




Golang中在map中存储互斥锁的常见陷阱
Golang中在map中存储互斥锁的常见陷阱
var mutexes map[string]*sync.Mutex
var m *sync.Mutex
if mForID, ok := mutexes[ID]; ok {
m = mForID
} else {
m = &sync.Mutex{}
mutexes[ID] = m
}
m.Lock()
defer m.Unlock()
{
// 这里是我希望防止并发访问的代码,前提是ID相同。
// 读取一些数据
// 修改数据
// 将数据写回
}
我试图做的是防止使用相同ID的Go协程之间发生数据竞争。如果ID不同,则没有问题;但如果一个Go协程使用的ID与另一个相同,那么它必须等待另一个Go协程完成后才能访问、修改和写入数据。
我已经测试了这段代码,它似乎按我预期的方式工作。如果我注释掉defer m.Unlock()这一行,然后用相同的ID发出两个请求,第二个请求会被永久锁定。然后,如果我发出一个不同ID的第三个请求,它被允许继续执行,这正是我寻找的功能。
我写的这段代码有什么潜在问题吗?或者有没有更好的方法来实现针对特定ID的互斥锁?
我可能还需要一种方法,在一定时间后从映射中删除互斥锁。
感谢您提供的任何帮助。
更多关于Golang中在map中存储互斥锁的常见陷阱的实战教程也可以访问 https://www.itying.com/category-94-b0.html

我认为你想得太复杂了。为每个ID运行一个单独的goroutine,并将消息发布到通道中怎么样?
更多关于Golang中在map中存储互斥锁的常见陷阱的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

你需要一个互斥锁来保护你的 mutexes 映射,因为修改映射不是“goroutine 安全”的。不过,你具体想做什么呢?一个线程安全的互斥锁映射看起来像是可能通过通道来解决的问题。

感谢您的回复!
在阅读了 Sean 和您的回复后,我认为使用通道是正确的方向。
我将进行一些思考,并尝试使用通道来构建解决方案。我似乎很难确定何时使用通道,何时使用互斥锁。
再次感谢您为我指明了正确的方向!

我的意思是,你既可以使用互斥锁也可以使用协程来实现,但我注意到你并没有完全理解如何在这个场景中使用它们。
首先,你需要创建一个函数来完成你想要的操作
func doMyJob(id string) {
// 从 S3 存储桶获取文件
// 修改数据
// 再次将文件上传到 S3 存储桶
}
说实话,你在这里可以同时使用互斥锁和协程。只需选择对你来说最简单的方式即可。

感谢您花时间帮助我!
啊,我明白了。所以每个 goroutine,无论其 ID 是什么,都必须“排队等待”才能访问这个 map。
以下是我试图实现的目标: 我的服务器正在接收并发的 HTTP 请求。服务器在收到其中一个请求后需要做三件事。
- 使用请求体中包含的 ID 从存储桶中检索一个文件。
- 将请求体中包含的数据合并到这个文件中。
- 将文件保存回存储桶。
以下是我这个场景的一个简陋示意图:
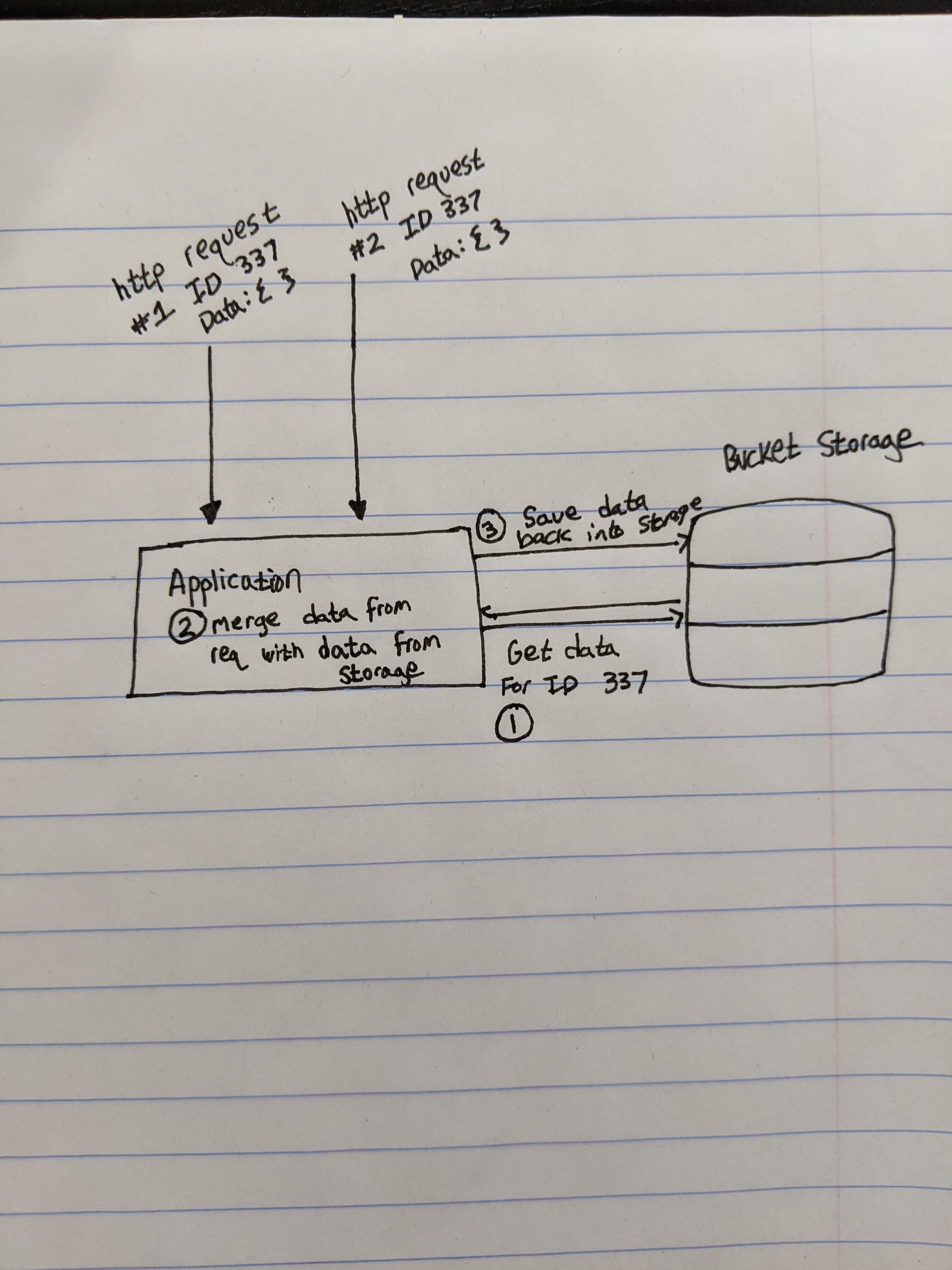
我尝试使用互斥锁的映射(map of mutexes),是为了防止两个或多个具有相同 ID 的请求同时进入我的服务器时发生数据竞争。
Bartłomiej 和您都提到,这可能是通道(channels)的一个更好的应用场景,所以我将尝试使用它们来实现一个解决方案。
再次感谢您的帮助!

在 map 中存储互斥锁的实现存在几个关键问题:
1. 并发访问 map 的竞争条件
你的代码没有保护对 mutexes map 的并发访问,这会导致数据竞争:
var mutexes = make(map[string]*sync.Mutex)
var mu sync.RWMutex // 需要保护 map 的访问
func getMutex(id string) *sync.Mutex {
mu.Lock()
defer mu.Unlock()
if m, ok := mutexes[id]; ok {
return m
}
m := &sync.Mutex{}
mutexes[id] = m
return m
}
func process(id string) {
m := getMutex(id)
m.Lock()
defer m.Unlock()
// 受保护的代码
}
2. 内存泄漏问题
互斥锁永远不会从 map 中删除,随着不同 ID 的增加,map 会无限增长:
var mutexes = make(map[string]*sync.Mutex)
var mu sync.RWMutex
func getMutex(id string) *sync.Mutex {
mu.Lock()
defer mu.Unlock()
if m, ok := mutexes[id]; ok {
return m
}
m := &sync.Mutex{}
mutexes[id] = m
return m
}
func cleanupMutex(id string) {
mu.Lock()
defer mu.Unlock()
delete(mutexes, id)
}
func process(id string) {
m := getMutex(id)
m.Lock()
defer func() {
m.Unlock()
// 注意:这里不能直接调用 cleanupMutex(id)
// 因为其他 goroutine 可能还在使用这个 mutex
}()
// 受保护的代码
}
3. 更好的实现方案:使用 sync.Map
对于这种场景,sync.Map 是更好的选择,它专门为并发访问设计:
var mutexes sync.Map
func process(id string) {
// LoadOrStore 是原子操作
m, _ := mutexes.LoadOrStore(id, &sync.Mutex{})
mutex := m.(*sync.Mutex)
mutex.Lock()
defer mutex.Unlock()
// 受保护的代码
// 可选:在确定不再需要时清理
// 注意:需要确保没有其他 goroutine 在使用
// mutexes.Delete(id)
}
4. 带清理机制的完整实现
这里是一个更完整的实现,包含互斥锁的清理机制:
type MutexManager struct {
mutexes sync.Map
refCounts sync.Map // 引用计数
}
func (mm *MutexManager) Lock(id string) *sync.Mutex {
// 增加引用计数
count, _ := mm.refCounts.LoadOrStore(id, int32(0))
atomic.AddInt32(count.(*int32), 1)
// 获取或创建互斥锁
m, _ := mm.mutexes.LoadOrStore(id, &sync.Mutex{})
mutex := m.(*sync.Mutex)
mutex.Lock()
return mutex
}
func (mm *MutexManager) Unlock(id string, mutex *sync.Mutex) {
mutex.Unlock()
// 减少引用计数
if count, ok := mm.refCounts.Load(id); ok {
if atomic.AddInt32(count.(*int32), -1) == 0 {
// 没有更多引用,清理资源
mm.mutexes.Delete(id)
mm.refCounts.Delete(id)
}
}
}
// 使用示例
var mm MutexManager
func process(id string) {
mutex := mm.Lock(id)
defer mm.Unlock(id, mutex)
// 受保护的代码
}
5. 使用 singleflight 的替代方案
如果你的目标是防止对相同 ID 的重复计算,可以考虑使用 golang.org/x/sync/singleflight:
import "golang.org/x/sync/singleflight"
var group singleflight.Group
func process(id string) (interface{}, error) {
result, err, _ := group.Do(id, func() (interface{}, error) {
// 这里只会对相同 ID 执行一次
// 其他相同 ID 的调用会等待这个完成
// 执行需要保护的代码
return computeResult(id), nil
})
return result, err
}
主要问题总结:
- map 的并发访问需要保护
- 内存泄漏风险
- 引用计数管理复杂
建议使用 sync.Map 或 singleflight 包,它们提供了更安全、更高效的并发原语。