




时隔五年,Python爬虫部署工具Scrapyd终于原生支持basic auth
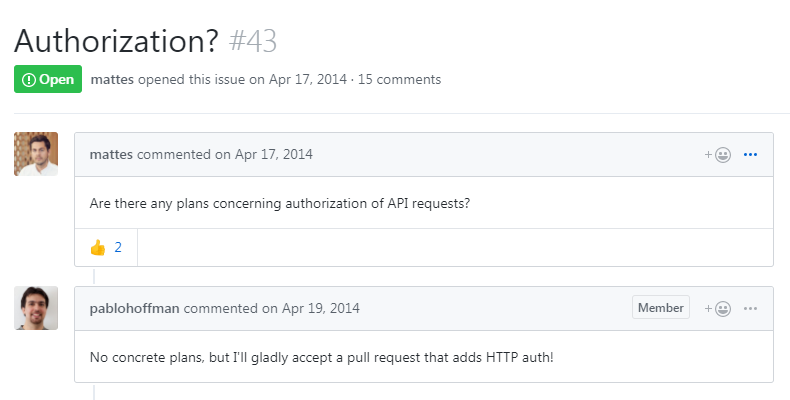
Issue in 2014
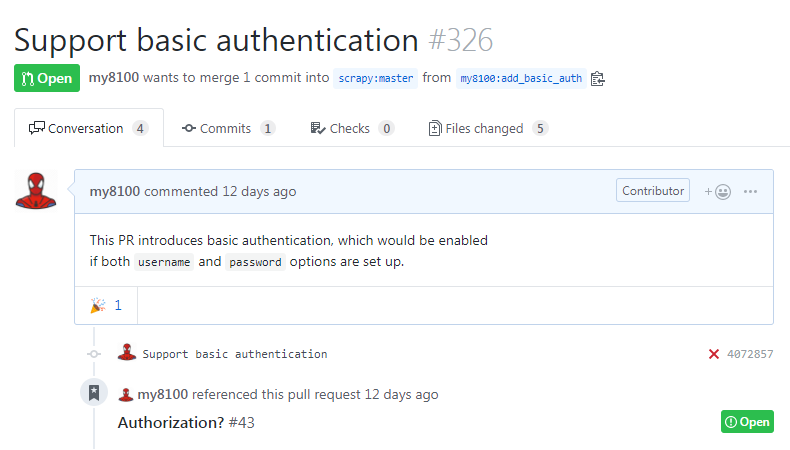
Pull request in 2019
试用
1.安装
pip install -U git+https://github.com/my8100/scrapyd.git[@add_basic_auth](/user/add_basic_auth)
2.更新配置文件 scrapyd.conf,其余配置项详见官方文档
[scrapyd]
username = yourusername
password = yourpassword
3.启动:scrapyd
In [1]: import requests
In [2]: requests.get(‘http://127.0.0.1:6800/’).status_code
Out[2]: 401
In [3]: requests.get(‘http://127.0.0.1:6800/’, auth=(‘admin’, ‘admin’)).status_code
Out[3]: 401
In [4]: requests.get(‘http://127.0.0.1:6800/’, auth=(‘yourusername’, ‘yourpassword’)).status_code
Out[4]: 200
4.由于 Scrapyd 的 GitHub 最新提交已经重构了 Jobs 页面,如果正在使用 ScrapydWeb 管理 Scrapyd,则需同步更新 ScrapydWeb:
pip install -U git+https://github.com/my8100/scrapydweb.git
GitHub
时隔五年,Python爬虫部署工具Scrapyd终于原生支持basic auth
1 回复

Scrapyd 1.4.0 版本确实原生支持了 Basic Auth,这是个很实用的更新。之前要么用 Nginx 做反向代理加认证,要么得改 Scrapyd 源码,现在配置起来简单多了。
配置方法:
在你的 scrapyd.conf 文件里加上下面这两行就行:
basic_auth = myuser:mypassword
basic_auth_enabled = True
第一行设置用户名和密码,用冒号隔开。第二行开启这个功能。改完重启 Scrapyd 服务就生效了。
代码调用示例: 用 requests 库访问时,带上 auth 参数:
import requests
from requests.auth import HTTPBasicAuth
response = requests.get(
'http://localhost:6800/daemonstatus.json',
auth=HTTPBasicAuth('myuser', 'mypassword')
)
print(response.json())
或者直接把认证信息放到 URL 里:
import requests
response = requests.get('http://myuser:mypassword@localhost:6800/daemonstatus.json')
print(response.json())
用 scrapy 的 scrapyd-client 部署的话,在 scrapy.cfg 里配置:
[deploy:production]
url = http://localhost:6800/
project = myproject
username = myuser
password = mypassword
这个更新让 Scrapyd 的部署更安全了,建议升级到最新版直接用。