




Golang实现Colly网页爬虫指南
Golang实现Colly网页爬虫指南 大家好,
这是我的第一篇帖子。
请问有人能帮我解决这个问题吗?我已经开始使用Colly。到目前为止,我成功地从各种网站获取了所需的信息。
然而,我现在遇到了瓶颈。以这个URL为例:

Espresso Instant Coffee 100 g | Woolworths.co.za
我已经成功地用下面的代码完美地提取了商品描述:
✅ ✅ ✅
func ScrapeData (){
// Instantiate default collector
c := colly.NewCollector()
c.OnHTML("body" , func(e *colly.HTMLElement) {
// Extract the Class Name from the HTML Body element
fmt.Printf("** Program is running ** \n")
// Assign the scraped data to variables
name:= e.ChildText(".prod-name")
price:= e.Attr(".price prod--price")
// print the data obtained
fmt.Println("Description of item : "+ name)
fmt.Println("The price of the item is : "+ price)
})
// Vist the url that the data will be scraped from
c.Visit("https://www.woolworths.co.za/prod/Food/Food-Cupboard/Coffee-Tea-Hot-Drinks/Coffee/Instant-Coffee/Espresso-Instant-Coffee-100-g/_/A-6009175211321")
}
HTML看起来如下所示
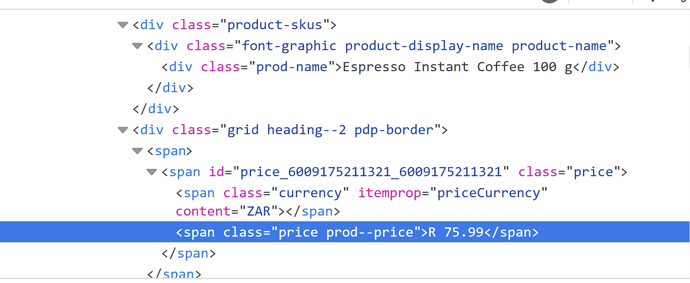
网页上的 .prod-name 可以完美地获取到。
但 .price prod--price 却无法获取。
我尝试了多种方法,但就是无法解决这个问题,所以我决定在这里发帖,也许有经验更丰富的人可以阐明这个问题。
非常感谢
更多关于Golang实现Colly网页爬虫指南的实战教程也可以访问 https://www.itying.com/category-94-b0.html

你好 @Anir,
我不了解 Colly,这只是个快速的想法,但 e.Attr() 是否应该是 e.ChildAttr()?
colly 文档 相当简略,但 Attr() 似乎只是选择元素本身的一个属性。
另一件引起我注意的事情是:在 e.Attr(".price prod--price") 中,属性字符串以一个点开头,就像一个类选择器。HTML 中的属性 class="price prod--price" 包含两个类。我猜 e.Attr() 要么需要属性的字面文本 ("price prod--price"),要么需要属性的名称 ("class"),要么需要这两个类中每一个的选择器 (".price .prod--price")。
但这些只是一些未经深思熟虑的想法,希望能帮助进一步排查问题…
更多关于Golang实现Colly网页爬虫指南的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

问题出在价格选择器的使用上。.price prod--price 不是有效的CSS选择器,您需要正确指定类名。以下是修正后的代码:
package main
import (
"fmt"
"github.com/gocolly/colly"
)
func ScrapeData() {
c := colly.NewCollector()
c.OnHTML("body", func(e *colly.HTMLElement) {
fmt.Printf("** Program is running ** \n")
// 正确的选择器用法
name := e.ChildText(".prod-name")
price := e.ChildText(".price.prod--price") // 注意这里的修正
fmt.Println("Description of item : " + name)
fmt.Println("The price of the item is : " + price)
})
c.Visit("https://www.woolworths.co.za/prod/Food/Food-Cupboard/Coffee-Tea-Hot-Drinks/Coffee/Instant-Coffee/Espresso-Instant-Coffee-100-g/_/A-6009175211321")
}
func main() {
ScrapeData()
}
关键修正点:
- 使用
e.ChildText()而不是e.Attr()来获取文本内容 - 正确的CSS类选择器是
.price.prod--price(用点号连接多个类名)
如果价格元素有特定属性需要提取,可以使用:
// 如果需要获取特定属性
price := e.ChildAttr(".price.prod--price", "data-price")
// 或者获取整个元素的HTML
priceHTML := e.ChildAttr(".price.prod--price", "outerHTML")
调试建议:添加错误处理来查看具体问题:
c.OnError(func(r *colly.Response, err error) {
fmt.Println("Request URL:", r.Request.URL, "failed with response:", r, "\nError:", err)
})