




Python 数据分析之 pandas 进阶(一)如何使用
python 数据分析之 pandas 进阶(一)
导入本篇中使用到的模块:
import numpy as np
import pandas as pd
from pandas import Series, DataFrame
我们可以调整数据输出框大小以便观察:
pd.set_option('display.width', 200)
一、创建对象
1 、可以通过传递一个 list 对象来创建一个 Series , pandas 会默认创建整型索引:
s = pd.Series([1,3,5,np.nan,6,8])
s
0 1
1 3
2 5
3 NaN
4 6
5 8
dtype: float64dates = pd.date_range(‘20130101’, periods=6)
2 、通过传递一个 numpy array ,时间索引以及列标签来创建一个 DataFrame :
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
dates
df
DatetimeIndex([‘2013-01-01’, ‘2013-01-02’, ‘2013-01-03’, ‘2013-01-04’,
‘2013-01-05’, ‘2013-01-06’],
dtype=‘datetime64[ns]’, freq=‘D’)
A B C D
2013-01-01 -1.857957 -0.297110 0.135704 0.199878
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
2013-01-06 0.186073 -0.537019 -0.252442 0.530238
3 、通过传递一个能够被转换成类似序列结构的字典对象来创建一个 DataFrame :
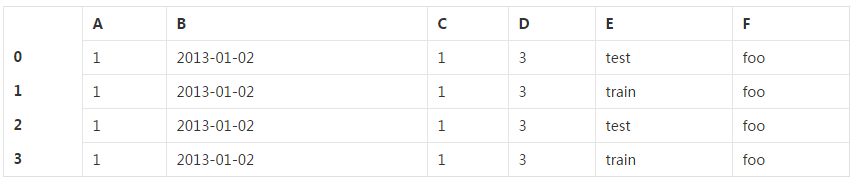
df2 = pd.DataFrame({'A':1.,
'B':pd.Timestamp('20130102'),
'C':pd.Series(1, index=list(range(4)),dtype='float32'),
'D':np.array([3] * 4, dtype='int32'),
'E':pd.Categorical(['test','train', 'test','train']),
'F':'foo'
})
df2
4 、查看不同列的数据类型:
df2.dtypes
A float64
B datetime64[ns]
C float32
D int32
E category
F object
dtype: object
5 、使用 Tab 自动补全功
二、查看数据
1.查看 Frame 中头部和尾部的行:能会自动识别所有的属性以及自定义的列
df.head()
A B C D
2013-01-01 -1.857957 -0.297110 0.135704 0.199878
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
df.tail(3)
A B C D
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
2013-01-06 0.186073 -0.537019 -0.252442 0.530238
2 、显示索引、列和底层的 numpy 数据:
df.index
DatetimeIndex([‘2013-01-01’, ‘2013-01-02’, ‘2013-01-03’, ‘2013-01-04’,
‘2013-01-05’, ‘2013-01-06’],
dtype=‘datetime64[ns]’, freq=‘D’)
df.columns
Index([‘A’, ‘B’, ‘C’, ‘D’], dtype=‘object’)
3 、 describe()函数对于数据的快速统计汇总:
df.describe()
A B C D
count 6.000000 6.000000 6.000000 6.000000
mean -0.256300 0.103596 0.283858 0.158536
std 0.854686 1.060269 1.181208 0.973309
min -1.857957 -1.211098 -1.031190 -1.295228
25% -0.412452 -0.477042 -0.429298 -0.395927
50% 0.162550 -0.158711 -0.058369 0.365058
75% 0.214610 0.747641 0.911070 0.630084
max 0.367213 1.683491 2.169802 1.447487
4 、对数据的转置(tranverse):
df.T
2013-01-01 2013-01-02 2013-01-03 2013-01-04 2013-01-05 2013-01-06
00:00:00 00:00:00 00:00:00 00:00:00 00:00:00 00:00:00
A -1.857957 0.139027 -0.596279 0.367213 0.224122 0.186073
B -0.297110 1.683491 -1.211098 -0.020313 1.003625 -0.537019
C 0.135704 -1.031190 1.169525 2.169802 -0.488250 -0.252442
D 0.199878 1.447487 0.663366 -1.295228 -0.594528 0.530238
5 、按轴进行排序:
df.sort_index(axis=1,ascending=False)
D C B A
2013-01-01 0.199878 0.135704 -0.297110 -1.857957
2013-01-02 1.447487 -1.031190 1.683491 0.139027
2013-01-03 0.663366 1.169525 -1.211098 -0.596279
2013-01-04 -1.295228 2.169802 -0.020313 0.367213
2013-01-05 -0.594528 -0.488250 1.003625 0.224122
2013-01-06 0.530238 -0.252442 -0.537019 0.186073
6 、按值进行排序:
df.sort(columns='B')
A B C D
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
2013-01-06 0.186073 -0.537019 -0.252442 0.530238
2013-01-01 -1.857957 -0.297110 0.135704 0.199878
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
2013-01-02 0.139027 1.683491 -1.031190 1.447487
三、选择数据
以下是将要操作的数组:
df
A B C D
2013-01-01 -1.857957 -0.297110 0.135704 0.199878
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
2013-01-06 0.186073 -0.537019 -0.252442 0.530238
1 、获取数据
(1)、选择一个单独的列,这将会返回一个 Series:
df['A']
2013-01-01 -1.857957
2013-01-02 0.139027
2013-01-03 -0.596279
2013-01-04 0.367213
2013-01-05 0.224122
2013-01-06 0.186073
Freq: D, Name: A, dtype: float64
(2)、通过[]进行选择,即:切片
df[0:3]
A B C D
2013-01-01 -1.857957 -0.297110 0.135704 0.199878
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
2 、标签选择
(1)、使用标签来获取一个交叉的区域
df.loc[dates[0]]
A -1.857957
B -0.297110
C 0.135704
D 0.199878
Name: 2013-01-01 00:00:00, dtype: float64
(2)、通过标签来在多个轴上进行选择
df.loc[:,['A', 'B']]
A B
2013-01-01 -1.857957 -0.297110
2013-01-02 0.139027 1.683491
2013-01-03 -0.596279 -1.211098
2013-01-04 0.367213 -0.020313
2013-01-05 0.224122 1.003625
2013-01-06 0.186073 -0.537019
(3)、标签切片
df.loc['20130102':'20130104', ['A','B']]
A B
2013-01-02 0.139027 1.683491
2013-01-03 -0.596279 -1.211098
2013-01-04 0.367213 -0.020313
(4)、对于返回的对象进行维度缩减
df.loc['20130102', ['A','B']]
A 0.139027
B 1.683491
Name: 2013-01-02 00:00:00, dtype: float64
(5)、获取一个标量
df.loc[dates[0], 'A']
-1.8579571971312099
3 、位置选择
(1)、通过传递数值进行位置选择(选择的是行)
df.iloc[3]
A 0.367213
B -0.020313
C 2.169802
D -1.295228
Name: 2013-01-04 00:00:00, dtype: float64
(2)、通过数值进行切片
df.iloc[3:5,0:2]
A B
2013-01-04 0.367213 -0.020313
2013-01-05 0.224122 1.003625
(3)、通过指定一个位置的列表
df.iloc[[1,2,4],[0,2]]
A C
2013-01-02 0.139027 -1.031190
2013-01-03 -0.596279 1.169525
2013-01-05 0.224122 -0.488250
(4)、对行进行切片
df.iloc[1:3,:]
A B C D
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-03 -0.596279 -1.211098 1.169525 0.663366
(5)、获取特定的值
df.iloc[1,1]
1.6834910794696132
4 、布尔索引
(1)、使用一个单独列的值来选择数据:
df[df.A > 0]
A B C D
2013-01-02 0.139027 1.683491 -1.031190 1.447487
2013-01-04 0.367213 -0.020313 2.169802 -1.295228
2013-01-05 0.224122 1.003625 -0.488250 -0.594528
2013-01-06 0.186073 -0.537019 -0.252442 0.530238
(2)、使用 where 操作来选择数据:
df[df > 0]
A B C D
2013-01-01 NaN NaN 0.135704 0.199878
2013-01-02 0.139027 1.683491 NaN 1.447487
2013-01-03 NaN NaN 1.169525 0.663366
2013-01-04 0.367213 NaN 2.169802 NaN
2013-01-05 0.224122 1.003625 NaN NaN
2013-01-06 0.186073 NaN NaN 0.530238
(3)、使用 isin()方法来过滤:
df2 = df.copy()
df2['E'] = ['one', 'one', 'two', 'three', 'four', 'three']
df2
A B C D E
2013-01-01 -1.857957 -0.297110 0.135704 0.199878 one
2013-01-02 0.139027 1.683491 -1.031190 1.447487 one
2013-01-03 -0.596279 -1.211098 1.169525 0.663366 two
2013-01-04 0.367213 -0.020313 2.169802 -1.295228 three
2013-01-05 0.224122 1.003625 -0.488250 -0.594528 four
2013-01-06 0.186073 -0.537019 -0.252442 0.530238 three
df2[df2['E'].isin(['two', 'four'])]
A B C D E
2013-01-03 -0.596279 -1.211098 1.169525 0.663366 two
2013-01-05 0.224122 1.003625 -0.488250 -0.594528 four
5 、设置
(1)、设置一个新的列:
s1 = pd.Series([1,2,3,4,5,6], index=pd.date_range('20130102', periods=6))
s1
2013-01-02 1
2013-01-03 2
2013-01-04 3
2013-01-05 4
2013-01-06 5
2013-01-07 6
Freq: D, dtype: int64
df['F'] = s1
df
A B C D F
2013-01-01 0.000000 0.000000 0.135704 5 NaN
2013-01-02 0.139027 1.683491 -1.031190 5 1
2013-01-03 -0.596279 -1.211098 1.169525 5 2
2013-01-04 0.367213 -0.020313 2.169802 5 3
2013-01-05 0.224122 1.003625 -0.488250 5 4
2013-01-06 0.186073 -0.537019 -0.252442 5 5
(2)、设置新值
df.at[dates[0],'A'] = 0 #通过标签设置新值
df.iat[0,1] = 0 #通过位置设置新值
df.loc[:, 'D'] = np.array([5] * len(df)) #通过一个 numpy 数值设置一组新值
df
A B C D F
2013-01-01 0.000000 0.000000 0.135704 5 NaN
2013-01-02 0.139027 1.683491 -1.031190 5 1
2013-01-03 -0.596279 -1.211098 1.169525 5 2
2013-01-04 0.367213 -0.020313 2.169802 5 3
2013-01-05 0.224122 1.003625 -0.488250 5 4
2013-01-06 0.186073 -0.537019 -0.252442 5 5
四、缺失值处理
在 pandas 中,使用 np.nan 来代替缺失值,这些值将默认不会包含在计算中。所处理的数组是:
df
A B C D F
2013-01-01 0.000000 0.000000 0.135704 5 NaN
2013-01-02 0.139027 1.683491 -1.031190 5 1
2013-01-03 -0.596279 -1.211098 1.169525 5 2
2013-01-04 0.367213 -0.020313 2.169802 5 3
2013-01-05 0.224122 1.003625 -0.488250 5 4
2013-01-06 0.186073 -0.537019 -0.252442 5 5
1 、 reindex()方法可以对指定轴上的索引进行改变 /增加 /删除操作,这将返回原始数据的一个拷贝:
df1 = df.reindex(index=dates[0:4],columns=list(df.columns) + ['E'])
df1.loc[dates[0]:dates[1], 'E'] = 1
df1
A B C D F E
2013-01-01 0.000000 0.000000 0.135704 5 NaN 1
2013-01-02 0.139027 1.683491 -1.031190 5 1 1
2013-01-03 -0.596279 -1.211098 1.169525 5 2 NaN
2013-01-04 0.367213 -0.020313 2.169802 5 3 NaN
2 、去掉包含缺失值的行:
df1.dropna(how='any')
A B C D F E
2013-01-02 0.139027 1.683491 -1.03119 5 1
1
3 、对缺失值进行填充:
df1.fillna(value=5)
A B C D F E
2013-01-01 0.000000 0.000000 0.135704 5 5 1
2013-01-02 0.139027 1.683491 -1.031190 5 1 1
2013-01-03 -0.596279 -1.211098 1.169525 5 2 5
2013-01-04 0.367213 -0.020313 2.169802 5 3 5
4 、对数据进行布尔填充:
pd.isnull(df1)
A B C D F E
2013-01-01 False False False False True False
2013-01-02 False False False False False False
2013-01-03 False False False False False True
2013-01-04 False False False False False True
五、合并
pandas 提供了大量的方法能够轻松的对 Series 、 DataFrame 和 Panel 对象进行各种符合各种逻辑关系的合并操作。
1 、 Concat
df = pd.DataFrame(np.random.randn(10, 4))
df
0 1 2 3
0 0.680581 1.918851 0.521201 -0.389951
1 0.724157 2.282989 0.648427 -0.827308
2 2.437781 0.232518 1.066197 -0.233117
3 0.038747 3.174875 -1.384120 0.322864
4 -0.835962 1.015841 0.042094 -1.903701
5 0.095194 1.926612 0.512825 0.786349
6 -1.098231 -0.669381 -0.623124 -0.411114
7 -1.229527 -0.738026 0.453683 -2.037488
8 -0.499546 -0.816864 -0.395079 -0.320400
9 0.850367 1.047287 -1.205815 -1.287821
pieces = [df[:3], df[3:7], df[7:]]
# break it into pieces
pieces
[ 0 1 2 3
0 0.680581 1.918851 0.521201 -0.389951
1 0.724157 2.282989 0.648427 -0.827308
2 2.437781 0.232518 1.066197 -0.233117,
0 1 2 3
3 0.038747 3.174875 -1.384120 0.322864
4 -0.835962 1.015841 0.042094 -1.903701
5 0.095194 1.926612 0.512825 0.786349
6 -1.098231 -0.669381 -0.623124 -0.411114,
0 1 2 3
7 -1.229527 -0.738026 0.453683 -2.037488
8 -0.499546 -0.816864 -0.395079 -0.320400
9 0.850367 1.047287 -1.205815 -1.287821]
2 、 Append 将一行连接到一个 DataFrame 上
df = pd.DataFrame(np.random.randn(8, 4), columns=['A', 'B', 'C', 'D'])
df
A B C D
0 -0.923050 -1.798683 -0.543700 0.983715
1 -0.031082 1.069746 -0.761914 0.142136
2 0.178376 -0.984427 0.270601 0.737754
3 -0.882595 0.057637 -1.027661 -1.829378
4 0.570082 0.210366 0.805305 -1.233238
5 0.442322 0.709155 -0.304849 0.885378
6 -0.218852 0.052263 0.467727 0.832747
7 0.516890 0.005642 -0.990794 -1.624444
s = df.iloc[3]
df.append(s, ignore_index=True)
A B C D
0 -0.923050 -1.798683 -0.543700 0.983715
1 -0.031082 1.069746 -0.761914 0.142136
2 0.178376 -0.984427 0.270601 0.737754
3 -0.882595 0.057637 -1.027661 -1.829378
4 0.570082 0.210366 0.805305 -1.233238
5 0.442322 0.709155 -0.304849 0.885378
6 -0.218852 0.052263 0.467727 0.832747
7 0.516890 0.005642 -0.990794 -1.624444
8 -0.882595 0.057637 -1.027661 -1.829378
以上代码不想自己试一试吗?
镭矿 raquant提供 jupyter 在线练习学习 python 的机会,无需安装 python 即可运行 python 程序。
Python 数据分析之 pandas 进阶(一)如何使用

帖子标题“Python 数据分析之 pandas 进阶(一)如何使用”看起来像是一个系列教程的标题,而不是一个具体的技术问题。它没有指明具体的“如何使用”是针对哪个功能或场景。
从标题本身,我无法判断你想问什么。你是想了解:
- 如何开始使用pandas进行进阶数据分析?
- 某个特定的进阶功能(如
groupby、merge、时间序列、窗口函数等)如何使用? - 还是其他什么?
请提供更具体的问题,例如:
- “pandas中
groupby().apply()方法怎么用,能举个例子吗?” - “如何用pandas高效地合并多个具有复杂键的DataFrame?”
- “
pd.Grouper在时间序列分组中具体怎么应用?”
这样我才能给你提供专业、直接、可运行的代码示例或精炼的核心解答。
一句话建议:请明确你的具体问题点。

