




Python爬虫如何扒下bilibili视频信息
从今天开始一步步完成 Python 日记计划,和 Python 相关的收录待用,修改转载已取得腾讯云授权
在以上两篇文章中我们已经在腾讯云服务器上搭建好了 Python 爬虫环境了,下一步就是在云服务器上爬上我们的爬虫,抓取我们想要的数据: [腾讯云的 1001 种玩法] 云服务器搭建 Python 环境 [腾讯云的 1001 种玩法] 云服务器搭建 Python 爬虫环境
今天我们要抓去的目标网站是,国内最大的年轻人潮流文化娱乐社区:哔哩哔哩 - ( ゜- ゜)つロ 干杯~ - bilibili B 站自建站以来已经收纳了大约六百多万的视频,那么今天我们就写一个爬虫去征服这六百多万条视频信息。
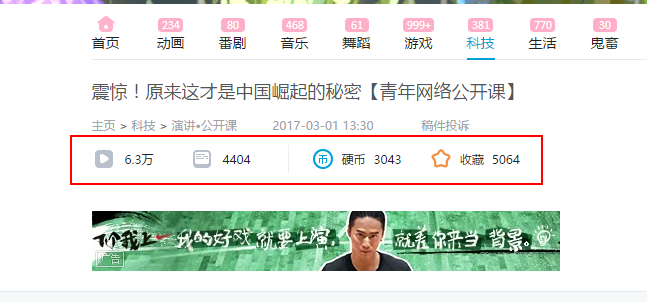
我们想抓取的就是上面的播放次数、评论数量、硬币数量以及收藏数量,接着我们开始。
1 、先分析
首先第一步这些数据在哪里?我们第一个想到的就是在网页源码里面,于是我们查看源码,搜索相关信息。

遗憾的是我们会发现,信息并不在源码中;紧接着我们打开 chrome 开发者工具查看请求信息。
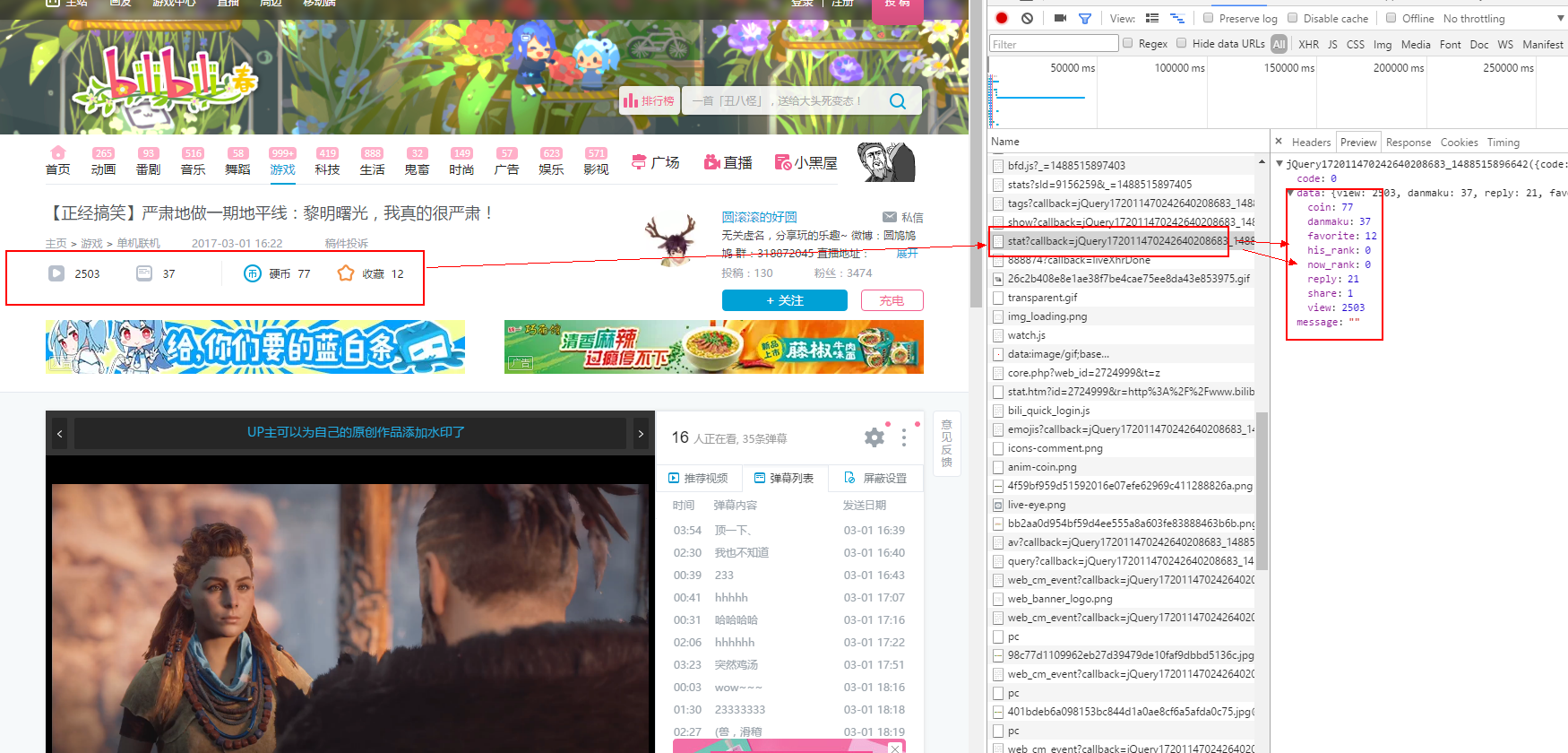
我们可以对以上的 url 进行修剪,删除一些不是必须要的参数。我们先观察这个 url , aid 是这个视频的 id 唯一标识不能删除,我们可以先把其余的参数都删掉试试看,如果不成功我们在一一加参数测试。
http://api.bilibili.com/archive_stat/stat?aid=8904657

显然,删除了非必要参数之后对内容毫无影响,所以我们只需要知道每个视频的 aid 就可以抓取所有的视频信息了。那么 B 站的视频 aid 是怎么编号的呢?我们可以多观察以下 aid 会发现这个 aid 是一个自动增长的主键,从 1 开始递增。于是我们代码思路有就了。
2 、写代码
使用 requests 库来请求获取数据,并使用 Python 的内置库 Json 来提取数据。
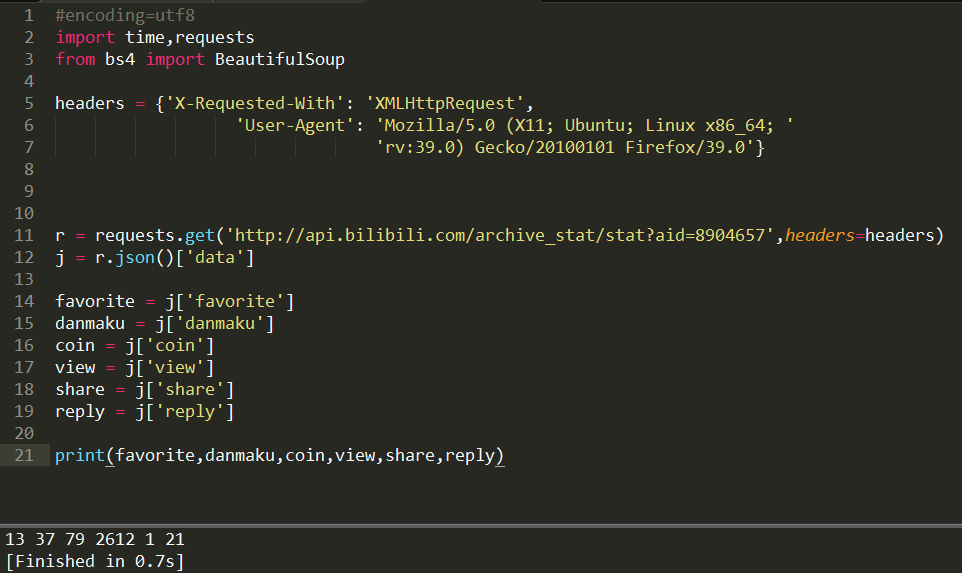
现在已经可以抓取单个视频信息了,让你的小爬虫遍历整个 B 站的视频。
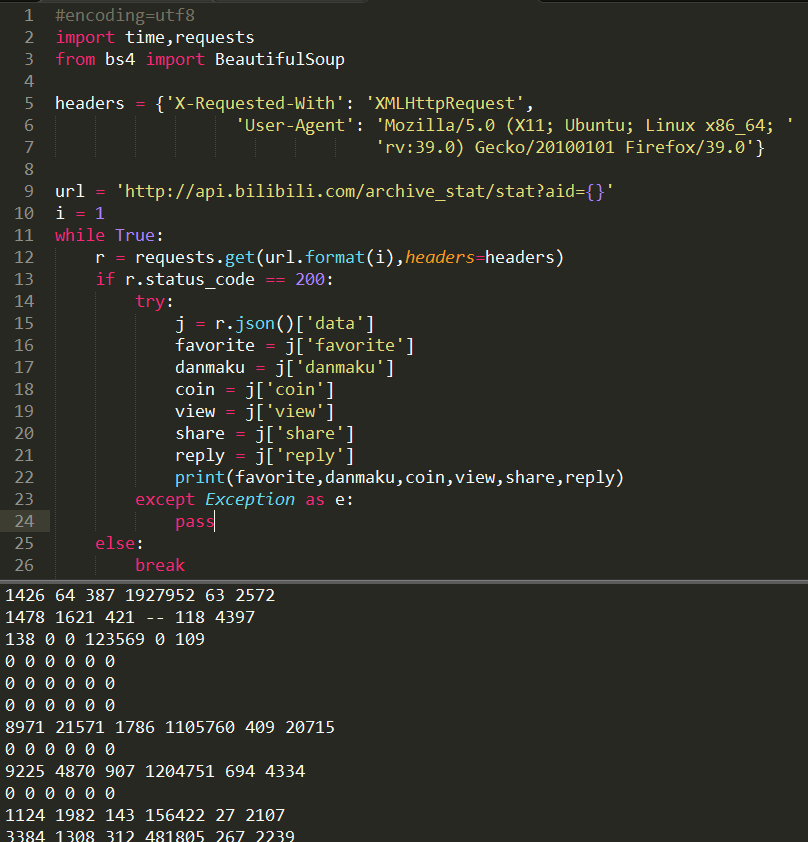
现在你只需要把你的爬虫一直开在服务器上就 ok 了。
原文来自: https://www.qcloud.com/community/user/635207001488413960
Python爬虫如何扒下bilibili视频信息

要扒B站视频信息,用requests+BeautifulSoup或者官方API都行。最简单的是用官方API,稳定又省事。
import requests
import json
def get_bilibili_video_info(bvid):
"""
通过BV号获取B站视频信息
bvid: 视频BV号,如'BV1xx411c7mD'
"""
# API接口
url = f"https://api.bilibili.com/x/web-interface/view?bvid={bvid}"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36',
'Referer': 'https://www.bilibili.com'
}
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
data = response.json()
if data['code'] == 0:
info = data['data']
video_info = {
'title': info['title'],
'author': info['owner']['name'],
'view_count': info['stat']['view'],
'like_count': info['stat']['like'],
'coin_count': info['stat']['coin'],
'favorite_count': info['stat']['favorite'],
'danmaku_count': info['stat']['danmaku'],
'reply_count': info['stat']['reply'],
'share_count': info['stat']['share'],
'pub_date': info['pubdate'],
'duration': info['duration'],
'description': info['desc']
}
return video_info
else:
print(f"获取失败: {data['message']}")
return None
except requests.exceptions.RequestException as e:
print(f"请求出错: {e}")
return None
except json.JSONDecodeError as e:
print(f"JSON解析出错: {e}")
return None
# 使用示例
if __name__ == "__main__":
# 替换成你要获取的视频BV号
bvid = "BV1xx411c7mD" # 示例BV号
result = get_bilibili_video_info(bvid)
if result:
print("视频信息获取成功:")
for key, value in result.items():
print(f"{key}: {value}")
else:
print("获取视频信息失败")
这个代码用了B站官方的API接口,通过BV号就能拿到视频标题、作者、播放量、点赞数这些基本信息。headers里加了User-Agent和Referer是为了模拟浏览器请求,避免被反爬。
如果你需要更多数据,比如分P信息、视频流地址,可以看看API返回的完整数据结构,里面东西挺全的。记得用的时候把BV号换成你要扒的视频的实际BV号。
用官方API最稳当。

