




Golang解决基于k8s的服务器Pod重启问题
Golang解决基于k8s的服务器Pod重启问题 你好,
我在进行一个负载测试(5000个请求,最大CPU使用量为1000毫核)时,遇到了一个问题:我的基于Golang的服务器Pod会多次重启。在Pod级别我没有看到任何panic发生,日志表明可能存在I/O等待(我看到了多条此类日志(The Go Playground))。此外,我还看到一些标记为semacquire的日志。
goroutine 130355 [runnable]:
internal/poll.runtime_Semacquire(0xc0000d20cc)
/usr/local/go/src/runtime/sema.go:61 +0x45
internal/poll.(*fdMutex).rwlock(0xc0000d20c0, 0x196f200, 0x171b1c0)
/usr/local/go/src/internal/poll/fd_mutex.go:154 +0xb3
internal/poll.(*FD).writeLock(...)
/usr/local/go/src/internal/poll/fd_mutex.go:239
internal/poll.(*FD).Write(0xc0000d20c0, 0xc0023b0000, 0x560, 0x8fe, 0x0, 0x0, 0x0)
/usr/local/go/src/internal/poll/fd_unix.go:261 +0x6e
os.(*File).write(...)
/usr/local/go/src/os/file_posix.go:48
os.(*File).Write(0xc000010018, 0xc0023b0000, 0x560, 0x8fe, 0x0, 0x0, 0x10)
/usr/local/go/src/os/file.go:174 +0x8e
encoding/json.(*Encoder).Encode(0xc000e27068, 0x171b1c0, 0xc001df1e60, 0xd, 0x29bfc80)
/usr/local/go/src/encoding/json/stream.go:231 +0x1df
github.com/krogertechnology/krogo/pkg/log.(*logger).log(0xc00020e580, 0x4, 0x0, 0x0, 0xc000b73b80, 0x1, 0x1)
我能根据这些信息做出一些合理的推断吗?比如我的代码中某处存在goroutine泄漏,或者是其他问题?
更多关于Golang解决基于k8s的服务器Pod重启问题的实战教程也可以访问 https://www.itying.com/category-94-b0.html

避免空闲请求的重要设置之一是设置 ReadTimeout、WriteTimeout 和 IdleTimeout,也许这能帮到你。
srv := &http.Server{
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 5 * time.Second,
}
srv.ListenAndServe()
看看这些链接

Goroutine in IO wait state for long time
linux, go, httpserver

The complete guide to Go net/http timeouts
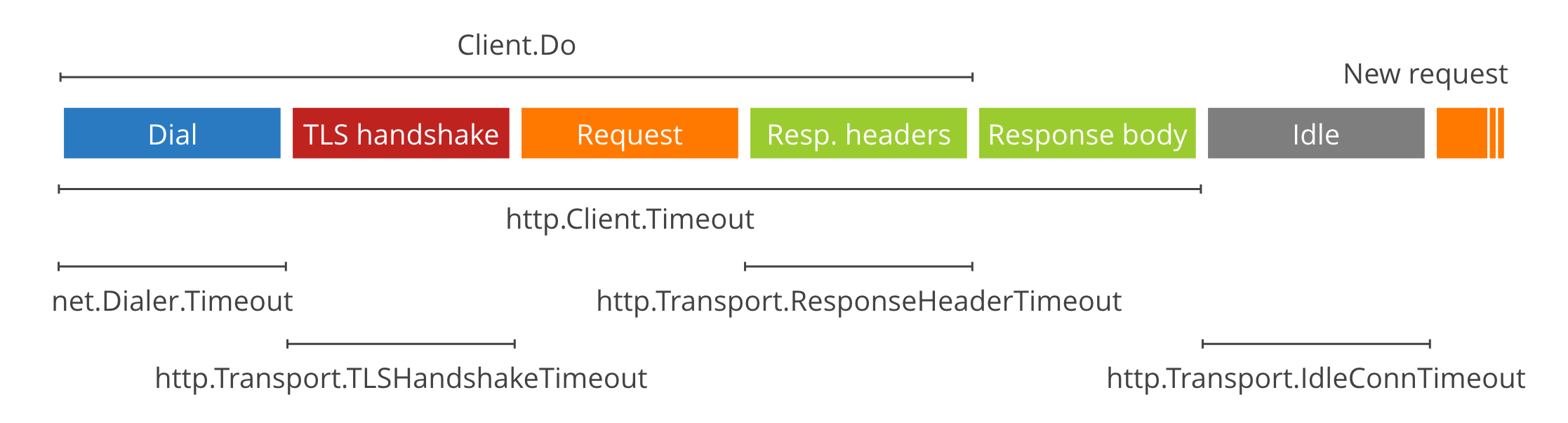
在 Go 中编写 HTTP 服务器或客户端时,超时是最容易出错且最微妙的事情之一:有很多选择,而且错误可能在很长一段时间内都没有后果,直到网络出现故障,进程挂起。
更多关于Golang解决基于k8s的服务器Pod重启问题的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

从你提供的goroutine堆栈信息来看,问题确实与I/O等待和goroutine阻塞有关。堆栈显示goroutine在internal/poll.runtime_Semacquire处阻塞,这通常意味着goroutine在等待文件描述符的读写锁。具体来说,它卡在encoding/json.Encoder.Encode方法中,这很可能是因为日志输出到标准输出或文件时遇到了I/O瓶颈。
在负载测试中,如果日志输出目标(如容器标准输出)无法处理高并发写入,goroutine可能会在semacquire上阻塞,导致goroutine堆积。如果阻塞的goroutine数量持续增长,可能会耗尽系统资源,触发Pod重启(例如,由于内存不足或健康检查失败)。
以下是一个示例,展示如何通过缓冲日志写入或异步日志记录来缓解这个问题:
package main
import (
"bufio"
"encoding/json"
"os"
"sync"
"time"
)
type LogEntry struct {
Level string `json:"level"`
Message string `json:"message"`
Data interface{} `json:"data"`
}
type BufferedLogger struct {
writer *bufio.Writer
mu sync.Mutex
ch chan LogEntry
}
func NewBufferedLogger(file *os.File, bufferSize int, workerCount int) *BufferedLogger {
logger := &BufferedLogger{
writer: bufio.NewWriterSize(file, bufferSize),
ch: make(chan LogEntry, 1000), // 缓冲通道
}
for i := 0; i < workerCount; i++ {
go logger.worker()
}
return logger
}
func (l *BufferedLogger) worker() {
for entry := range l.ch {
l.mu.Lock()
encoder := json.NewEncoder(l.writer)
if err := encoder.Encode(entry); err != nil {
// 处理错误,例如打印到备用输出
os.Stderr.WriteString("日志写入失败: " + err.Error() + "\n")
}
l.mu.Unlock()
}
}
func (l *BufferedLogger) Log(level string, message string, data interface{}) {
select {
case l.ch <- LogEntry{Level: level, Message: message, Data: data}:
// 日志条目已发送到通道
default:
// 通道满时丢弃日志或写入备用输出
os.Stderr.WriteString("日志通道已满,丢弃条目: " + message + "\n")
}
}
func (l *BufferedLogger) Flush() {
l.writer.Flush()
}
func main() {
file, err := os.Create("app.log")
if err != nil {
panic(err)
}
defer file.Close()
logger := NewBufferedLogger(file, 4096, 4) // 4KB缓冲区,4个工作goroutine
defer logger.Flush()
// 模拟高并发日志写入
var wg sync.WaitGroup
for i := 0; i < 5000; i++ {
wg.Add(1)
go func(id int) {
defer wg.Done()
logger.Log("INFO", "处理请求", map[string]int{"request_id": id})
}(i)
}
wg.Wait()
time.Sleep(100 * time.Millisecond) // 等待日志写入完成
}
在这个示例中,BufferedLogger使用缓冲通道和多个工作goroutine来异步处理日志写入,减少了直接I/O阻塞的风险。bufio.Writer提供了额外的缓冲层,以批量写入降低系统调用次数。
此外,检查你的Kubernetes Pod配置,确保资源限制(特别是内存)设置合理,并考虑调整容器的存活探针(liveness probe)和就绪探针(readiness probe)的超时时间,以避免因临时I/O延迟导致不必要的重启。如果使用标准输出日志,确保日志收集器(如Fluentd)能够处理高负载。