




Golang中如何绕过最大并发连接数的限制
Golang中如何绕过最大并发连接数的限制
我有两个需要读取数据的 csv 文件:
AllTransactions,包含2_618_583条记录SalesTransactions,包含1_070_305条记录
SalesTransactions(即较小的文件)中有一个字段在 AllTransactions(即较大的文件)中不存在。如果大文件中的交易是销售交易(ST_ID 以 “5” 开头),我需要为每条记录添加这个字段。
我想到的办法是,每当在大文件中找到与小文件匹配的条件时,就使用一个 for 循环来遍历小文件的每一行。这意味着,我需要将 SalesTransaction 中的 1_070_305 条记录读取 1_070_305 次。这超过了允许的 1_048_576 次。
因此,我考虑使用 goroutine,并编写了如下代码:
func NetTrx(item string, allTrx *[]models.MainModel, salesTrx *[]models.SalesTransactions) {
var wg sync.WaitGroup
for _, v := range *allTrx {
trx := models.NetTrasActions{
ST_TYPE: v.ST_TP,
ITEM_ID: v.ITEM_ID,
ITEM_NAME: v.ITEM_NAME,
QTY: v.QTY,
CURNT_COST_L: 0,
PRICE: v.PRICE,
TTL_VAL: v.QTY * v.PRICE,
TTL_CST: 0,
SLS_CNTR_ID: v.SLS_CNTR_ID,
BARCODE: v.BARCODE,
}
if strings.HasPrefix(v.ST_ID, "5") { // sales orders transactions starts with 5
wg.Add(1)
go func() {
defer wg.Done()
for _, s := range *salesTrx {
if v.ST_ID == s.ST_ID && v.ITEM_ID == s.ITEM_ID {
trx.CURNT_COST_L = s.CURNT_COST_L
fmt.Println("matched found for item", v.ITEM_ID, "cost is:", s.CURNT_COST_L)
break
}
}
fmt.Println("Exit goroutine")
}()
}
wg.Wait()
// balance of the code
}
运行上述代码时,我遇到了以下错误:
PS D:\Desktop\Bravo for Power BI\2022\YTDTransactions> go run trx
Number of transactions: 2618583
Number of sales transactions: 1070305
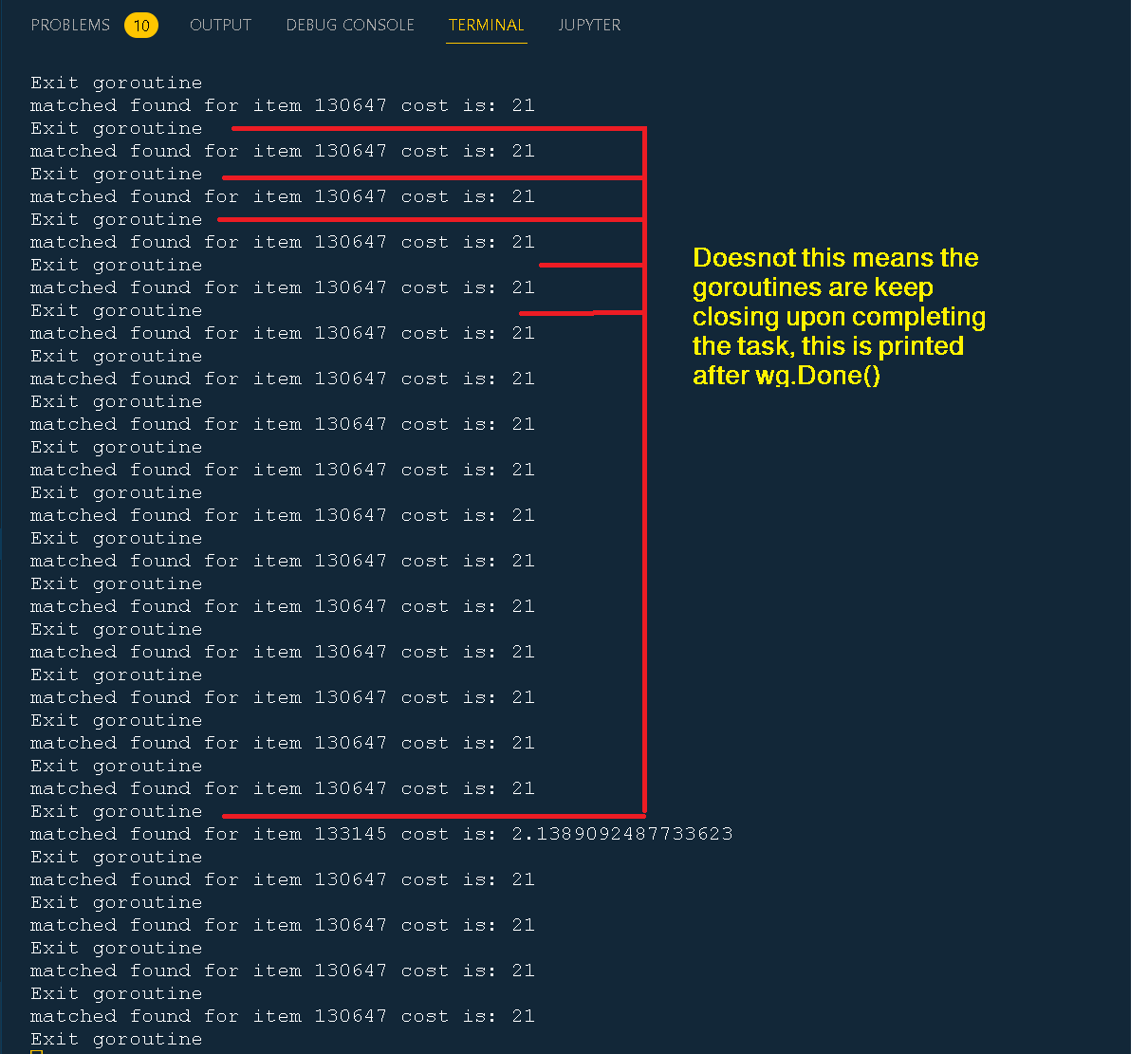
Exit goroutine
Exit goroutine
Exit goroutine
Exit goroutine
Exit goroutine
Exit goroutine
Exit goroutine
Exit goroutine
matched found for item 100000105 cost is: 74
Exit goroutine
matched found for item 100000105 cost is: 74
Exit goroutine
matched found for item 100000105 cost is: 74
Exit goroutine
matched found for item 100000105 cost is: 74
Exit goroutine
.
.
.
Panic: too many concurrent operations on a single file or socket (max 1048575)
我该如何绕过这个限制?难道 wg.Done() 不应该在 goroutine 完成后关闭不需要的 goroutine 吗?这样每次打印 Exit goroutine(它就在 wg.Done() 之前打印)时,goroutine 的数量就会减少 1。
我的假设是,百万级的 goroutine 不应该同时运行,有些会开启,有些会关闭。每个 goroutine 中的操作都很快,所以 goroutine 应该会定期关闭,而不会达到百万个并发!
更多关于Golang中如何绕过最大并发连接数的限制的实战教程也可以访问 https://www.itying.com/category-94-b0.html

你是怎么调用 NetTrx 的?就我所见,NetTrx 本身除了向标准输出执行 fmt.Println 外,并没有进行任何 IO 操作。我怀疑问题出在别的地方。
更多关于Golang中如何绕过最大并发连接数的限制的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html
唯一的IO操作是通过fmt.Println调用输出到标准输出。也许你创建了超过一百万个goroutine,而它们都在对fmt.Println的调用上阻塞了?这是相同的代码,但我将消息发送到一个通道,由单个goroutine逐一打印这些消息:
func NetTrx(item string, allTrx *[]models.MainModel, salesTrx *[]models.SalesTransactions) {
var wg sync.WaitGroup
msgs := make(chan string, 128)
defer close(msgs)
println := func(args ...interface{}) {
msgs <- fmt.Sprintln(args...)
}
go func() {
for msg := range msgs {
fmt.Println(msg)
}
}()
for _, v := range *allTrx {
trx := models.NetTrasActions{
ST_TYPE: v.ST_TP,
ITEM_ID: v.ITEM_ID,
ITEM_NAME: v.ITEM_NAME,
QTY: v.QTY,
CURNT_COST_L: 0,
PRICE: v.PRICE,
TTL_VAL: v.QTY * v.PRICE,
TTL_CST: 0,
SLS_CNTR_ID: v.SLS_CNTR_ID,
BARCODE: v.BARCODE,
}
if strings.HasPrefix(v.ST_ID, "5") { // sales orders transactions starts with 5
wg.Add(1)
go func() {
defer wg.Done()
for _, s := range *salesTrx {
if v.ST_ID == s.ST_ID && v.ITEM_ID == s.ITEM_ID {
trx.CURNT_COST_L = s.CURNT_COST_L
println("matched found for item", v.ITEM_ID, "cost is:", s.CURNT_COST_L)
break
}
}
println("Exit goroutine")
}()
}
wg.Wait()
// balance of the code
}
这只是一个猜测;我目前还不是很确定!

你的代码存在并发设计问题。wg.Wait() 放在了循环内部,导致每次迭代都会等待所有 goroutine 完成,实际上变成了串行执行。更严重的是,对于大文件中每个以 “5” 开头的 ST_ID,你都会启动一个 goroutine 来遍历整个 salesTrx 切片,这会导致创建大量 goroutine。
以下是优化方案:
func NetTrx(item string, allTrx *[]models.MainModel, salesTrx *[]models.SalesTransactions) []models.NetTrasActions {
// 创建销售交易的查找映射,避免线性搜索
salesMap := make(map[string]map[string]float64) // ST_ID -> ITEM_ID -> CURNT_COST_L
for _, s := range *salesTrx {
if _, exists := salesMap[s.ST_ID]; !exists {
salesMap[s.ST_ID] = make(map[string]float64)
}
salesMap[s.ST_ID][s.ITEM_ID] = s.CURNT_COST_L
}
var result []models.NetTrasActions
var mu sync.Mutex
var wg sync.WaitGroup
// 控制并发goroutine数量
sem := make(chan struct{}, 1000) // 限制最大1000个并发
for _, v := range *allTrx {
trx := models.NetTrasActions{
ST_TYPE: v.ST_TP,
ITEM_ID: v.ITEM_ID,
ITEM_NAME: v.ITEM_NAME,
QTY: v.QTY,
CURNT_COST_L: 0,
PRICE: v.PRICE,
TTL_VAL: v.QTY * v.PRICE,
TTL_CST: 0,
SLS_CNTR_ID: v.SLS_CNTR_ID,
BARCODE: v.BARCODE,
}
if strings.HasPrefix(v.ST_ID, "5") {
wg.Add(1)
sem <- struct{}{} // 获取信号量
go func(v models.MainModel, trx models.NetTrasActions) {
defer wg.Done()
defer func() { <-sem }() // 释放信号量
if itemMap, exists := salesMap[v.ST_ID]; exists {
if cost, found := itemMap[v.ITEM_ID]; found {
trx.CURNT_COST_L = cost
}
}
mu.Lock()
result = append(result, trx)
mu.Unlock()
}(v, trx)
} else {
// 非销售交易直接添加到结果
mu.Lock()
result = append(result, trx)
mu.Unlock()
}
}
wg.Wait()
return result
}
更高效的批处理版本:
func NetTrxBatch(allTrx *[]models.MainModel, salesTrx *[]models.SalesTransactions) []models.NetTrasActions {
// 构建查找映射
salesMap := make(map[string]map[string]float64)
for _, s := range *salesTrx {
if _, exists := salesMap[s.ST_ID]; !exists {
salesMap[s.ST_ID] = make(map[string]float64)
}
salesMap[s.ST_ID][s.ITEM_ID] = s.CURNT_COST_L
}
result := make([]models.NetTrasActions, len(*allTrx))
// 使用工作池处理
numWorkers := runtime.NumCPU() * 2
chunkSize := len(*allTrx) / numWorkers
var wg sync.WaitGroup
for i := 0; i < numWorkers; i++ {
wg.Add(1)
start := i * chunkSize
end := start + chunkSize
if i == numWorkers-1 {
end = len(*allTrx)
}
go func(start, end int) {
defer wg.Done()
for j := start; j < end; j++ {
v := (*allTrx)[j]
trx := models.NetTrasActions{
ST_TYPE: v.ST_TP,
ITEM_ID: v.ITEM_ID,
ITEM_NAME: v.ITEM_NAME,
QTY: v.QTY,
CURNT_COST_L: 0,
PRICE: v.PRICE,
TTL_VAL: v.QTY * v.PRICE,
TTL_CST: 0,
SLS_CNTR_ID: v.SLS_CNTR_ID,
BARCODE: v.BARCODE,
}
if strings.HasPrefix(v.ST_ID, "5") {
if itemMap, exists := salesMap[v.ST_ID]; exists {
if cost, found := itemMap[v.ITEM_ID]; found {
trx.CURNT_COST_L = cost
}
}
}
result[j] = trx
}
}(start, end)
}
wg.Wait()
return result
}
关键优化点:
- 使用映射(map)替代线性搜索,将 O(n²) 复杂度降为 O(n)
- 使用信号量或工作池控制并发数量
- 避免为每个匹配都创建 goroutine
- 使用批处理减少 goroutine 创建开销