




Python中如何实现动态页面的爬取?
刚开始学习爬虫,上次有大佬在 V2 发了表情包的网站,今天想爬点表情包玩,发现加载页面是滚动加载的,看了下 network 加载的内容,
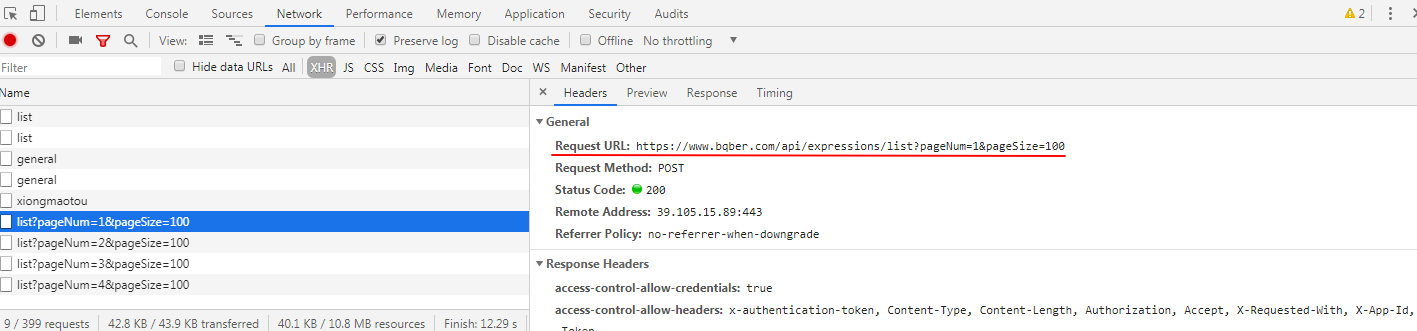 Request URL 这里的内容复制放到新页面地址栏无法加载,找不到思路了 ,求大佬解答!
之前爬别的滚动加载的页面,可以通过 Request URL 里的地址在新的页面打开,这种第一次遇见。
而且这个地址的内容和原本的页面地址也找不到关联的地方。
Request URL 这里的内容复制放到新页面地址栏无法加载,找不到思路了 ,求大佬解答!
之前爬别的滚动加载的页面,可以通过 Request URL 里的地址在新的页面打开,这种第一次遇见。
而且这个地址的内容和原本的页面地址也找不到关联的地方。
Python中如何实现动态页面的爬取?


对于动态页面的爬取,关键在于处理JavaScript渲染。传统的requests库只能获取静态HTML,而动态内容通常通过AJAX加载。以下是几种核心方法:
1. 直接分析API接口(推荐)
大多数动态网站通过XHR/Fetch请求获取数据。使用浏览器开发者工具(F12→Network→XHR)找到真实的数据接口,然后用requests直接调用:
import requests
import json
headers = {
'User-Agent': 'Mozilla/5.0',
'X-Requested-With': 'XMLHttpRequest'
}
params = {'page': 1, 'size': 20}
response = requests.get('https://api.example.com/data', params=params, headers=headers)
data = json.loads(response.text)
2. 使用Selenium模拟浏览器 当无法直接找到API时,可以用Selenium控制真实浏览器:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get('https://example.com')
# 等待动态内容加载
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
)
html = driver.page_source
driver.quit()
3. 使用Playwright(更现代的选择) Playwright比Selenium更快,支持异步:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch()
page = browser.new_page()
page.goto('https://example.com')
page.wait_for_selector('.dynamic-content')
content = page.content()
browser.close()
4. 逆向工程JavaScript
对于有反爬机制的网站,可能需要分析JS加密逻辑,使用execjs执行JavaScript:
import execjs
with open('decrypt.js', 'r') as f:
js_code = f.read()
ctx = execjs.compile(js_code)
result = ctx.call('decryptFunction', encrypted_data)
选择建议: 优先尝试直接调用API接口,这是最稳定高效的方式;如果不行再考虑Selenium或Playwright。
一句话总结: 动态爬取的核心是找到数据源或模拟浏览器执行JS。



有什么方法是可以实现自动翻页的吗?
我观察了一下翻页的结果,翻页到最后之后,可以在整个页面提取到所有的表情包 URL,
根据这个思路是不是可以先请求分类标签的 url 地址,然后翻页到最后,再从返回的内容里提取所有的图片 url 地址成一个列表再遍历下载?


试了一下,这个请求还对 body 有要求:
POST /api/expressions/list?pageNum=1& pageSize=100000 HTTP/1.1
Host: www.bqber.com
Content-Type: application/json
User-Agent: PostmanRuntime/7.15.2
Accept: /
Cache-Control: no-cache
Postman-Token: 5ab5da52-bf5d-4d78-937b-80f914c0f34d,e7915629-e679-4617-912d-729dc02dc82e
Host: www.bqber.com
Accept-Encoding: gzip, deflate
Content-Length: 13
Connection: keep-alive
cache-control: no-cache
{“name”:null}
这样发过去就行了


