




Python云服务器如何搭建爬虫环境
收录待用,明天开始 Python 日记计划,修改转载已取得腾讯云授权
假设你已经在云服务器上搭建好了 Python 环境,我们将进入下一步:搭建 Python 爬虫环境。
一直在终端编写 Python 爬虫是不现实的,除非你在学习阶段,当我们要正式开始编写爬虫的时候我们理所应当的需要一个爬虫环境了。
第一部分:搭建爬虫环境
考虑到学习、使用便捷,我们将使用 Sublime Text3 开发爬虫:https://www.sublimetext.com/3 ,进入 Sublime Text3 官网,按照你的系统下载相应的版本,我这里下载的是 Windows 64 位的。

下载好之后,安装 setup
Next
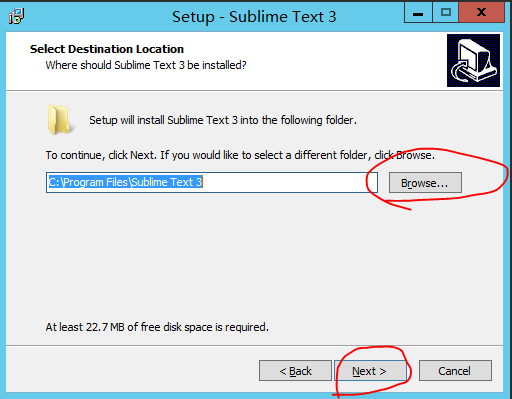
选择安装目录,点击 next
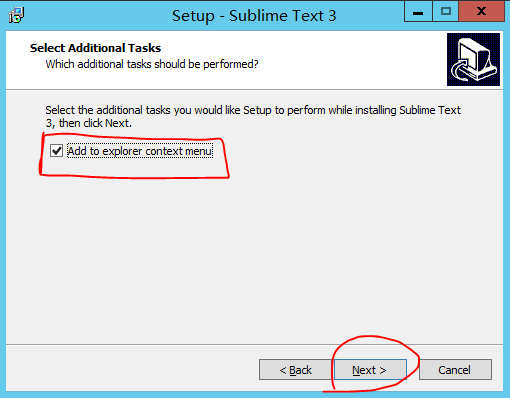
勾选上:Add to explorer contect menu ,点击 next ,最后点击 Installer/Finish ,安装完成。安装完成之后到你之前配置的安装目录打开 Sublime Text3 ,你也可以复制一个快捷方式到桌面方便以后使用。
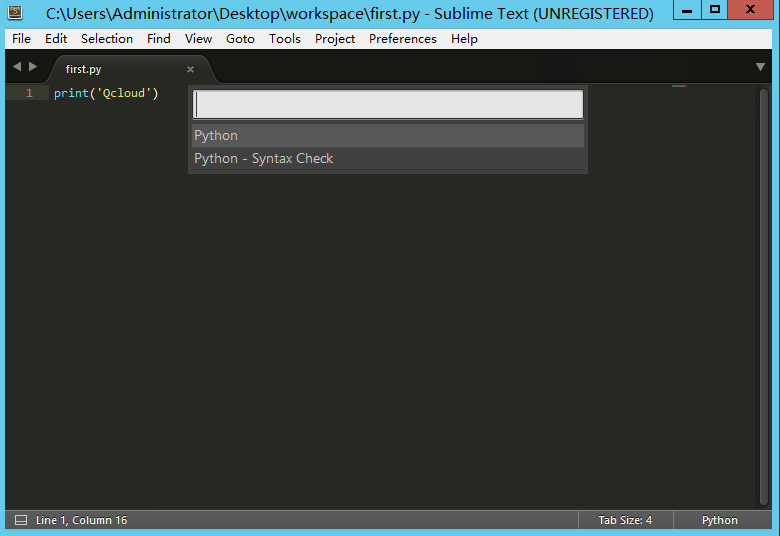
现在你就可以使用 Sublime Text 来编写 Python 了,如若有什么不懂的地方可以访问 Sublime Text 的官网查看文档。编写完 Python 代码之后, F7 运行 Python 脚本,第一次运行的时候会出现以下界面,选择的一个行的 Python 即可。
第二部分:学会安装 Python 库
Python 适合做爬虫是因为:有无数的开源作者无私的在 Python 开源社区做贡献,强大的 Python 库为我们提供了很多便捷的操作。有三种方法安装 Python 库,具体方法可以访问:http://blog.csdn.net/jerry_1126/article/details/46574045
Python 中绝大部分的库都可以使用 pip 进行安装, pip 也是最简单的安装方法,使用 pip 安装第三方库只需要使用命令: pip install + 库名,比如我需要安装一个叫 bs4 的库,我只需要在终端执行 pip install bs4
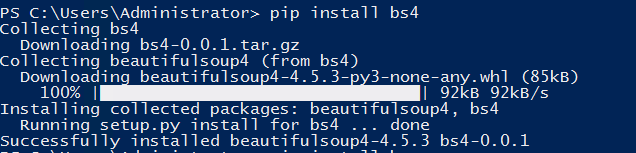
出现: Successfully collected packages:则表示安装成功。
第三部分:你不得不知的 Python 库
在编写爬虫的时候我们可能需要以下一些比较常用的库,这里我们做一个简单的介绍,方便后续的使用。
1 、 Requests Requests 是用 Python 语言编写,基于 urllib ,采用 Apache2 Licensed 开源协议的 HTTP 库。它比 urllib 更加方便,可以节约我们大量的工作,完全满足 HTTP 测试需求。 Requests 的哲学是以 PEP 20 的习语为中心开发的,所以它比 urllib 更加 Pythoner
安装命令: pip install resquests
2 、 Beautifulsoup4 Beautiful Soup 提供一些简单的、 python 式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序
安装命令: pip install bs4
3 、 Lxml python lxml 包用于解析 XML 和 html 文件,可以使用 xpath 和 css 定位元素
安装方法: pip install lxml
第四部分:寻找你需要的 Python 库
当以上库不能满足你需求的时候,你就需要学会自己寻找 Python 库了。首先访问一个 git 项目:https://github.com/vinta/awesome-python
在这个项目中,作者把所有的 Python 资源包括库资源等分成了几十个大类:数据挖掘、数据可视化、日期和时间处理、数据库相关……等等,在每个大类中归类了该类下的所有资源,并且该资源的首页有各个大类的索引。
在这个大背景之下,假设我现在想找一个 Python 操作 MongoDB 的库,我们就首先点击最上面的索引: Database Drivers 直接跳转到数据库相关库的地方。
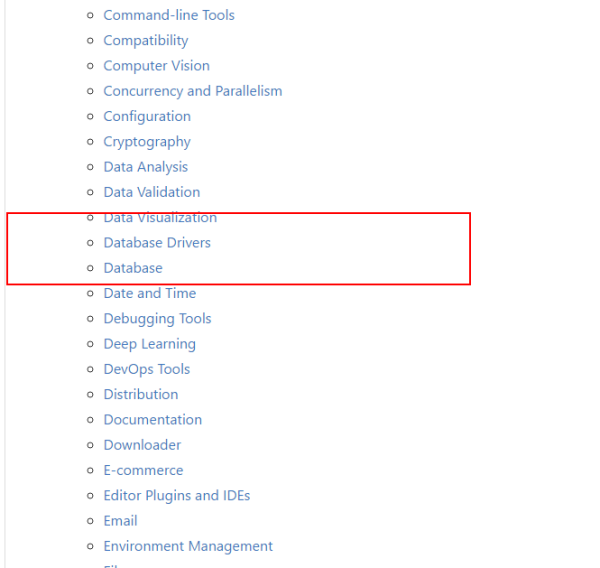
跳转之后,如下界面,我们就可以直接寻找到我们需要的库了。
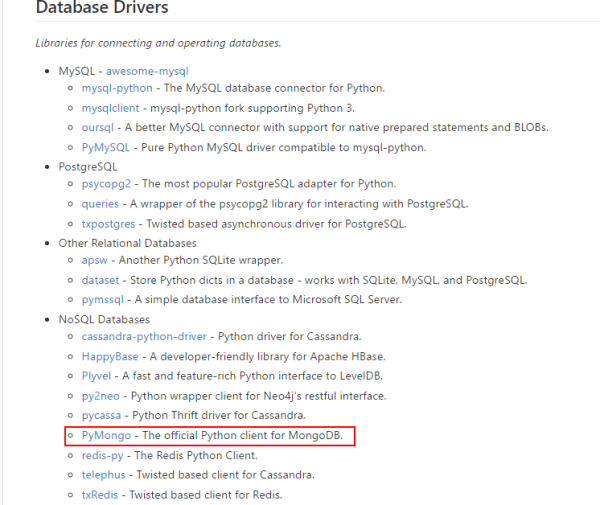
当然,因为所有的资源都在同一个页面,所以我们同时可以使用浏览器自带的搜索功能,在 Chrome 下是 Ctrl+F12 ,在该页面直接搜我们需要的某个功能关键词,比如: MongoDB ,
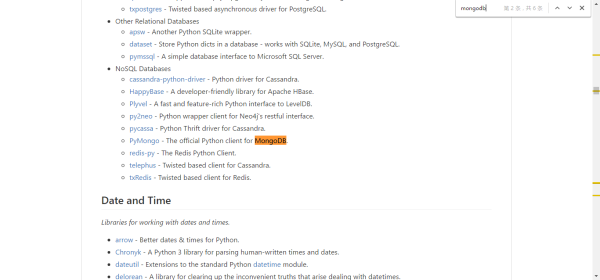
当然,这样搜索出来的结果可能不仅仅是一条,就需要你自己排查以下哪一个才是你真正那个需要的库资源了。
原文来自: https://www.qcloud.com/community/user/635207001488413960
Python云服务器如何搭建爬虫环境

帖子回复:
要搭建一个Python爬虫环境,核心是安装必要的库和配置运行环境。这里给你一个完整的方案:
# 1. 首先更新系统并安装Python3和pip
# Ubuntu/Debian系统:
sudo apt update
sudo apt install python3 python3-pip python3-venv -y
# CentOS/RHEL系统:
sudo yum update
sudo yum install python3 python3-pip -y
# 2. 创建虚拟环境(推荐)
python3 -m venv spider_env
source spider_env/bin/activate
# 3. 安装核心爬虫库
pip install requests beautifulsoup4 lxml scrapy selenium
# 4. 如果需要处理JavaScript渲染的页面
# 安装Chrome驱动(以Ubuntu为例):
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo dpkg -i google-chrome-stable_current_amd64.deb
sudo apt-get install -f
# 安装对应的ChromeDriver
wget https://chromedriver.storage.googleapis.com/latest/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
sudo mv chromedriver /usr/local/bin/
# 5. 验证安装
python3 -c "import requests, bs4, scrapy; print('环境安装成功!')"
关键点说明:
requests:HTTP请求库,最常用的爬虫基础库beautifulsoup4+lxml:HTML解析组合scrapy:专业爬虫框架,适合大型项目selenium:处理JavaScript动态加载的页面- 虚拟环境能隔离项目依赖,避免版本冲突
简单建议: 根据你的爬虫需求选择合适的工具组合。