




Golang如何根据一个或两个条件快速排序自定义类型切片
Golang如何根据一个或两个条件快速排序自定义类型切片
我需要尽可能快地对自定义类型的切片进行排序。
为了概括这个问题,我有一个切片 points,定义如下:
type point struct {
x float64
y int32
}
var points []point
现在,我需要根据用户输入,要么按字段 x 对切片进行排序,要么先按字段 y 再按 x 进行排序。
我在多个地方读到 sort.Interface 的性能优于 sort.Slice,因此我按如下方式实现按 x 排序:
type Slice struct {
sort.Interface
idx []int
}
func (s Slice) Swap(i, j int) {
s.Interface.Swap(i, j)
s.idx[i], s.idx[j] = s.idx[j], s.idx[i]
}
func NewSlice(n sort.Interface) *Slice {
s := &Slice{Interface: n, idx: make([]int, n.Len())}
for i := range s.idx {
s.idx[i] = i
}
return s
}
func NewFloat64Slice(n ...float64) *Slice {
return NewSlice(sort.Float64Slice(n))
}
/// in main
var S *Slice
xx := make([]float64, len(points))
for v := range points {
xx[v] = points[v].x
}
S = NewFloat64Slice(xx...)
sort.Sort(S)
sortedbyX := make([]point, len(points))
for j, i := range S.idx {
sortedbyX[j] = points[i]
}
或者,按 y 然后按 x 排序:
type byYX []point
func (pnts byYX) Len() int { return len(pnts) }
func (pnts byYX) Swap(i, j int) { pnts[i], pnts[j] = pnts[j], pnts[i] }
func (pnts byYX) Less(i, j int) bool {
if pnts[i].y == pnts[j].y {
return pnts[i].x < pnts[j].x
} else {
return pnts[i].y < pnts[j].y
}
}
func NewCSlice(n ...point) *Slice {
return NewSlice(byYX(n))
}
/// in main
S = NewCSlice(points...)
sort.Sort(S)

这是一个包含一些真实数据的完整示例(有人可能会注意到切片 xs 已经排序,但这只是一个虚拟数据集,在我的应用程序中永远不会发生这种情况)。
我现在想知道这是否确实是排序的最快方法,或者是否有更好的方法。 有什么建议吗?
更多关于Golang如何根据一个或两个条件快速排序自定义类型切片的实战教程也可以访问 https://www.itying.com/category-94-b0.html

抱歉,如果我没说清楚。我更感兴趣的是了解我的代码是否符合 Go 语言的惯用法,以及我所编写的代码是否可以有更好、更快或更高效的实现方式,这与底层的排序算法无关。
题外话,我读到从 Go 1.9 开始,快速排序已被 pdqsort 取代。还在某处读到有一个更快的算法,但想不起名字了……
更多关于Golang如何根据一个或两个条件快速排序自定义类型切片的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

你好,Pisistrato,
如果你希望根据性能要求来实现,那么你或许应该自己实现已知的算法。算法的选择应取决于你的数据集。

冒泡排序
冒泡排序,有时也被称为下沉排序,是一种简单的排序算法。它反复遍历输入列表中的每个元素,比较当前元素与其后的元素,并在需要时交换它们的值。重复进行这种遍历,直到某次遍历中没有发生任何交换,这意味着列表已经完全排序。该算法是一种比较排序,因其较大的元素会“冒泡”到列表顶部的方式而得名。 这个…

快速排序
快速排序是一种原地排序算法。由英国计算机科学家托尼·霍尔于1959年开发并在1961年发表,至今仍是一种常用的排序算法。如果实现得当,它可以比归并排序稍快,大约比堆排序快两到三倍。[存在争议] 快速排序是一种分治算法。它的工作原理是从数组中选择一个“枢轴”元素,然后将其他元素划分为两个子数组,根据它们是小于…

插入排序
插入排序是一种简单的排序算法,它通过比较一次构建一个最终排序的数组(或列表)。对于大型列表,它的效率远低于更高级的算法,如快速排序、堆排序或归并排序。然而,插入排序有几个优点: 当人们手动整理桥牌手牌时,大多数人使用的方法类似于插入排序。 插入排序进行迭代,每次重复消耗一个输入元素,并增长一个已排序的输出列表。A…

选择排序
在计算机科学中,选择排序是一种原地比较排序算法。它具有 O(n²) 的时间复杂度,这使得它在大型列表上效率低下,并且通常比类似的插入排序表现更差。选择排序以其简单性而著称,并且在某些情况下,特别是在辅助内存有限的情况下,比更复杂的算法具有性能优势。 该算法将输入列表分为两部分:一个从列表左端开始构建的已排序子项列表…
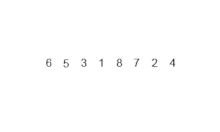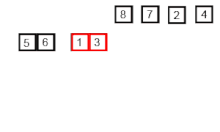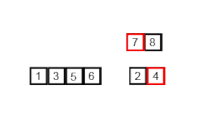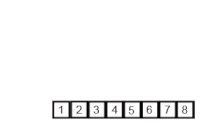
归并排序
在计算机科学中,归并排序(也常拼写为 mergesort)是一种高效、通用、基于比较的排序算法。大多数实现产生稳定的排序,这意味着相等元素的顺序在输入和输出中是相同的。归并排序是一种分治算法,由约翰·冯·诺依曼于1945年发明。自底向上归并排序的详细描述和分析早在1948年就出现在戈德斯坦和冯·诺依曼的一份报告中。 从概念上讲…
可能还有更多。
你可以根据需要排序的元素数量来选择合适的算法。 例如,快速排序的复杂度可能是 O(n*log n),这意味着它更适合处理大量数据,并且很可能在 Go 语言中被使用。冒泡排序的复杂度是 O(n²),应该永远不要使用。

对于需要高性能的自定义类型切片排序,你的实现方向是正确的。sort.Interface 确实比 sort.Slice 有更好的性能,特别是在需要多次排序的场景中,因为它避免了每次排序时都分配闭包函数。
以下是针对你需求的优化实现:
1. 单一条件排序(按 x)的优化版本
type pointsByX []point
func (p pointsByX) Len() int { return len(p) }
func (p pointsByX) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p pointsByX) Less(i, j int) bool { return p[i].x < p[j].x }
// 使用方式
func sortByX(points []point) {
sort.Sort(pointsByX(points))
}
2. 多条件排序(先 y 后 x)的优化版本
type pointsByYX []point
func (p pointsByYX) Len() int { return len(p) }
func (p pointsByYX) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p pointsByYX) Less(i, j int) bool {
if p[i].y == p[j].y {
return p[i].x < p[j].x
}
return p[i].y < p[j].y
}
// 使用方式
func sortByYX(points []point) {
sort.Sort(pointsByYX(points))
}
3. 性能对比测试示例
func benchmarkSort(b *testing.B, points []point, sortFunc func([]point)) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
// 创建副本以避免修改原始数据
testPoints := make([]point, len(points))
copy(testPoints, points)
sortFunc(testPoints)
}
}
// 测试 sort.Slice 性能
func BenchmarkSortSliceByX(b *testing.B) {
points := generateTestData(10000)
benchmarkSort(b, points, func(p []point) {
sort.Slice(p, func(i, j int) bool {
return p[i].x < p[j].x
})
})
}
// 测试 sort.Interface 性能
func BenchmarkSortInterfaceByX(b *testing.B) {
points := generateTestData(10000)
benchmarkSort(b, points, sortByX)
}
4. 内存优化的原地排序
你的原始实现中使用了额外的 idx 切片和 sortedbyX 切片,这会增加内存分配。如果不需要保留原始顺序,建议直接原地排序:
// 原地排序,无需额外内存
points := []point{{x: 1.5, y: 2}, {x: 0.5, y: 1}, {x: 2.5, y: 3}}
// 按 x 排序
sort.Sort(pointsByX(points))
// 按 y 后 x 排序
sort.Sort(pointsByYX(points))
5. 针对大型数据集的优化建议
如果处理非常大的切片(超过 10^6 个元素),可以考虑以下优化:
// 使用指针切片减少交换成本
type pointPtrs []*point
func (p pointPtrs) Len() int { return len(p) }
func (p pointPtrs) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p pointPtrs) Less(i, j int) bool {
if p[i].y == p[j].y {
return p[i].x < p[j].x
}
return p[i].y < p[j].y
}
// 使用方式
func sortPointers(points []point) []*point {
ptrs := make([]*point, len(points))
for i := range points {
ptrs[i] = &points[i]
}
sort.Sort(pointPtrs(ptrs))
return ptrs
}
6. 完整示例
package main
import (
"fmt"
"sort"
"time"
)
type point struct {
x float64
y int32
}
// 按 x 排序
type pointsByX []point
func (p pointsByX) Len() int { return len(p) }
func (p pointsByX) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p pointsByX) Less(i, j int) bool { return p[i].x < p[j].x }
// 按 y 后 x 排序
type pointsByYX []point
func (p pointsByYX) Len() int { return len(p) }
func (p pointsByYX) Swap(i, j int) { p[i], p[j] = p[j], p[i] }
func (p pointsByYX) Less(i, j int) bool {
if p[i].y == p[j].y {
return p[i].x < p[j].x
}
return p[i].y < p[j].y
}
func main() {
// 测试数据
points := []point{
{x: 3.0, y: 2},
{x: 1.5, y: 1},
{x: 2.0, y: 2},
{x: 0.5, y: 1},
}
// 按 x 排序
start := time.Now()
sort.Sort(pointsByX(points))
fmt.Printf("按 x 排序耗时: %v\n", time.Since(start))
fmt.Println("按 x 排序结果:", points)
// 按 y 后 x 排序
points = []point{
{x: 3.0, y: 2},
{x: 1.5, y: 1},
{x: 2.0, y: 2},
{x: 0.5, y: 1},
}
start = time.Now()
sort.Sort(pointsByYX(points))
fmt.Printf("按 y 后 x 排序耗时: %v\n", time.Since(start))
fmt.Println("按 y 后 x 排序结果:", points)
}
你的实现已经接近最优,主要优化点在于移除不必要的内存分配和复制操作。对于大多数应用场景,直接实现 sort.Interface 并提供原地排序是最佳选择。