




Python字符编码原理学习心得分享,搞懂原理一劳永逸
近日被 python 的编码问题卡了好几次 ><
终于静下心来看看资料, 终于懂了一丢丢.
并总结了下面这个图, 大家看看有没有问题 XD
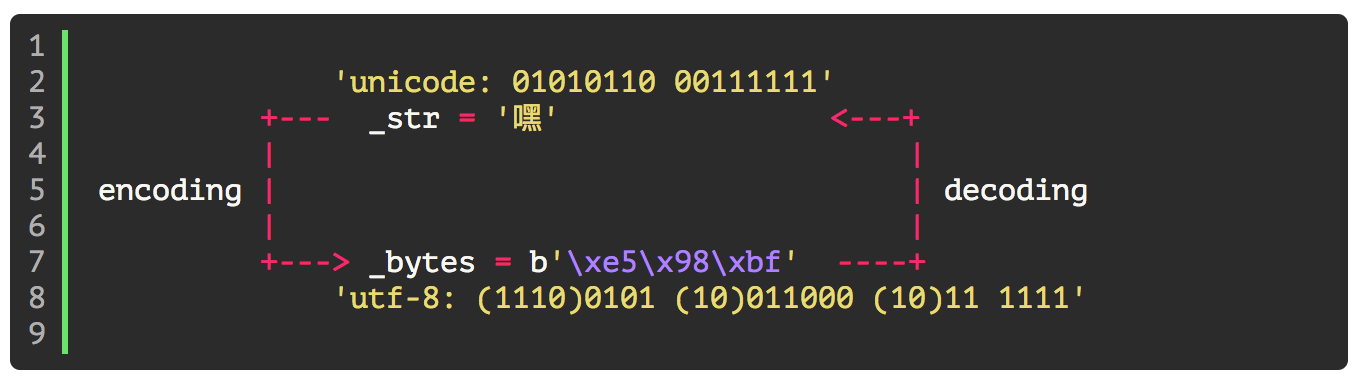
### 对这个图的解释, 我直接放我博客的链接好了:
https://changchen.me/blog/20170731/python-encoding-decoding/
- python3 str 类型
- python3 bytes 类型
- encoding/decoding
- utf-8 原理
欢迎留言提问或纠正错误哦
Python字符编码原理学习心得分享,搞懂原理一劳永逸
3 回复

我最近也在琢磨Python的字符编码,这东西确实得搞懂原理才能少踩坑。
核心就三点:字节(bytes)是计算机存储的原始数据,字符串(str)是人类可读的文本,编码(encode)和解码(decode)是两者转换的桥梁。Python3里str默认用Unicode,处理文本时不用再像Python2那样折腾。
关键要记住:在内存里用str(Unicode),存到文件或网络传输时用bytes。解码(decode)是把字节变成字符串,编码(encode)是把字符串变成字节。搞混了就会报UnicodeDecodeError或UnicodeEncodeError。
比如处理文件时:
# 读取文件(字节→字符串)
with open('file.txt', 'r', encoding='utf-8') as f:
text = f.read() # 自动解码
# 写入文件(字符串→字节)
with open('output.txt', 'w', encoding='utf-8') as f:
f.write(text) # 自动编码
网络数据通常用utf-8编码:
# 接收数据
data = b'some bytes' # 假设从网络收到字节
text = data.decode('utf-8') # 解码为字符串
# 发送数据
text = "你好"
data = text.encode('utf-8') # 编码为字节
遇到乱码多半是编解码不一致,确保读取和写入用同一种编码。处理外部数据时,先尝试用chardet检测编码,但别完全依赖它。
总结就是:内存用Unicode,存储传输用UTF-8,编解码保持一致。

