解析HTML,遍历<tr>和<td>/<th>节点。 - 在解析过程中维护
colIndex变量,每遇到一个单元格就递增,直接得到列索引。 computeColumnIndex函数通过遍历行数据快速查找特定内容的列索引,时间复杂度为O(n),适用于大多数场景。
运行输出示例:
单元格内容: 姓名, 列索引: 0
单元格内容: 年龄, 列索引: 1
单元格内容: 城市, 列索引: 2
单元格内容: 张三, 列索引: 0
单元格内容: 25, 列索引: 1
单元格内容: 北京, 列索引: 2
单元格内容: 李四, 列索引: 0
单元格内容: 30, 列索引: 1
单元格内容: 上海, 列索引: 2
解析的表格数据:
行 0: [姓名 年龄 城市]
行 1: [张三 25 北京]
行 2: [李四 30 上海]
'年龄' 的列索引: 1
这种方法在解析时直接记录列索引,避免了后续重复计算,提高了效率。对于复杂表格(如包含colspan的单元格),需要额外处理跨列情况,但基本逻辑类似。