




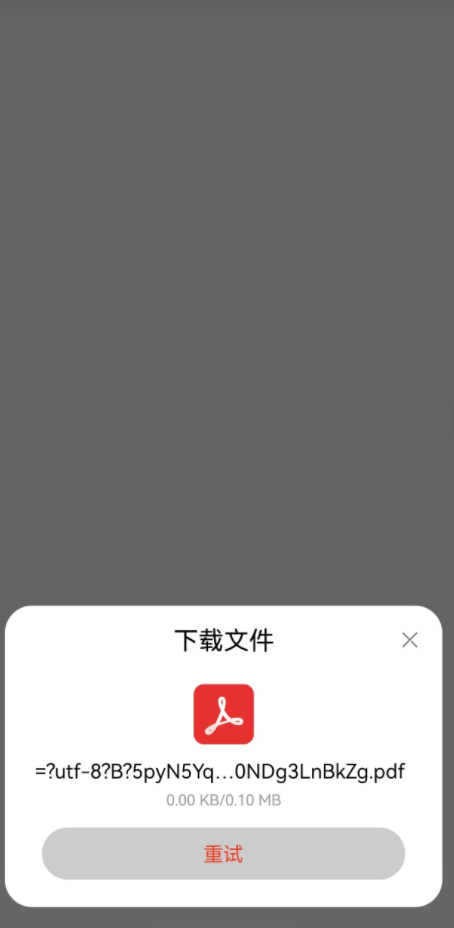
HarmonyOS 鸿蒙Next原生浏览识别文件编码字符失败
HarmonyOS 鸿蒙Next原生浏览识别文件编码字符失败 原生鸿蒙系统自带浏览器对部分文件类型的下载地址编码字符识别存在兼容性问题,相同链接在安卓和ios浏览器可以正常下载
更多关于HarmonyOS 鸿蒙Next原生浏览识别文件编码字符失败的实战教程也可以访问 https://www.itying.com/category-93-b0.html
4 回复

开发者您好,本地未复现问题,为快速定位问题请提供完整的能复现问题的下载地址。感谢您的理解与支持。
更多关于HarmonyOS 鸿蒙Next原生浏览识别文件编码字符失败的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


HarmonyOS Next原生浏览识别文件编码字符失败,主要涉及文件编码解析问题。可能原因包括:系统内置编码库不支持特定编码格式、文件头信息缺失或异常、系统API对非标准编码兼容性不足。需检查文件编码格式是否为UTF-8、GBK等常见类型,或使用鸿蒙提供的文件编码检测接口进行验证。
