




Golang二进制文件读取问题:新手提问
Golang二进制文件读取问题:新手提问 你好,我需要解释一下“重生新手”这个说法,指的是几年前我曾深入学习过Go语言,当时跟着Todd McLeod的课程学习。之后,我把时间都投入到了电子音乐制作上,显然,我的Go语言技能已经生疏了不少。现在,因为音乐相关的事情,我需要重新拾起Go语言的能力,希望能得到大家的帮助!
我遇到一种混合了二进制和文本的文件格式。其中的文本部分看起来可以转换成一个字典(Dictionary),包含一系列键,比如“comment”、“author”等。文本似乎是采用Pascal风格的字符串格式,即在文本前有一个(或多个)字节来表示字符串的长度。
在附图中,标记为“comment”的文本位于0x83位置,这在该类型的所有文件中似乎是固定的(注意0x82处的长度字节——我在想,这是否是覆盖前3个字节的更大数字结构的一部分,从而构成一个64位的长度)。但是,所有后续文本片段的位置会根据内容而变化。所有文件都包含相同的键集合。
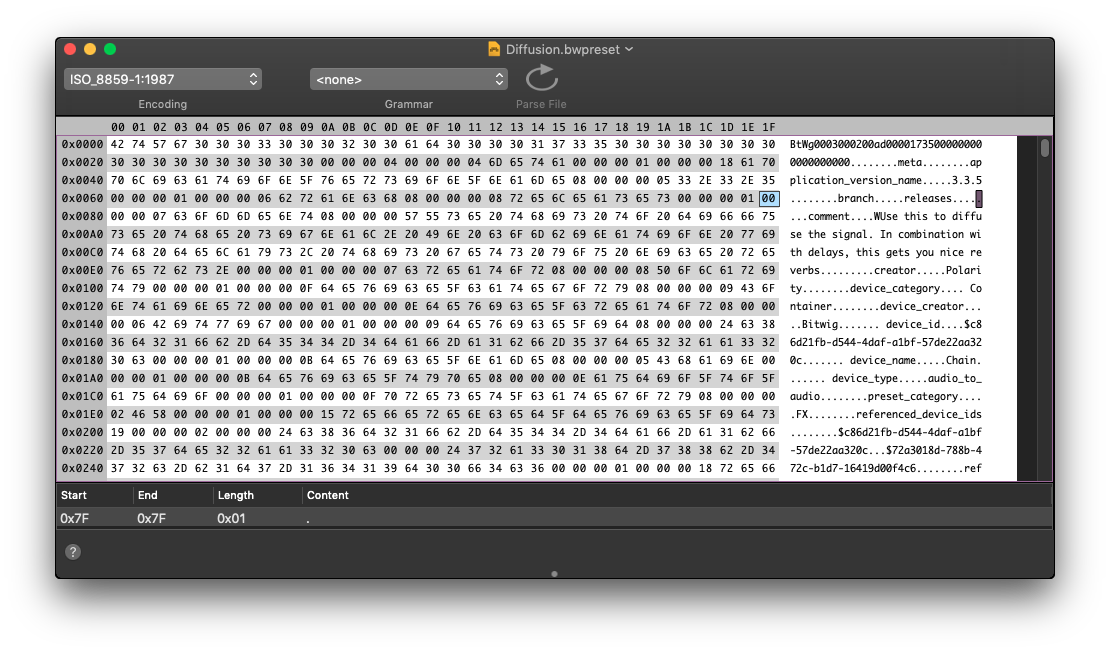
我感兴趣并想要提取的文本都包含在前0x0200个字节内。理想情况下,我希望有一段代码能够将这些键/值对提取到一个字典结构中并打印出来。
我并不是想要一个现成的解决方案。相反,如果有人愿意花时间给我一些指导性的提示,引导我走向正确的方向,我将不胜感激!
我已经设法使用 ioutil.ReadFile 将文件读入了一个切片,但不确定接下来该怎么做。我猜我需要使用不同的接口来读取数字数据和文本数据。
func main() {
fmt.Println("hello world")
}
更多关于Golang二进制文件读取问题:新手提问的实战教程也可以访问 https://www.itying.com/category-94-b0.html

嗨 @ukhobo 感谢回复!我明天会查看你的代码。我对文件的结构已经有了相当清晰的了解——哪些部分是数字,哪些部分是文本。像 file.ReadAt 这样的方法听起来确实会很有用。
// 代码部分保持原样,不翻译
更多关于Golang二进制文件读取问题:新手提问的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

那么,你已经成功地将文件读取到一个字节切片中。 现在,你需要将该切片解码成某种数据结构,以便以有意义的形式保存数据。
或许可以先定义这个结构——你希望数据以什么格式呈现。 然后,你可以开始编写代码,遍历字节切片并填充这个结构。

是的!谢谢 @amnon!尽管我还不确定它们将如何被填充,但我没有理由不能开始定义和编写用于存储提取信息的数据结构。从心理学的角度来看,这绝对会让人感觉有进展,当然,在这个过程中,答案可能会从我潜意识的深处跳出来,给我一个惊喜 😉
// 代码部分保持原样,不翻译

我已经取得了一些进展,最近主要专注于非编码问题,比如重新熟悉 git 和 GitHub,以及将代码结构组织成 cmd 和 output 包。现在有一个问题出现了。我已经成功创建了一个 go.mod 文件,但似乎没有伴随的 go.sum 文件。go.sum 文件是在什么时候创建的呢?
顺便提一下,代码仓库在 https://github.com/carlca/gowig。
从个人角度来看,我有点难以阅读、跟随并立即理解你第二个代码片段的逻辑,老实说,但这可能是因为我看不到你的全部代码。
有时人们会说,Go 代码不应该试图过于巧妙,最好编写易于理解的代码,即使这会使代码更冗长。另一方面,这种想法可能只适用于需要被许多人阅读和维护的代码。我认为,如果这是一个个人项目,那么实现任何对你/未来的你有效的代码模式都是可以的。
你的第一个代码片段在 Playground 中似乎可以编译和运行,没有任何错误:https://play.golang.org/p/3fKyT5gffxH

进展不错,很高兴听到我这个充满漏洞的想法(到目前为止)还算有点用处 :blush:
关于 go.mod / go.sum 方面,go.mod 包含包引用,而 go.sum 包含项目外部包的哈希值计算。如果你在代码中添加了对某个外部包的导入,当你执行 go build 时,应该会看到 god.mod 中填充了该包的信息,并且 go.sum 会自动填充该包的哈希值。如果你没有导入或引用任何外部包,那么 go.mod 将基本保持为空,go.sum 也不会存在,因为没有必要。
func main() {
fmt.Println("hello world")
}

你可以使用 *File.ReadAt 从文件中读取特定位置的数据块,类似这样:
f, err := os.Open("./dataFile.dat")
if err != nil {
log.Panic(err)
}
chunk, err := readFromFile(f, 64, 20) // 从文件的第64字节开始读取20个字节
func readFromFile(file *os.File, offset, size int) ([]byte, error) {
res := make([]byte, size)
if _, err := file.ReadAt(res, int64(offset)); err != nil {
return nil, err
}
return res, nil
}
……然后,当你获得一小块数据切片后,如果你的结构体字节对齐方式与数据块中的字节内容相匹配,你可以像下面这样将字节反序列化为结构体:
var target someStructType
buf := bytes.NewReader(chunk)
err := binary.Read(buf, binary.LittleEndian, &target)
if err != nil {
fmt.Println("binary.Read failed:", err)
}
这个想法能够成功的关键在于,你需要充分理解文件中数据的结构,以便能够准确地将文件字节块与结构体对齐。
顺便说一句,我不确定上面的代码是否能编译通过,因为我是直接在这里输入的……但它应该足够接近,能给你一些关于如何着手处理的思路。

嗨 @ukhobo,我很高兴地报告,在你的帮助下,我取得了一些进展。这是我的代码…
streamPos := 0x7f
chunk, err := readFromFile(f, streamPos, 4) //从文件的 0x7f 字节处读取 4 个字节
var size int32
buf := bytes.NewReader(chunk)
err = binary.Read(buf, binary.BigEndian, &size)
if err != nil {
fmt.Println("binary.Read failed:", err)
}
fmt.Println(size)
我抓取了 4 个字节的数据:0, 0, 0 和 7 到 chunk 中,然后将其放入 buf。我必须将 size 从 int64 改为 int32,以匹配 buf 的 4 字节长度(否则我会遇到意外的 EOF)。最后,我不得不将 LittleEndian 改为 BigEndian。暴露这一点的是,size 的输出结果是 1879048192,也就是 0x70000000!受到这次成功的鼓舞,我打算今晚就到这里,明天重新开始。在我之前作为开发人员的职业生涯中学到的一件事是,在深夜这个时间点,最好见好就收 ;)
到目前为止,谢谢你的帮助。这正是我所希望得到的那种帮助 :)
我又取得了一些进展。以下是我最新代码的一部分……
func ProcessPreset(filename string) error {
f, err := os.Open(filename)
if err != nil {
log.Fatal(err)
}
defer f.Close()
var streamPos int32 = 0x7f
var size int32
var text string
if streamPos, size, err = readIntChunk(f, streamPos); err != nil {
return err
}
fmt.Println("size: ", size)
fmt.Println("stringPos: ", streamPos)
if streamPos, size, text, err = readTextChunk(f, streamPos, size); err != nil {
return err
}
fmt.Println("size: ", size)
fmt.Println("stringPos: ", streamPos)
fmt.Println("text: ", text)
streamPos++
if streamPos, size, err = readIntChunk(f, streamPos); err != nil {
return err
}
fmt.Println("size: ", size)
fmt.Println("stringPos: ", streamPos)
if streamPos, size, text, err = readTextChunk(f, streamPos, size); err != nil {
return err
}
fmt.Println("size: ", size)
fmt.Println("stringPos: ", streamPos)
fmt.Println("text: ", text)
return nil
}
如你所见,除了在函数的最开始部分,我选择了使用稍微扁平化的方法来处理错误。我就是想不出如何在不引起编译器报错的情况下做到这一点。有什么想法吗?

根据你的描述,这是一个典型的二进制文件解析问题。你需要处理Pascal风格的字符串(长度前缀+数据)和可能的变长数据结构。以下是具体的实现方案:
package main
import (
"encoding/binary"
"fmt"
"io"
"os"
)
// 解析Pascal风格字符串:先读长度,再读内容
func readPascalString(r io.Reader) (string, error) {
var length uint8
if err := binary.Read(r, binary.LittleEndian, &length); err != nil {
return "", err
}
data := make([]byte, length)
if _, err := io.ReadFull(r, data); err != nil {
return "", err
}
return string(data), nil
}
// 解析可能的64位长度前缀字符串
func readPascalString64(r io.Reader) (string, error) {
var length uint64
if err := binary.Read(r, binary.LittleEndian, &length); err != nil {
return "", err
}
data := make([]byte, length)
if _, err := io.ReadFull(r, data); err != nil {
return "", err
}
return string(data), nil
}
func main() {
// 读取文件
data, err := os.ReadFile("yourfile.bin")
if err != nil {
panic(err)
}
// 创建字节读取器
r := &sliceReader{data: data, pos: 0}
dict := make(map[string]string)
// 跳过固定偏移到0x83位置
r.pos = 0x83
// 示例:解析comment字段(根据你的格式调整)
// 假设0x82处是长度字节
r.pos = 0x82
comment, err := readPascalString(r)
if err == nil {
dict["comment"] = comment
}
// 继续解析其他字段...
// 你需要根据实际格式确定每个字段的位置和长度编码方式
// 打印结果
for k, v := range dict {
fmt.Printf("%s: %s\n", k, v)
}
}
// 自定义读取器,方便控制位置
type sliceReader struct {
data []byte
pos int
}
func (r *sliceReader) Read(p []byte) (n int, err error) {
if r.pos >= len(r.data) {
return 0, io.EOF
}
n = copy(p, r.data[r.pos:])
r.pos += n
return n, nil
}
// 如果需要读取特定字节序的数字
func (r *sliceReader) ReadUint16() (uint16, error) {
if r.pos+2 > len(r.data) {
return 0, io.EOF
}
val := binary.LittleEndian.Uint16(r.data[r.pos:])
r.pos += 2
return val, nil
}
func (r *sliceReader) ReadUint32() (uint32, error) {
if r.pos+4 > len(r.data) {
return 0, io.EOF
}
val := binary.LittleEndian.Uint32(r.data[r.pos:])
r.pos += 4
return val, nil
}
关键点说明:
-
二进制读取:使用
binary.Read读取固定长度的数字数据,注意字节序(你的情况可能是Little Endian) -
字符串解析:
- 单字节长度前缀:
readPascalString函数 - 多字节长度前缀:
readPascalString64函数(根据实际情况调整类型)
- 单字节长度前缀:
-
位置控制:
- 使用自定义的
sliceReader可以精确控制读取位置 - 通过
r.pos直接跳转到特定偏移量
- 使用自定义的
-
格式分析:
- 你需要先用hex编辑器分析文件结构
- 确定每个字段的起始位置、长度编码方式(1字节、2字节、4字节还是8字节长度前缀)
- 确定字段顺序是否固定
-
调试建议:
// 打印十六进制视图辅助分析
func hexDump(data []byte, offset int) {
for i := 0; i < len(data); i += 16 {
fmt.Printf("%04x: ", offset+i)
for j := 0; j < 16; j++ {
if i+j < len(data) {
fmt.Printf("%02x ", data[i+j])
} else {
fmt.Print(" ")
}
}
fmt.Println()
}
}
根据你的截图,0x82处的字节可能是长度,0x83开始是字符串数据。你需要验证长度字节是否包含自身或其他元数据。如果遇到解析问题,先用小段代码测试单个字段的解析逻辑。