




Python 爬虫框架 Scrapy 如何简单抓取网站数据?
python 爬虫 Scrapy 简单抓取网站数据在线实例
-
简单爬取网站数据
-
示例地址 >>> http://tool.apizl.com/dev/Scrapy/ccccd1b3db95e6688851c07de5b4935f.html
截图
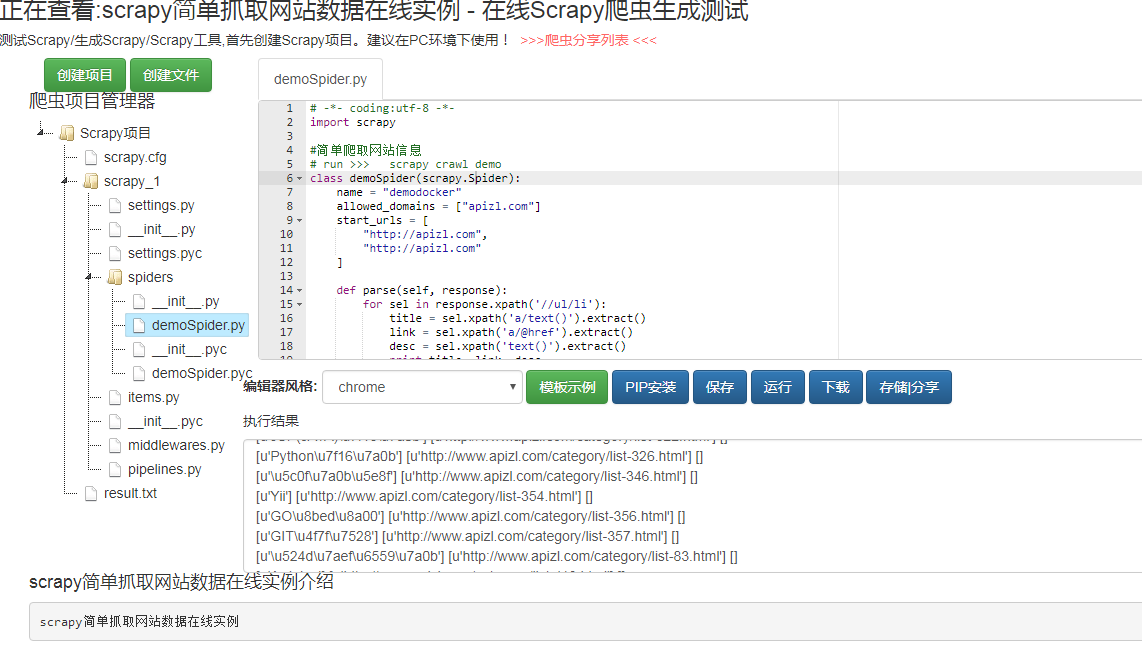
Python 爬虫框架 Scrapy 如何简单抓取网站数据?
4 回复


Scrapy基础爬虫实现示例
直接上代码,这是最简单的Scrapy爬虫模板:
import scrapy
class SimpleSpider(scrapy.Spider):
name = 'simple_spider'
start_urls = ['http://example.com'] # 替换为目标网站
def parse(self, response):
# 提取数据示例
title = response.css('h1::text').get()
paragraphs = response.css('p::text').getall()
# 返回结构化数据
yield {
'url': response.url,
'title': title,
'content': paragraphs
}
# 如果需要翻页,提取下一页链接
next_page = response.css('a.next-page::attr(href)').get()
if next_page:
yield response.follow(next_page, self.parse)
运行方式:
- 安装:
pip install scrapy - 创建项目:
scrapy startproject myproject - 在spiders目录创建上述爬虫文件
- 运行:
scrapy crawl simple_spider -o data.json
核心要点:
start_urls:起始URL列表parse方法:处理响应和提取数据- CSS选择器:
response.css()或XPath:response.xpath() yield返回字典或Request对象
选择器常用语法:
::text获取文本::attr(href)获取属性.get()获取第一个结果.getall()获取所有结果
简单来说:定义起始URL,在parse方法里用选择器提取数据,yield返回结果。

