




Golang中如何用其他语言实现"*"替换(语音语言相关)
Golang中如何用其他语言实现"*"替换(语音语言相关) 你好
我可以在英文中成功进行“*”替换,但在波斯语和中文中遇到了问题。 如何解决这个问题?(由于“[]byte”的原因,例如字符"س"是"[216 179]",它由两个独立的字节组成)
换句话说,如何移除"问号"(�)?
这里是PlayGround链接: https://play.golang.org/p/9Nd7rvatqC9
同时,代码审查:
func main() {
fmt.Println( replaceAtIndex2("persian ----","س",'*',0))
fmt.Println( replaceAtIndex2("persian ----","سلام",'*',0))
fmt.Println( replaceAtIndex2("chine +-+-+-","世",'*',0))
fmt.Println( replaceAtIndex2("chine +-+-+-","世界",'*',0))
fmt.Println( replaceAtIndex2("english ====","h",'*',0))
fmt.Println( replaceAtIndex2("english ====","hello",'*',0))
}
func replaceAtIndex2(typeOfValue string ,str string, replacement rune, index int) string {
fmt.Println(typeOfValue, len(str))
fmt.Println(typeOfValue, []byte(str))
return str[:index] + string(replacement) + str[index+1:]
}
提前感谢。
更多关于Golang中如何用其他语言实现"*"替换(语音语言相关)的实战教程也可以访问 https://www.itying.com/category-94-b0.html

你需要将字符串转换为 rune 切片([]rune(str)),替换单个 rune,然后再转换回字符串。大致如下:
tmp := []rune(str)
tmp[index] = replacement
return string(tmp)
不过我现在在手机上,无法测试。
更多关于Golang中如何用其他语言实现"*"替换(语音语言相关)的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

最后三个参数是反的
这是由于大多数浏览器对混合的从右到左(RTL)和从左到右(LTR)文本方向支持不佳或更差。此外,据我所知,HTML 中甚至不允许在段落内改变书写方向,所以我理解他们在这方面没有做太多工作。

Norbert 的思路无疑是正确的。在 Go 语言中,rune 用于处理 UTF-8 Unicode 码点。当你需要支持非英文字符时,请使用 rune,而不是 byte。
以下是一个让你的程序正常工作的示例:
func main() {
fmt.Println("hello world")
}
我注释掉了关于波斯语的那两行代码,因为看起来你在那里犯了一些错误。与中文和英文的例子相比,最后三个参数的顺序是反的,并且一个双引号(")的位置也不对。

嗨,诺伯特,
哦,谢谢你的提醒!刚才我把代码从 Go Playground 复制粘贴到本地文件中,在文件里,它显示是正确的,如下所示:
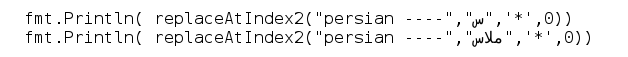
所以 Go Playground 存储的代码是正确的,但 Firefox 和 Chrome 浏览器显示不正确(至少在我的区域设置下是这样)。这就解释了为什么 Go Playground 能编译那个“奇怪的代码”而不报错。

在Golang中处理多语言字符替换时,问题确实出在UTF-8编码上。波斯语和中文字符通常需要多个字节表示,而你的代码按字节切片操作会破坏字符结构。以下是正确的解决方案:
package main
import (
"fmt"
"unicode/utf8"
)
func main() {
fmt.Println(replaceAtIndexUTF8("persian ----", "س", '*', 0))
fmt.Println(replaceAtIndexUTF8("persian ----", "سلام", '*', 0))
fmt.Println(replaceAtIndexUTF8("chine +-+-+-", "世", '*', 0))
fmt.Println(replaceAtIndexUTF8("chine +-+-+-", "世界", '*', 0))
fmt.Println(replaceAtIndexUTF8("english ====", "h", '*', 0))
fmt.Println(replaceAtIndexUTF8("english ====", "hello", '*', 0))
}
func replaceAtIndexUTF8(typeOfValue string, str string, replacement rune, index int) string {
fmt.Println(typeOfValue, "字符数:", utf8.RuneCountInString(str))
fmt.Println(typeOfValue, "字节表示:", []byte(str))
// 将字符串转换为rune切片
runes := []rune(str)
// 检查索引是否有效
if index < 0 || index >= len(runes) {
return str
}
// 替换指定位置的rune
runes[index] = replacement
// 转换回字符串
return string(runes)
}
对于更通用的多字符替换,可以使用以下函数:
func replaceRunesAtIndex(str string, replacement string, index int) string {
runes := []rune(str)
if index < 0 || index >= len(runes) {
return str
}
// 将替换字符串也转换为rune切片
replacementRunes := []rune(replacement)
// 构建结果
result := make([]rune, 0, len(runes)-1+len(replacementRunes))
result = append(result, runes[:index]...)
result = append(result, replacementRunes...)
result = append(result, runes[index+1:]...)
return string(result)
}
如果需要处理字符串中所有特定字符的替换:
func replaceAllRunes(str string, oldRune, newRune rune) string {
runes := []rune(str)
for i := range runes {
if runes[i] == oldRune {
runes[i] = newRune
}
}
return string(runes)
}
关键点是使用rune类型而不是byte来处理Unicode字符。rune是int32的别名,可以表示任何UTF-8字符,无论它需要多少字节。utf8.RuneCountInString()函数可以正确计算字符数,而不是字节数。