




Golang读取文件时如何跳过最后一行
Golang读取文件时如何跳过最后一行 我有一个包含6000多行的大文件。最后一行是时间戳,当解析到这一行时会出现致命错误。如何在遇到这个时间戳时停止数据解析,或者直接跳过文件的最后一行?

我通过 scanner.Scan() 跳过了文档的第一行,因为第一行没有有用数据。
我使用的是 bufio.Scanner。我的代码如下:
scanner := bufio.NewScanner(GPSData)
scanner.Scan()
for scanner.Scan() {
if reisaiDataRow, err = rp.allocateFile1Neo(scanner.Text()); err != nil {
return nil, fmt.Errorf("failed allocate: %s", err.Error())
}
if reisaiDataRow == nil {
continue
}
reisaiMap[reisaiDataRow.BusNumber] = reisaiDataRow
}
更多关于Golang读取文件时如何跳过最后一行的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html
我看到这个问题的两种解决方案,第一种是通过错误处理,正如 @Christophe_Meessen 回答的那样,但如果你在文件中间遇到这个错误,就无法解决。第二种是每次迭代读取两行,如果第二行是EOF就跳过它。

我按照你的建议有了这个想法
只有当数组长度为11时我才解析数据,这意味着当遇到时间戳时数组长度为1,这时就会跳过它
// 代码示例
func main() {
// 这里放置Go代码
}



我们需要更多信息来帮助你。你遇到的错误是什么?rp.allocateFile1Neo 是做什么的?
与其直接将 scanner.Text() 传递给 rp.allocateFile1Neo,你可以将其赋值给一个变量,并在将值传递给 rp.allocateFile1Neo 之前检查变量内容是否有效。
scanner := bufio.NewScanner(GPSData)
scanner.Scan()
for scanner.Scan() {
line := scanner.Text()
if !isValid(line) {
continue
}
if reisaiDataRow, err = rp.allocateFile1Neo(line); err != nil {
return nil, fmt.Errorf(“failed allocate: %s”, err.Error())
}
if reisaiDataRow == nil {
continue
}
reisaiMap[reisaiDataRow.BusNumber] = reisaiDataRow
}


我将重新表述我的问题。
我有一个超过6000行的文件,第一行是说明性文字 示例: 车牌号,目的地 等
后续行是数据 示例: 46779978,考纳斯 等
总共有11个数据字段,全部用逗号分隔。我使用以下代码从文件中读取这些数据:
scanner := bufio.NewScanner(GPSData)
scanner.Scan()
for scanner.Scan() {
if reisaiDataRow, err = rp.allocateFile1Neo(scanner.Text()); err != nil {
return nil, fmt.Errorf("failed allocate: %s", err.Error())
}
if reisaiDataRow == nil {
continue
}
reisaiMap[reisaiDataRow.BusNumber] = reisaiDataRow
}
allocateFile1Neo 是数据解析函数,如下所示:
arr := strings.Split(data, ",")
r = new(ReisaiDataRow)
r.VehicleType = arr[0]
r.Route = arr[1]
if r.Schedule, err = strconv.Atoi(arr[2]); err != nil {
return nil, err
}
数据的最后一行是时间戳,格式如下:2019-10-15 18:42:00
我遇到了以下错误:
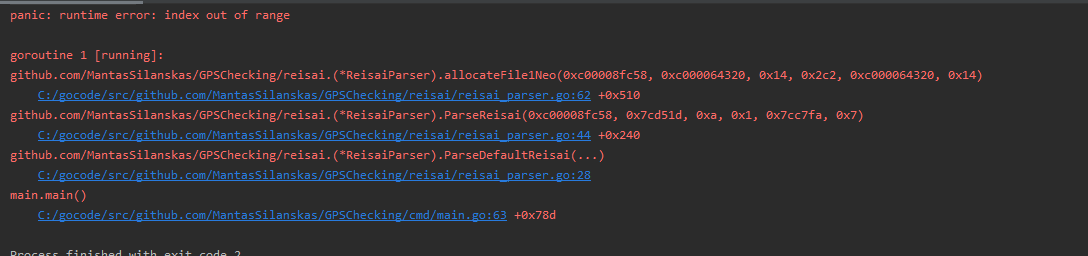
我认为问题在于这一行完全没有逗号,但程序仍然尝试解析它?如何让我的程序识别出这是时间戳,或者直接跳过文件的最后一行?
在Go语言中,可以通过多种方式跳过文件的最后一行。以下是一个高效的方法,使用bufio.Scanner逐行读取文件,并在遇到最后一行(时间戳)时停止处理。这种方法适用于大文件,因为它不会将整个文件加载到内存中。
示例代码:
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
file, err := os.Open("yourfile.txt") // 替换为你的文件路径
if err != nil {
fmt.Printf("打开文件时出错: %v\n", err)
return
}
defer file.Close()
scanner := bufio.NewScanner(file)
var lines []string
// 逐行读取文件
for scanner.Scan() {
lines = append(lines, scanner.Text())
}
if err := scanner.Err(); err != nil {
fmt.Printf("读取文件时出错: %v\n", err)
return
}
// 检查是否有行,然后跳过最后一行
if len(lines) > 0 {
lines = lines[:len(lines)-1] // 移除最后一行
}
// 处理剩余的行(例如,解析数据)
for _, line := range lines {
fmt.Println(line) // 这里替换为你的解析逻辑
}
}
如果文件非常大(例如6000多行),并且你不想在内存中存储所有行,可以逐行处理并在倒数第二行停止。但这种方法需要知道总行数或检测最后一行。以下是使用计数器的方法,假设你知道总行数(例如6000行):
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
file, err := os.Open("yourfile.txt") // 替换为你的文件路径
if err != nil {
fmt.Printf("打开文件时出错: %v\n", err)
return
}
defer file.Close()
scanner := bufio.NewScanner(file)
lineCount := 0
totalLines := 6000 // 假设总行数为6000,跳过最后一行
for scanner.Scan() {
lineCount++
if lineCount >= totalLines {
break // 在最后一行之前停止
}
line := scanner.Text()
// 处理行数据(例如,解析)
fmt.Println(line) // 这里替换为你的解析逻辑
}
if err := scanner.Err(); err != nil {
fmt.Printf("读取文件时出错: %v\n", err)
return
}
}
如果不知道总行数,但最后一行是时间戳(例如,可以通过正则表达式识别),可以在读取时检查每行内容,并在遇到时间戳时停止:
package main
import (
"bufio"
"fmt"
"os"
"regexp"
)
func main() {
file, err := os.Open("yourfile.txt") // 替换为你的文件路径
if err != nil {
fmt.Printf("打开文件时出错: %v\n", err)
return
}
defer file.Close()
scanner := bufio.NewScanner(file)
timestampRegex := regexp.MustCompile(`^\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}$`) // 示例时间戳格式,根据你的文件调整
for scanner.Scan() {
line := scanner.Text()
if timestampRegex.MatchString(line) {
break // 遇到时间戳时停止解析
}
// 处理行数据
fmt.Println(line) // 这里替换为你的解析逻辑
}
if err := scanner.Err(); err != nil {
fmt.Printf("读取文件时出错: %v\n", err)
return
}
}
这些方法可以根据你的具体需求调整。如果文件结构固定,第一种方法(移除最后一行)最简单;如果最后一行可识别,使用正则表达式更灵活。