




Python快速调试工具库Boxx如何使用
最近写了一个提高 Python 调试效率的工具包 boxx ,目前快完工了, 先分享出来,欢迎大家多提意见,也希望大家能喜欢这个工具。
先从打印开始介绍吧,打印变量是最简单、直接的 debug 方式, 那能不能更简单?
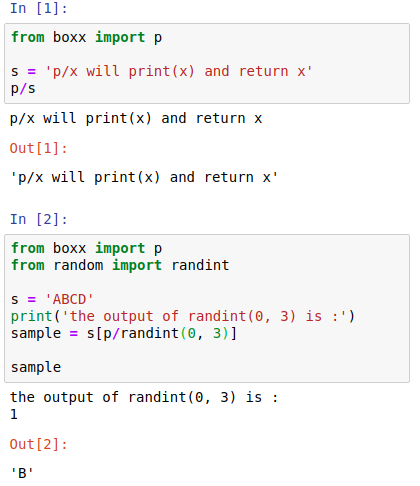
💡 Note: boxx.p 使用了 magic method, p/x 便会打印 x 并返回 x。这样便可以在任何地方打印,比如 例子中的 p/randint(0, 3) 就不需要新建变量便可直接打印
在函数内运行 p(),便会将函数或 module 内的所有变量名和值一同打印(相当于快捷打印 locals())
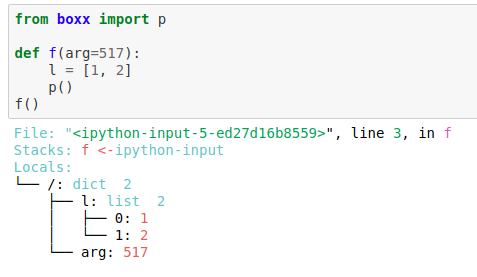
💡 Note: 在函数内 import boxx.p 和 p() 有相同的效果
许多数情况下, 直接 print 无法获得调试的关键信息。比如变量是有很多属性的对象,numpy 等类型
这时 就必须对变量进行分析, 方式有:
- 在调试处加上
print(x.text, x.code, np.hasinf(x),.np.hasnan(x)) - 设置断点进行分析
方法 1 每改一次调试代码 都要运行整个代码, 不灵活,操作也繁琐。
方法 2 中进入和退出 Debug console 比较麻烦,Debug console 本身也不太好用(没有自动补全功能)
boxx.g 提供了一种新的方式,通过 g.name 可以将变量传到当前的 Python 交互终端
变量传到 Python 终端后,就能对变量进行全面分析了,比如 使用tree,what 来分析
💡 Note:
gg的意思是to Global and log, 和g的用法一样, 但gg会在传输的同时打印变量.- 需要注意, 如果之前在终端中存在一样的变量名称,则变量的值会被新值覆盖.
在函数内运行 g(),便会将函数 (或 module) 内的所有变量一同传到当前的 Python 交互终端
这样 任何错误都可以在终端中复现和分析了。当然, 注意不要覆盖重要的全局变量。
💡 Note: 在函数内 import boxx.g 和 g() 有相同的效果
在实际开发调试中, 函数或 module 内可能含有非常多的变量 但我们只对几个变量感兴趣, with p, with g, with gg 可以使操作只作用于几个感兴趣的变量,只需把变量放入 with 结构中即可 :
💡 Note:
with p,with g,with gg只作用于在with结构中进行赋值操作的变量.- 如果变量名在
with前存在于locals()中, 同时id(变量)没有变化 ,with结构可能无法检测到该变量.
总结一下,boxx 的调试工具可以汇总为一个表
boxx 调试工具矩阵

💡 Note:
- transport 操作是指 把函数内的变量传送到 Python interactive console 中
locals()指 作用于函数或 module 内的所有变量locals()_2: 当boxx未导入时,import boxx.{操作}能等价于from boxx import {操作};{操作}()
在学习新框架或适配大佬代码时,经常会使用 print(x), dir(x), help(x), type(x) 来了解某个变量的各方面的信息 (变量可能是 值 /function/class/module 等),于是我写了一个 boox.what(x) 来全面了解"what is x?":

💡 Note: what(x) 通过打印 x 自己及x 的 文档, 父类继承关系, 内部结构 及 所有属性 来全面了解 x. 是 help(x) 的补充.
说了这么多调试 再说一下性能调优
测试代码性能时,计时很常用, 我写了一个方便的计时工具boxx.timeit 将想要计时的代码块放入 with timeit(): 中就可以计时了:
此外 SnakeViz 是一个很棒的性能分析工具,SnakeViz 能够通过 cProfile 文件,来统计代码的函数调用情况,并可视化出代码的 火焰图。但是, 先生成 cProfile 文件,再运行 SnakeViz 的流程非常繁琐,我把这一套操作封装成了 boxx.performance 来简化流程:

💡 Note: performance 也支持字符串形式的 Python 代码.
在进行密集运算和处理时 得写多进程的 Python 代码 来榨干 CPU 的每一个线程获得加速。但我觉得 Python 多进程的几个范式都不够方便,我参照 map 的思想和用法把多进程操作封装成 boxx.mapmp 函数(意思是"Map for Mulit Processing"). mapmp 和 map 有一样的用法, 只需把 map 替换为 mapmp 即可获得多进程加速:
💡 Note:
mapmp的 pool 参数来控制进程数目,默认为 CPU 线程数目.- 在多进程程序中, 打印进度往往非常麻烦.
mapmp的 printfreq 参数能解决这个问题. - 如同
map一样,mapmp支持将多个参数输入函数,如mapmp(add, list_1, list_2)
对于网络爬虫等高 IO 操作,boxx 还有个多线程版本的 map -- mapmt (意思是 "Map for Mulit Threading")。mapmt 用法和 mapmp 一样, 但没有多进程的诸多限制。
在开发和适配代码时,会遇到一些复杂的 dict,list。boxx.tree 可以直观地展示复杂结构。
大致就介绍这些 boxx 的这些功能吧,欢迎大家多提意见!
项目信息
GitHub 主页:https://github.com/DIYer22/boxx(内含有更多说明)
教程:boxx 的教程是一个可执行的在线 Notebook。 也就是说,无需下载和运行任何代码,只需浏览器点击下面的链接,就可以在线执行 Notebook 教程中的代码块。
=> 可直接执行的在线教程
Python快速调试工具库Boxx如何使用

我很喜欢第一个功能加 p/ 在任意位置打印
what 那个功能我之前写过更好的,你直接用就行了: https://github.com/laike9m/pdir2
有几个功能是不是和 ipdb 耦合得太紧了?不用 ipdb 或者 notebook 能用么?像火焰图和 boxx.p


前辈啊,之前和你的想法很接近,有想法后就直接动手实现了一个 boxx.dira( meaning dira attribute),后来又把能打印的信息都加上了 扩展成了 boxx.what。
整个项目都不需要 ipdb 或 notebook,可以在原始 Python 里直接使用,由于我主要做科学计算 更喜欢在 IPython 里面调试。 boxx.p 没有使用除了 sys 以外的包 火焰图用了标准库的 cProfile来产生调试文件 + SnakeViz 用浏览器可视化 cProfile文件


我是觉得 pdb 的 debug console 的体验和 IPython 差太多,才写了这个功能。平时调试 <a target="_blank" href="http://script.py" rel="nofollow noopener">script.py</a> 都是在 IPython console 里面运行 %run <a target="_blank" href="http://script.py" rel="nofollow noopener">script.py</a> 来运行再调试。
P.S. 平时调试时,把整个 local() 复制出来的 g() 操作更常用



