




Golang中为什么"/sched/latencies:seconds"是衡量goroutine排队延迟的高延迟指标
Golang中为什么"/sched/latencies:seconds"是衡量goroutine排队延迟的高延迟指标
摘要: 当运行 gRPC 服务器和客户端时,为什么来自 runtime/metrics 包的服务器端 goroutine 排队延迟 (/sched/latencies:seconds) 比客户端测量的实际延迟要慢得多?
描述:
在高负载下运行微服务时,平均或最大排队延迟通常用作拥塞的信号(Dagor 2018, Breakwater 2020)。我一直在尝试为 go-grpc 服务器的过载控制收集此信息。由于 goroutine 是由 Go 运行时调度的,我尝试使用 goroutine 的等待时间信息。然而,来自 /runtime/metrics 的 /sched/latencies:seconds 指标似乎存在显著延迟。我计算了第 90 百分位数和最大延迟,如图中绿色和红色的实线所示,但它总是在延迟峰值发生 0.5 秒后才报告峰值(虚线,从客户端测量的端到端延迟)。
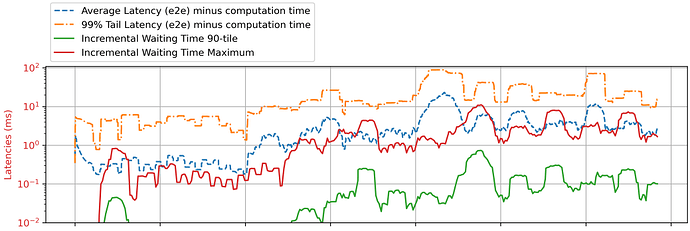
该图显示了 一个 GreetingServiceServer 实例,涉及 10 毫秒的计算(但在图中已扣除)。/sched/latencies:seconds 以 20 毫秒的间隔采样。我在第 4 秒后增加了负载,在那里你可以看到端到端延迟出现了一个峰值。
我的问题是:
- 在过载的单向 gRPC 服务器情况下,延迟发生在哪里?
/sched/latencies:seconds是衡量此排队延迟的正确指标吗? - 如上图所示,水平方向上存在巨大差距(
/sched/latencies:seconds比端到端测量晚了 0.5 秒),为什么会这样? - 有什么方法可以修复它吗?Go 语言是否有其他可用的测量方法来跟踪排队延迟?
非常感谢任何帮助!!
更多关于Golang中为什么"/sched/latencies:seconds"是衡量goroutine排队延迟的高延迟指标的实战教程也可以访问 https://www.itying.com/category-94-b0.html

嗨 @jolly,欢迎来到论坛。
我还没有使用过 runtime/metrics,所以请允许我问一个简单的问题。
在 Sample 或 Float64Histogram 的定义中,我没有看到任何挂钟时间戳。
你如何将 /sched/latencies:seconds 输出的 x 轴与客户端测量的端到端延迟对齐?
更多关于Golang中为什么"/sched/latencies:seconds"是衡量goroutine排队延迟的高延迟指标的实战系列教程也可以访问 https://www.itying.com/category-94-b0.html

好的,现在我真的完全糊涂了。
- 每20毫秒采样一次协程延迟会导致半秒的延迟,
- 但每200毫秒采样一次却能让图表完美匹配?
会不会是因为低采样率移除了细节,才让图表看起来匹配?
如果延迟不是由协程等待时间引起的,考虑到恒定的计算时间和微小的网络延迟,我不禁想知道,对于一个具有高端到端延迟的请求,延迟还可能发生在哪里?
只是一个快速的想法:如果端到端延迟是由被阻塞(例如由于I/O)的协程引起的呢?阻塞时间不会被收集在 /sched/latencies:seconds 指标中。只有在被阻塞的协程切换到可运行状态后,相应的延迟才会被测量。
但这仍然无法解释为什么这总是恰好晚半秒发生……

嗨 @christophberger,感谢你的帮助!
我的x轴上确实有时间戳,因为图表实际上是一个子图,所以被裁剪掉了。请以这个0.5延迟的图表为例。
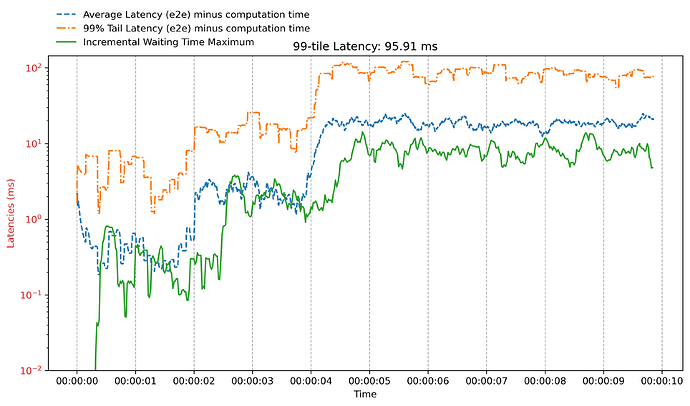
我根据我机器上的绝对时间(客户端和服务器都在我的笔记本电脑上)对它们进行对齐。在客户端,它在发送每个RPC请求时为其打上时间戳。在服务器端,我按时间间隔(例如20毫秒)采样/sched/latencies,并通过以下方法计算得到最大延迟(此图中的绿线):
// Find the maximum bucket between two Float64Histogram distributions
func maximumQueuingDelayms(earlier, later *metrics.Float64Histogram) float64 {
for i := len(earlier.Counts) - 1; i >= 0; i-- {
if later.Counts[i] > earlier.Counts[i] {
return later.Buckets[i] * 1000
}
}
return 0
}
你说得对,/sched/latencies:seconds没有挂钟时间戳,这本身就令人困惑……

Go 中的“/sched/latencies:seconds”指标提供了关于 goroutine 排队延迟的信息。它测量了从 goroutine 准备运行到它实际在处理器上开始执行之间的时间间隔。该指标值较大表明在调度 goroutine 执行时存在显著的延迟。
“/sched/latencies:seconds”指标显示 goroutine 排队延迟值较大的原因可能有以下几种:
- CPU 利用率高:如果系统负载较重或 CPU 利用率很高,由于 CPU 资源的竞争,调度 goroutine 可能会出现延迟。操作系统调度器需要将 CPU 时间分配给不同的进程和线程,如果系统不堪重负,就会导致 goroutine 执行的延迟。
- 并发执行瓶颈:如果你的应用程序有大量 goroutine 争用共享资源或同步原语(如锁或通道),则可能导致排队延迟。低效的锁定策略、过多的上下文切换或不恰当的资源管理都可能引发争用和瓶颈。
- 阻塞操作:如果 goroutine 频繁执行阻塞操作,例如等待 I/O 或网络操作,也会导致排队延迟。当一个 goroutine 被阻塞时,调度器需要切换到另一个可运行的 goroutine,并且在阻塞操作完成后,需要重新调度先前被阻塞的 goroutine,这都会增加延迟。
- 外部因素:goroutine 调度延迟也可能受到外部因素的影响,例如底层操作系统的调度策略、硬件限制,或同一系统上运行的其他进程或线程的干扰。
为了解决和缓解 goroutine 排队延迟,请考虑以下步骤:
- 分析你的代码,识别任何性能瓶颈、过度的资源争用或阻塞操作。优化你的代码以最小化争用并改进资源管理。
- 检查你的 goroutine 设计和并发模式。确保 goroutine 被高效使用,并避免不必要的阻塞操作。
- 考虑调整 goroutine 的数量或使用工作池来限制并发级别,防止过度的排队延迟。
- 使用 Go 内置的性能分析工具(例如
go tool pprof)监控和分析你的应用程序。这有助于识别代码中导致排队延迟的具体区域,并指导优化工作。 - 考虑使用其他并发原语,例如通道,来有效地协调和同步 goroutine。
goroutine 调度延迟是在 goroutine 转入运行状态时无延迟记录的。它们似乎不是图中所示延迟的原因。
我认为观察到的 goroutine 延迟与 gRPC 调用的排队延迟并不直接相关。
我非常感谢您的努力和分析!我同意您关于延迟指标是即时记录的观点。然而,我认为 /sched/latencies:seconds 的延迟与端到端延迟是相关的。
原因如下:
-
两者的时间序列趋势高度重叠。我发现,如果以较低的速率采样
/sched/latencies:seconds,垂直间隙可以消失。下图与上面 20 毫秒图的过载设置相同,但采样间隔为 200 毫秒(读取/sched/latencies:seconds)。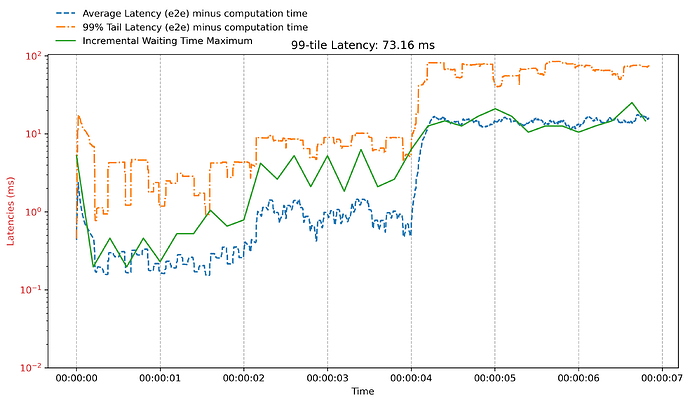 我们看到,在第二个图中,当每隔 200 毫秒查询一次
我们看到,在第二个图中,当每隔 200 毫秒查询一次 /sched/latencies:seconds时(查询是计时的,并且由独立于运行中应用程序的 goroutine 执行),它实际上完美匹配了 e2e 延迟的趋势……这个奇怪的现象在我的机器上可以复现。这表明查询/sched/latencies:seconds的频率会影响其内容。但有时它又是最新的。 -
如果在某个时间点之后,请求开始经历显著更高的端到端延迟(例如,在第 2 秒和第 4 秒开始时),那么这些请求很可能花费了更长的时间等待被处理。因此,我认为那些具有非常高端到端延迟(橙色线)的请求,正是由一些长时间等待的 goroutine(绿线)处理的请求。如果延迟不是由于 goroutine 等待时间造成的,考虑到恒定的计算时间和较小的网络延迟,我想知道对于一个具有高端到端延迟的请求,延迟还可能发生在哪里……
因此,我认为 这延迟了新 goroutine 的启动,并使它们在一段时间内保持可运行状态。 是导致高 e2e 延迟(橙色线)的直接原因,而不是其结果。这个推理合理吗?
你好 @jolly,感谢你解释这些细节。
jolly: 你说得对,
/sched/latencies:seconds没有挂钟时间戳,这本身就令人困惑……
我深入研究了 Go 的运行时代码,发现了以下内容。
/sched/latencies:seconds从sched.timeToRun读取数据:(文件runtime/metrics.go)
"/sched/latencies:seconds": {
compute: func(_ *statAggregate, out *metricValue) {
hist := out.float64HistOrInit(timeHistBuckets)
hist.counts[0] = sched.timeToRun.underflow.Load()
for i := range sched.timeToRun.counts {
hist.counts[i+1] = sched.timeToRun.counts[i].Load()
}
hist.counts[len(hist.counts)-1] = sched.timeToRun.overflow.Load()
},
timeToRun的类型是timeHistogram,它有一个record()方法,用于将一个持续时间记录到直方图中(文件runtime/histogram.go):
func (h *timeHistogram) record(duration int64) {
// omitted: calculate bucket and subBucket from duration...
h.counts[bucket*timeHistNumSubBuckets+subBucket].Add(1)
}
- 在
runtime/proc.go中,函数casgstatus()会在 goroutine 每次从等待状态切换到运行状态时调用record()来报告等待时间:
case _Grunning:
// We're transitioning into running, so turn off
// tracking and record how much time we spent in
// runnable.
gp.tracking = false
sched.timeToRun.record(gp.runnableTime)
gp.runnableTime = 0
}
因此,直方图是实时更新的,这就是它不记录时间戳的原因。
长话短说: goroutine 调度延迟是在 goroutine 转换为运行状态的瞬间,无延迟地记录的。它们似乎并不是图表中看到的延迟的原因。
我认为观察到的 goroutine 延迟与 gRPC 调用的排队延迟没有直接关联。我可以想象,那些在可运行状态花费大量时间的 goroutine 可能并不是实际处理 gRPC 请求的 goroutine。相反,这些 goroutine 启动得较晚,而此时应用程序仍在忙于处理先前请求的大量运行中的 goroutine。这延迟了新 goroutine 的启动,并使它们在可运行状态保持了一段时间。
这是一个非常好的问题,它触及了Go运行时调度器指标与应用程序级性能观测之间的核心差异。你观察到的现象是正常的,原因在于/sched/latencies:seconds指标的设计目的和测量方式。
1. 延迟发生在哪里?/sched/latencies:seconds是正确指标吗?
在过载的gRPC服务器中,延迟主要发生在两个层面:
- 网络/应用层排队:当请求到达速率超过服务处理速率时,请求会在TCP缓冲区或gRPC的HTTP/2流队列中堆积。这是你从客户端测量的端到端延迟的主要来源。
- 调度器层排队:当一个goroutine准备好运行(例如,一个gRPC handler goroutine已收到请求数据),但所有P(逻辑处理器)都忙于运行其他goroutine时,它需要在本地运行队列(LRQ)或全局运行队列(GRQ)中等待。
/sched/latencies:seconds测量的正是这个在运行队列中等待被调度执行的延迟。
它是否是正确指标? 对于调度器拥塞,是的,它是直接指标。但对于应用层整体延迟,它只是其中一个组成部分。你的图表显示,在负载激增时,应用层排队(网络/gRPC)是主要瓶颈,它发生并体现在客户端延迟中,远早于大量goroutine在调度器层面堆积。
2. 为什么存在约0.5秒的巨大水平差距?
这个差距是由指标的测量和报告机制造成的,并非错误。
/sched/latencies:seconds是一个直方图指标:它记录的是从goroutine变为可运行状态(被放入运行队列),到它开始执行之间的延迟。关键点在于,这个直方图数据是在goroutine结束等待、开始执行的那一刻被记录的。- 延迟峰值与指标报告的时序:当第4秒负载突增时,请求立即开始在gRPC层面排队,客户端延迟瞬间飙升。然而,此时服务器端的handler goroutine可能还在处理之前的请求,或者刚被创建并放入运行队列等待。这些goroutine需要等待0.5秒左右才能真正开始执行。只有当他们开始执行时,其等待时间才会被计入
/sched/latencies:seconds的直方图中。因此,这个指标反映的是历史等待时间,其峰值自然会在客户端观测到的延迟峰值之后才出现。
简单来说,客户端延迟测量的是“请求进入系统”到“收到响应”的时间,而/sched/latencies:seconds测量的是“goroutine准备好”到“它被CPU执行”的时间,后者的事件发生和记录点要晚得多。
3. 如何修复或替代测量方法?
无法“修复”这个差距,因为这是两个不同层面的测量。但你可以采用其他更直接的方法来观测应用层排队延迟:
方法A:使用runtime.Gosched()进行主动采样(更接近实时)
这种方法通过一个低优先级的监控goroutine,主动让出CPU并测量自己重新被调度的等待时间,以此来近似估算当前调度器的繁忙程度。这比sched/latencies的延迟更低。
package main
import (
"runtime"
"time"
)
func sampleSchedulingLatency(sampleInterval time.Duration) <-chan time.Duration {
ch := make(chan time.Duration)
go func() {
for {
start := time.Now()
runtime.Gosched() // 主动放弃CPU,进入运行队列末尾
// 当我们再次被调度时,测量等待时间
latency := time.Since(start)
select {
case ch <- latency:
default: // 避免监控goroutine本身阻塞
}
time.Sleep(sampleInterval)
}
}()
return ch
}
// 使用示例:在监控循环中读取
func monitor() {
latencyCh := sampleSchedulingLatency(20 * time.Millisecond)
for latency := range latencyCh {
// 处理latency,例如计算百分位数
_ = latency
}
}
方法B:测量gRPC层面的排队延迟(更贴近问题根源)
对于gRPC过载控制,你更应关注应用层队列。可以在gRPC拦截器(Interceptor)中为请求打时间戳。
package main
import (
"context"
"time"
"google.golang.org/grpc"
)
func UnaryServerInterceptor() grpc.UnaryServerInterceptor {
return func(ctx context.Context, req interface{}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (interface{}, error) {
// 1. 记录请求到达时间
arrivalTime := time.Now()
// 2. 调用实际的handler
resp, err := handler(ctx, req)
// 3. 计算排队延迟(从到达到开始处理)
// 注意:需要在handler开始时记录`processingStartTime`,这里需要额外传递
// 一种方法是将startTime放入ctx
if startTime, ok := QueueingStartTimeFromContext(ctx); ok {
queueingLatency := startTime.Sub(arrivalTime)
// 记录指标: queueingLatency
_ = queueingLatency
}
return resp, err
}
}
// 在handler开始时,需要设置开始处理的时间
func (s *GreetingServiceServer) SayHello(ctx context.Context, in *pb.HelloRequest) (*pb.HelloReply, error) {
// 记录开始处理的时间
ctx = WithQueueingStartTime(ctx, time.Now())
// ... 处理逻辑 ...
}
方法C:结合更多运行时指标进行综合判断
除了sched/latencies,还应监控其他相关指标来定位瓶颈:
/sched/goroutines:goroutines:goroutine总数。快速上涨表明任务产生速度高于消费速度。/sched/runqueue:goroutines:全局和本地运行队列的总长度。这是调度器排队的直接长度。/gc/cycles:gc-cycles和/gc/pauses:seconds:GC暂停可能导致所有goroutine短暂等待。
示例代码读取这些指标:
package main
import (
"fmt"
"runtime/metrics"
)
func readRelevantMetrics() {
// 定义需要读取的指标
sample := []metrics.Sample{
{Name: "/sched/goroutines:goroutines"},
{Name: "/sched/runqueue:goroutines"},
{Name: "/gc/cycles:gc-cycles"},
{Name: "/gc/pauses:seconds"},
}
// 读取
metrics.Read(sample)
// 打印结果
for _, s := range sample {
fmt.Printf("%s: %v\n", s.Name, s.Value)
}
}
总结
/sched/latencies:seconds是调度器层排队延迟的正确指标,但它具有固有的报告延迟,因为它记录的是goroutine开始执行时的历史等待时间。- 你观察到的0.5秒差距是正常的,因为客户端延迟峰值反映了请求进入系统时的拥塞,而
sched/latencies峰值反映了goroutine最终被调度时的拥塞,后者是前者的结果。 - 对于gRPC过载控制,建议优先在应用层(如gRPC拦截器)直接测量请求排队延迟,并结合
runtime.Gosched()采样和运行队列长度等指标进行综合决策。调度器延迟指标更适合用于诊断深层次的CPU竞争问题,而非实时过载控制。