




Python中如何编写删除重复文件的脚本
收了很多二次元图片,难免会有重复的。 写了个小脚本删除重复的。
#! /bin/env python
# -*- coding:utf-8 -*-
import sqlite3
import hashlib
import os
import sys
def md5sum(file):
md5_hash = hashlib.md5()
with open(file,“rb”) as f:
for byte_block in iter(lambda:f.read(65536),b""):
md5_hash.update(byte_block)
return md5_hash.hexdigest()
def create_hash_table():
if os.path.isfile(‘filehash.db’):
os.unlink(‘filehash.db’)
conn = sqlite3.connect(‘filehash.db’)
c = conn.cursor()
c.execute(’’‘CREATE TABLE FILEHASH
(ID INTEGER PRIMARY KEY AUTOINCREMENT,
FILE TEXT NOT NULL,
HASH TEXT NOT NULL);’’’)
conn.commit()
c.close()
conn.close()
def insert_hash_table(file):
conn = sqlite3.connect(‘filehash.db’)
c = conn.cursor()
md5 = md5sum(file)
c.execute(“INSERT INTO FILEHASH (FILE,HASH) VALUES (?,?);”,(file,md5))
conn.commit()
c.close()
conn.close()
def scan_files(dir_path):
for root,dirs,files in os.walk(dir_path):
print(‘create hash table for {} files …’.format(root))
for file in files:
filename = os.path.join(root,file)
insert_hash_table(filename)
def del_repeat_file(dir_path):
conn = sqlite3.connect(‘filehash.db’)
c = conn.cursor()
for root,dirs,files in os.walk(dir_path):
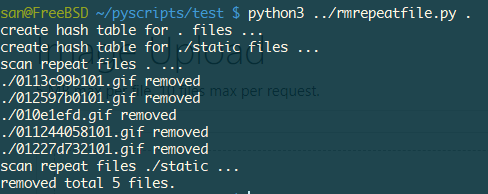
print(‘scan repeat files {} …’.format(root))
for file in files:
filename = os.path.join(root,file)
md5 = md5sum(filename)
c.execute(‘select * from FILEHASH where HASH=?;’,(md5,))
total = c.fetchall()
removed = 0
if len(total) >= 2:
os.unlink(filename)
removed += 1
print(’{} removed’.format(filename))
c.execute(‘delete from FILEHASH where HASH=? and FILE=?;’,(md5,filename))
conn.commit()
conn.close()
print('removed total {} files.'.format(removed))
def main():
dir_path = sys.argv[-1]
create_hash_table()
scan_files(dir_path)
del_repeat_file(dir_path)
if name == ‘main’:
main()
Python中如何编写删除重复文件的脚本


import os
import hashlib
from collections import defaultdict
import argparse
def get_file_hash(filepath, chunk_size=8192):
"""计算文件的MD5哈希值"""
hash_md5 = hashlib.md5()
try:
with open(filepath, "rb") as f:
for chunk in iter(lambda: f.read(chunk_size), b""):
hash_md5.update(chunk)
return hash_md5.hexdigest()
except (IOError, OSError):
return None
def find_duplicate_files(directory):
"""查找目录中的重复文件"""
# 按文件大小分组(相同大小才可能是重复文件)
size_dict = defaultdict(list)
for root, dirs, files in os.walk(directory):
for filename in files:
filepath = os.path.join(root, filename)
try:
file_size = os.path.getsize(filepath)
size_dict[file_size].append(filepath)
except OSError:
continue
# 对可能重复的文件计算哈希值
hash_dict = defaultdict(list)
for filepaths in size_dict.values():
if len(filepaths) > 1: # 只有多个文件大小相同才需要进一步检查
for filepath in filepaths:
file_hash = get_file_hash(filepath)
if file_hash:
hash_dict[file_hash].append(filepath)
# 返回真正的重复文件(哈希值相同)
duplicates = [paths for paths in hash_dict.values() if len(paths) > 1]
return duplicates
def delete_duplicates(duplicates, keep_first=True):
"""删除重复文件,默认保留第一个找到的文件"""
deleted_files = []
for file_list in duplicates:
# 确定要保留的文件
if keep_first:
keep_file = file_list[0]
delete_files = file_list[1:]
else:
# 可以修改为其他保留策略,比如保留最后修改时间最新的
keep_file = file_list[-1]
delete_files = file_list[:-1]
# 删除重复文件
for filepath in delete_files:
try:
os.remove(filepath)
deleted_files.append(filepath)
print(f"已删除: {filepath}")
except OSError as e:
print(f"删除失败 {filepath}: {e}")
return deleted_files
def main():
parser = argparse.ArgumentParser(description="查找并删除重复文件")
parser.add_argument("directory", help="要扫描的目录路径")
parser.add_argument("--dry-run", action="store_true",
help="只显示重复文件,不实际删除")
parser.add_argument("--keep-last", action="store_true",
help="保留最后一个文件(默认保留第一个)")
args = parser.parse_args()
if not os.path.isdir(args.directory):
print(f"错误: {args.directory} 不是有效目录")
return
print(f"正在扫描目录: {args.directory}")
duplicates = find_duplicate_files(args.directory)
if not duplicates:
print("未找到重复文件")
return
print(f"\n找到 {len(duplicates)} 组重复文件:")
for i, file_list in enumerate(duplicates, 1):
print(f"\n第 {i} 组 ({len(file_list)} 个文件):")
for filepath in file_list:
print(f" {filepath}")
if args.dry_run:
print("\n干运行模式:未删除任何文件")
return
if input(f"\n确认删除 {len(duplicates)} 组重复文件?(y/n): ").lower() == 'y':
keep_first = not args.keep_last
deleted = delete_duplicates(duplicates, keep_first)
print(f"\n已删除 {len(deleted)} 个重复文件")
else:
print("操作已取消")
if __name__ == "__main__":
main()
这个脚本的工作原理:
- 按大小分组:先找出大小相同的文件(不同大小的文件不可能是重复的)
- 计算哈希:对大小相同的文件计算MD5哈希值,确保内容完全相同
- 删除策略:默认保留每组重复文件中的第一个,删除其余副本
使用方法:
# 基本用法(扫描当前目录)
python deduplicate.py .
# 干运行模式(只显示不删除)
python deduplicate.py /path/to/directory --dry-run
# 保留最后一个文件
python deduplicate.py /path/to/directory --keep-last
脚本特点:
- 使用MD5哈希确保内容完全一致
- 支持递归扫描子目录
- 提供干运行模式避免误删
- 可选的保留策略
注意:运行前建议先用--dry-run参数检查结果,确认无误后再实际删除。
一句话建议:先干运行确认结果,再实际删除。

而且如果你收的是二次元的图片的话,那你应该要知道有的图片还分老版和新版的,有可能新版会加了细节,也有可能新版的分辨率会被故意降低。甚至如果你图源不一样的话,md5、分辨率都有可能不一样。比如同一作者在 p 站发的和在 twitter 上发的就有可能不一样。










python 确实挺好用的,我之前也是用 Python 整理了我的 ACM 代码,自动抓取网站的题目信息(题号,标题,描述,样例输入,样例输出)等,作为注释放在代码头部,并且把文件名改成题号+标题的格式,最后调用 AStyle 命令行自动格式化代码。
噗 我直接买了个软件 “ Duplicate Photos Fixer Pro ”,可以找相似图片文件,并列出来,删除的过程是手动的。
好用之处在于,不仅仅是 MD5 一样的才被列出来,同一张图片不同分辨率的也会别识别为相似图片。
这样比较方便我删除小尺寸图片,保留大尺寸图片。
不好之处在于,由于是完全按照相似度去识别的。比如公司集体照这种。。。连拍好几张的都会被认定为相似图片。
不过这个也算能解决,筛选时选择 “ Exact Match ” 就可以达到楼主脚本的效果。
