




Python中如何逐次分别迭代多个生成器
我想先从第一个生成器取第 1 个值,从第二个生成器取第 1 个值,从第三个生成器取第 1 个值
接下来从第一个生成器取第 2 个值,从第二个生成器取第 2 个值,从第三个生成器取第 2 个值
以此类推,
最后从第一个生成器取第 5 个值,从第二个生成器取第 5 个值,从第三个生成器取第 5 个值
a = (x for x in range(1, 6))
b = (x for x in range(6, 11))
c = (x for x in range(11, 16))
d = (x for x in [a, b, c])
def y():
for m in d:
yield next(m)
for i in y():
print(i)
我想实现的输出为:
1
6
11
2
7
12
3
8
13
4
9
14
5
10
15
但是,上面的代码由于生成器只能被完整迭代一次所以在 for m in d:这个位置就会出问题。最后只能得到 1, 6, 11
请问有什么比较好的办法解决实现这个需求吗?
这个问题,是为了实现逐行对比超大 Log。我想一行一行对比 Log,但是由于三个 Log 各自都超过了 40G,因此想通过生成器的这种方式来实现。
Python中如何逐次分别迭代多个生成器

a = range(1,6)
b = range(6,11)
c = range(11,16)
def y():
----while True:
--------yield a.next()
--------yield b.next()
--------yield c.next()
for i in y():
----print(i)

在Python里同时迭代多个生成器,用zip()最直接,但要注意它会在最短的生成器耗尽时停止。如果想让所有生成器都跑完,可以用itertools.zip_longest()。
from itertools import zip_longest
def gen1():
yield from range(3)
def gen2():
yield from ['a', 'b', 'c', 'd']
# 用zip,短的停就全停
for a, b in zip(gen1(), gen2()):
print(a, b)
# 输出:
# 0 a
# 1 b
# 2 c
# 用zip_longest,长的继续,短的补None
for a, b in zip_longest(gen1(), gen2()):
print(a, b)
# 输出:
# 0 a
# 1 b
# 2 c
# None d
如果生成器数量不确定,或者想更手动地控制,可以用next()加循环处理StopIteration。
def iterate_multiple_gens(*generators):
iters = [iter(g) for g in generators]
while True:
values = []
for it in iters:
try:
values.append(next(it))
except StopIteration:
values.append(None) # 或者用其他哨兵值
if all(v is None for v in values):
break
yield tuple(values)
# 使用示例
for vals in iterate_multiple_gens(gen1(), gen2()):
print(vals)
简单说,根据你是要“对齐”迭代还是“独立”迭代到各自结束,选zip或自己写循环。



>>> a = range(1,6)
>>> b = range(6,11)
>>> c = range(11,16)
>>>
>>> d = [a.iter(),b.iter(),c.iter()]
>>>
>>> def y():
… while True:
… for m in d:
… yield next(m)
…
>>> for i in y():
… print(i)
…


➜ /tmp python3
Python 3.5.2 (default, Nov 17 2016, 17:05:23)
[GCC 5.4.0 20160609] on linux
Type “help”, “copyright”, “credits” or “license” for more information.
>>> ia = ( x for x in range (10) )
>>> ib = ( x for x in range(10) )
>>> ii = zip(ia,ib)
>>> for a,b in ii:
… print(a,b)
…
0 0
1 1
python3 里的 zip 出来的结果本身就是一个迭代器了



>>> ii = zip(range(1,6),range(6,11),range(11,16))
>>> i = iter(ii)
>>> next(i)
(1, 6, 11)
>>> next(i)
(2, 7, 12)
>>> next(i)
(3, 8, 13)
>>> next(i)
(4, 9, 14)
>>> next(i)
(5, 10, 15)
>>> next(i)
Traceback (most recent call last):
File “<stdin>”, line 1, in <module>
StopIteration


换个思路, 像这样:
—
f1 = 'file1’
f2 = 'file2’
f3 = 'file3’
def do_sth(l1, l2, l3):
…pass
with open(f1, ‘r’) as fh1, open(f2, ‘r’) as fh2, open(f3, ‘r’) as fh3:
…while True:
… f1_line = fh1.readline()
…f2_line = fh2.readline()
…f3_line = fh3.readline()
…do_sth(f1_line, f2_line, f3_line)
…if not f1_line or not f2_line or not f3_line:
…break
>>> def getwhat():
… a = ( x for x in range(1,10))
… b = ( x for x in range(15,24))
… c = zip(a,b)
… for v in c:
… for vv in v:
… yield vv
…
>>> [b for b in getwhat()]
[1, 15, 2, 16, 3, 17, 4, 18, 5, 19, 6, 20, 7, 21, 8, 22, 9, 23]
这样可以每次只返回一个

好吧,还真的是,不过这样两层迭代器嵌套也没啥意思。。
>>> ( x for x in range (10) )
<generator object <genexpr> at 0x000001F09127FFC0>

#!usr/bin/env python2.7
from itertools import izip
a = (x for x in range(1, 6))
b = (x for x in range(6, 11))
c = (x for x in range(11, 16))
ii = izip(a, b, c)
def func():
for i, (x, y, z) in enumerate(ii):
yield x
yield y
yield z
for item in func():
print item
—
izip 返回的对象是个迭代器,你看看是否合适。

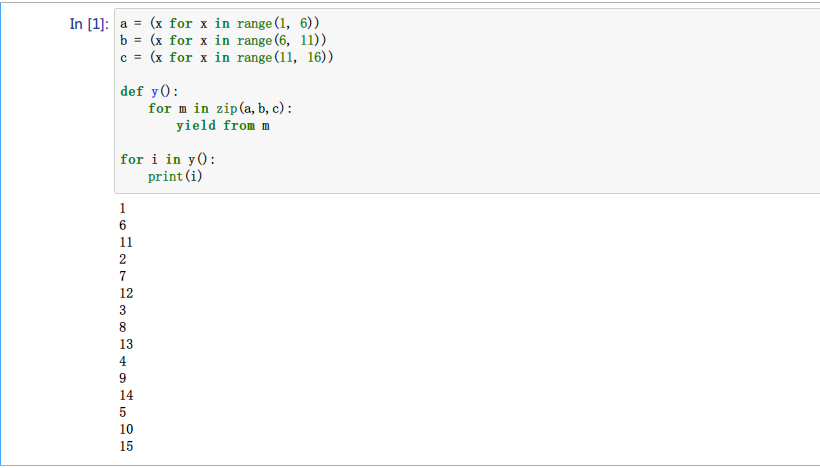
发现我在#24 楼说错了,yield from 会从生成器中挨个提取完才发挥
iter 函数调用对象的__iter__()方法; generator 是 iterator 的子类,iterator 要求实现__iter__()方法,并返回自身。所以 iter(生成器) 实际上直接返回了生成器。
另外,在#18 的基础上,如果生成器长度不同,且生成器中没有 None,可以用 filter 进行处理:python3<br>def another_roundrobin(*iterables):<br> for i in itertools.zip_longest(*iterables, fillvalue=None):<br> yield from filter(lambda x: x is not None, i)<br>
PS:itertools 文档中,Itertools Recipes 章节的 roundrobin 函数写得非常巧妙