




Python中如何实现项目间同步数据的解决方案?
我现在有两个项目 A 和 B。都是 django+psgresql 结构的。
A 项目的主要功能是定时去查询数据并保存到本地。B 的主要功能是从各种其他项目中获取数据并保存,做关联展示的。
现在需要让 A 每次查询完数据后能把所有的数据都更新到 B 项目中。
我自己想了两种方案。
- 是 B 项目出一个 post 的创建记录的接口,A 项目每次查询结束后访问 B 的接口把数据都吐给 B。
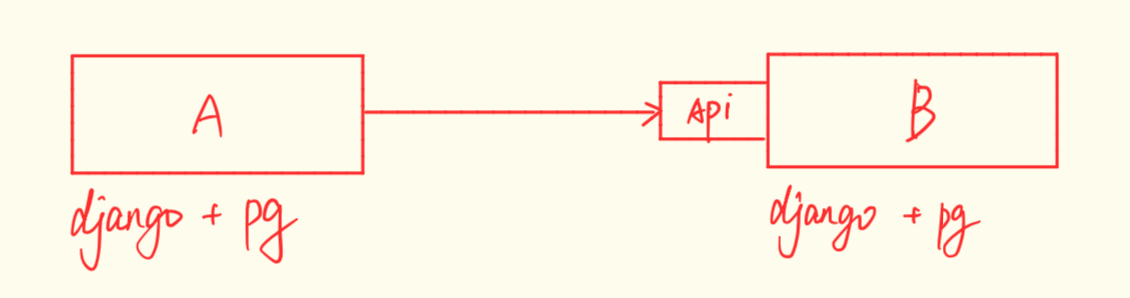
- A 项目出一个获取所有数据的接口,B 项目出一个启动异步更新任务的接口。然后每次 A 查询结束后访问一下 B 的启动任务的接口,让 B 中启动一个异步任务去访问 A 的接口拉取数据。
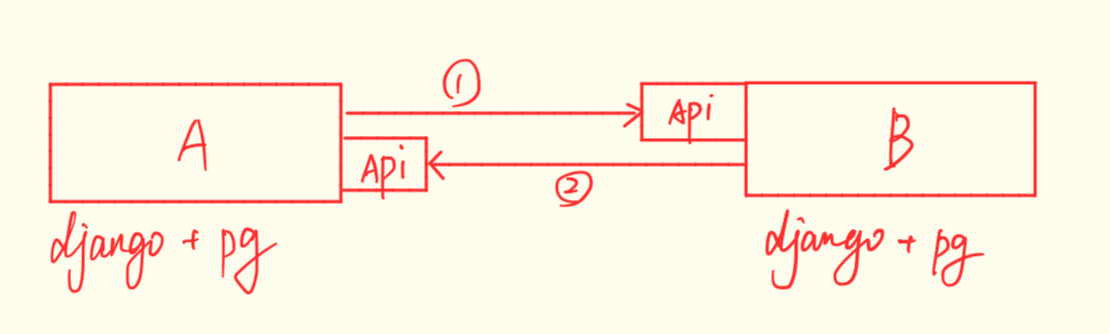
但是两种方案从安全认证,稳定性,可靠性和设计实现等方面讲我觉得都有点蠢。
也有想过用 django orm 连接两个数据库。但是觉得会提高耦合度。
想问下这种情况有没有什么成熟的解决方案?
第一次设计这种分散的系统没什么经验。
Python中如何实现项目间同步数据的解决方案?
4 回复

- 直接读库,成本最低,scale 最差。
2. A 提供查询接口,普通青年的选择。
3. B 提供一个 mq,A 把 CUD 作为 event 入队。
4. CQRS,成本最高,scale 最好。

对于项目间数据同步,Python这边有几个常用方案,看你的具体场景来选。
1. 数据库直接同步 如果两边都用数据库,这是最直接的。比如用SQLAlchemy同时连接两个库,读出来再写进去:
from sqlalchemy import create_engine
import pandas as pd
# 连接两个数据库
source_engine = create_engine('mysql://user:pass@source_host/db')
target_engine = create_engine('postgresql://user:pass@target_host/db')
# 读取数据
df = pd.read_sql('SELECT * FROM source_table', source_engine)
# 写入目标库
df.to_sql('target_table', target_engine, if_exists='replace', index=False)
2. 消息队列解耦 适合异步、高并发的场景,用RabbitMQ或Kafka:
import pika
import json
# 生产者
connection = pika.BlockingConnection(pika.ConnectionParameters('localhost'))
channel = connection.channel()
channel.queue_declare(queue='data_sync')
data = {'id': 1, 'value': 'test'}
channel.basic_publish(exchange='', routing_key='data_sync', body=json.dumps(data))
connection.close()
# 消费者
def callback(ch, method, properties, body):
data = json.loads(body)
# 处理数据并同步到目标项目
print(f"Received {data}")
channel.basic_consume(queue='data_sync', on_message_callback=callback, auto_ack=True)
channel.start_consuming()
3. API接口同步 一个项目暴露REST API,另一个项目调用:
import requests
import time
def sync_via_api(source_url, target_url, interval=60):
while True:
# 从源项目获取数据
response = requests.get(f'{source_url}/api/data')
data = response.json()
# 推送到目标项目
requests.post(f'{target_url}/api/sync', json=data)
time.sleep(interval)
4. 文件共享方式 适合批量同步,比如用SFTP或共享目录:
import paramiko
import json
# 通过SFTP同步JSON文件
def sync_via_sftp(host, username, password, local_path, remote_path):
transport = paramiko.Transport((host, 22))
transport.connect(username=username, password=password)
sftp = paramiko.SFTPClient.from_transport(transport)
# 下载远程文件
sftp.get(remote_path, local_path)
# 处理数据...
with open(local_path) as f:
data = json.load(f)
# 上传处理后的文件
sftp.put(local_path, remote_path + '.synced')
sftp.close()
transport.close()
5. 使用同步工具 如果不想写太多代码,可以直接用现成的:
- Apache Airflow:定时调度同步任务
- Prefect:现代的工作流管理
- 自定义脚本 + cron:简单场景用这个就行
选哪个方案主要看:数据量大小、实时性要求、项目架构是否允许直接连库。小项目用数据库直连或API,大系统用消息队列。
总结:根据实时性和复杂度选方案。


根据你的实际情况选最简单有效的方案实现,不要盲目追求架构引入不必要的复杂性.无论是采用什么方案来实现业务处理的代码是一样的,B 只对上层暴露一个处理业务的函数 ,区别只是接收消息的方式不同 .