




HarmonyOS鸿蒙Next中小艺智能体能否实现读图功能
HarmonyOS鸿蒙Next中小艺智能体能否实现读图功能 怎么让小艺智能体支持拍照读图 并调用后端图像大模型进行分析?
15 回复

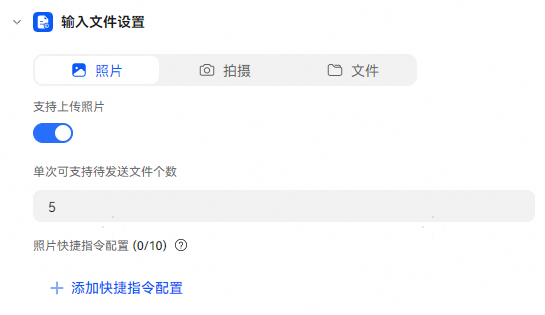







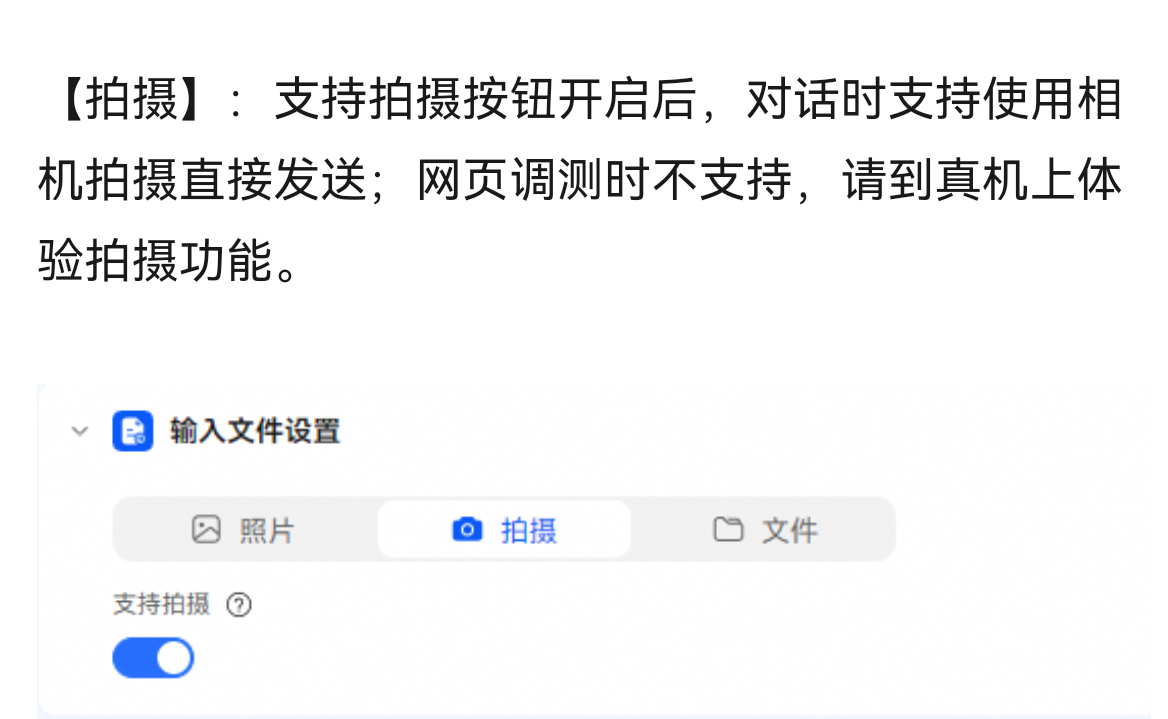

找HarmonyOS工作还需要会Flutter的哦,有需要Flutter教程的可以学学大地老师的教程,很不错,B站免费学的哦:https://www.bilibili.com/video/BV1S4411E7LY/?p=17



HarmonyOS Next中的小艺智能体支持读图功能。该功能基于华为自研的盘古大模型,能够识别图像中的物体、场景、文字等信息,并进行内容理解与交互。用户可通过语音或文字指令让小艺分析图片,实现图像描述、文字提取、物体识别等操作。该能力深度集成于系统,可在相册、相机等应用场景中直接调用。
在HarmonyOS Next中,小艺智能体可以通过集成ArkUI的媒体查询和AI能力框架,实现拍照读图并调用后端图像大模型进行分析。以下是关键步骤:
-
调用系统相机或相册:使用
@ohos.multimedia.image和@ohos.file.picker接口,获取用户拍摄或选择的图片,并转换为PixelMap对象。 -
图像预处理与上传:将
PixelMap转换为Base64或二进制流,通过@ohos.net.http模块将图像数据上传至你的后端服务。 -
后端图像分析:后端接收图像后,调用图像大模型(如自研或第三方视觉API)进行分析,并将结构化结果(如物体识别、文字提取)返回给前端。
-
小艺智能体集成:在元服务中,通过
@ohos.ai.nlp或自定义Ability处理用户语音/文本指令,触发上述流程,并将分析结果以语音或图文形式反馈。
代码示例(图像获取与上传):
import picker from '@ohos.file.picker';
import http from '@ohos.net.http';
// 1. 从相册选择图片
let photoSelectOptions = new picker.PhotoSelectOptions();
photoSelectOptions.MIMEType = picker.PhotoViewMIMETypes.IMAGE_TYPE;
let photoPicker = new picker.PhotoViewPicker();
photoPicker.select(photoSelectOptions).then(async (photoSelectResult) => {
let uri = photoSelectResult.photoUris[0];
// 2. 转换为Base64(需使用@ohos.multimedia.image处理)
let imageBase64 = await convertImageToBase64(uri);
// 3. 调用后端API
let httpRequest = http.createHttp();
await httpRequest.request(
"https://your-backend.com/analyze",
{
method: http.RequestMethod.POST,
header: { 'Content-Type': 'application/json' },
extraData: { image: imageBase64 }
}
);
});
注意事项:
- 需在
module.json5中声明相机、存储和网络权限。 - 图像上传需考虑压缩和格式兼容性。
- 后端模型需支持HarmonyOS Next的API调用规范。
此方案可实现小艺智能体“拍照-上传-分析-反馈”的端云协同读图功能。