




HarmonyOS鸿蒙Next中Pocket 2是被放弃更新了吗
HarmonyOS鸿蒙Next中Pocket 2是被放弃更新了吗
这款手机已经很久没更新了,连个抖音播放都不是全屏的,真的太无语了,难用的要死,动不动发烫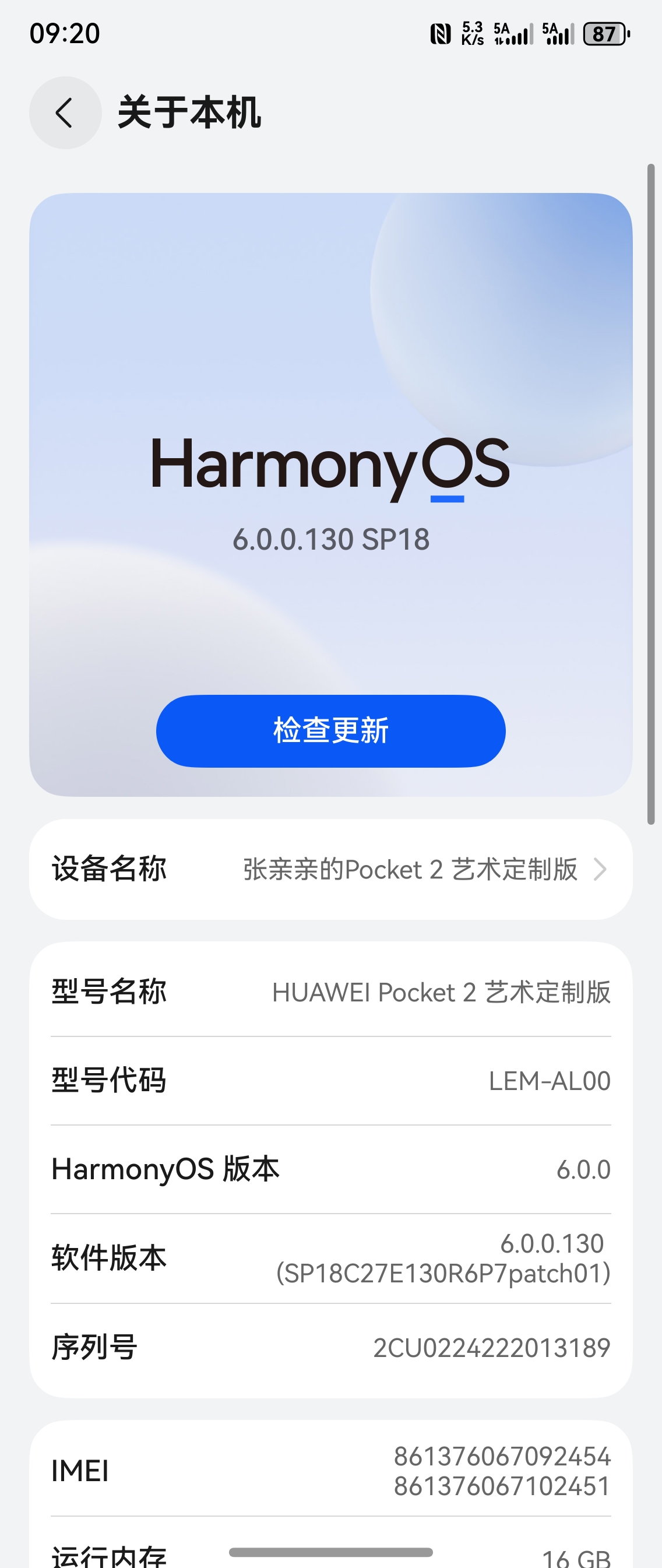
更多关于HarmonyOS鸿蒙Next中Pocket 2是被放弃更新了吗的实战教程也可以访问 https://www.itying.com/category-93-b0.html

使用Python进行数据分析
数据清洗
1. 处理缺失值
import pandas as pd
import numpy as np
# 创建示例数据
data = {'A': [1, 2, np.nan, 4],
'B': [5, np.nan, np.nan, 8],
'C': [10, 11, 12, 13]}
df = pd.DataFrame(data)
# 检查缺失值
print(df.isnull().sum())
# 删除包含缺失值的行
df_dropped = df.dropna()
print(df_dropped)
# 用均值填充缺失值
df_filled = df.fillna(df.mean())
print(df_filled)
2. 处理重复值
# 创建包含重复值的数据
data = {'A': [1, 2, 2, 3, 3],
'B': ['a', 'b', 'b', 'c', 'c']}
df = pd.DataFrame(data)
# 检查重复值
print(df.duplicated())
# 删除重复值
df_unique = df.drop_duplicates()
print(df_unique)
数据转换
1. 数据类型转换
# 创建示例数据
data = {'price': ['100', '200', '300'],
'quantity': [5, 10, 15]}
df = pd.DataFrame(data)
# 转换数据类型
df['price'] = df['price'].astype(int)
df['total'] = df['price'] * df['quantity']
print(df.dtypes)
print(df)
2. 数据标准化
from sklearn.preprocessing import StandardScaler
# 创建示例数据
data = {'feature1': [100, 200, 300, 400],
'feature2': [10, 20, 30, 40]}
df = pd.DataFrame(data)
# 标准化数据
scaler = StandardScaler()
scaled_data = scaler.fit_transform(df)
df_scaled = pd.DataFrame(scaled_data, columns=df.columns)
print(df_scaled)
数据分析
1. 描述性统计
# 创建示例数据
np.random.seed(42)
data = {'score': np.random.normal(75, 10, 100),
'age': np.random.randint(18, 35, 100)}
df = pd.DataFrame(data)
# 基本统计信息
print(df.describe())
# 相关系数
correlation = df.corr()
print(correlation)
2. 分组分析
# 创建示例数据
data = {'department': ['A', 'A', 'B', 'B', 'A', 'B'],
'employee': ['John', 'Jane', 'Bob', 'Alice', 'Mike', 'Sarah'],
'salary': [50000, 55000, 60000, 65000, 52000, 62000]}
df = pd.DataFrame(data)
# 按部门分组计算平均薪资
grouped = df.groupby('department')['salary'].mean()
print(grouped)
# 多维度分组
grouped_multi = df.groupby(['department']).agg({'salary': ['mean', 'sum', 'count']})
print(grouped_multi)
数据可视化
1. 使用Matplotlib
import matplotlib.pyplot as plt
# 创建数据
x = np.linspace(0, 10, 100)
y = np.sin(x)
# 绘制图形
plt.figure(figsize=(10, 6))
plt.plot(x, y, label='sin(x)', color='blue', linewidth=2)
plt.title('Sine Wave')
plt.xlabel('X')
plt.ylabel('Y')
plt.legend()
plt.grid(True, alpha=0.3)
plt.show()
2. 使用Seaborn
import seaborn as sns
# 加载示例数据集
tips = sns.load_dataset('tips')
# 绘制箱线图
plt.figure(figsize=(10, 6))
sns.boxplot(x='day', y='total_bill', data=tips)
plt.title('Total Bill by Day')
plt.show()
# 绘制热力图
corr_matrix = tips.corr()
plt.figure(figsize=(8, 6))
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.title('Correlation Heatmap')
plt.show()
高级分析技巧
1. 时间序列分析
# 创建时间序列数据
dates = pd.date_range('2023-01-01', periods=100, freq='D')
data = np.random.randn(100).cumsum()
ts = pd.Series(data, index=dates)
# 移动平均
rolling_mean = ts.rolling(window=7).mean()
# 绘制时间序列
plt.figure(figsize=(12, 6))
ts.plot(label='Original')
rolling_mean.plot(label='7-Day Moving Average', linewidth=2)
plt.title('Time Series Analysis')
plt.xlabel('Date')
plt.ylabel('Value')
plt.legend()
plt.show()
2. 机器学习集成
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
# 创建示例数据
from sklearn.datasets import make_classification
X, y = make_classification(n_samples=1000, n_features=20, random_state=42)
# 分割数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 训练模型
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# 预测和评估
y_pred = model.predict(X_test)
print(classification_report(y_test, y_pred))
最佳实践建议
- 数据备份:在进行任何数据转换前,先备份原始数据
- 代码注释:为复杂的数据处理步骤添加详细注释
- 版本控制:使用Git等工具管理数据分析代码
- 性能优化:对于大数据集,考虑使用Dask或PySpark
- 结果验证:定期检查数据处理结果的正确性
常见问题解决
内存不足问题
# 使用分块读取大文件
chunk_size = 10000
chunks = pd.read_csv('large_file.csv', chunksize=chunk_size)
# 逐块处理数据
for chunk in chunks:
# 处理每个数据块
processed_chunk = chunk.dropna()
# 保存或进一步处理
处理大数据集
# 使用合适的数据类型减少内存使用
df['column'] = df['column'].astype('category') # 对于分类数据
df['column'] = df['column'].astype('int32') # 对于整数数据
这些技巧和方法可以帮助您更高效地进行Python数据分析工作。
更多关于HarmonyOS鸿蒙Next中Pocket 2是被放弃更新了吗的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html



根据华为官方信息,HarmonyOS Next版本目前处于开发者预览阶段,主要面向应用生态构建。Pocket 2等具体设备的系统更新计划,需以华为官方后续发布的正式公告为准。目前没有官方声明表明任何现有设备被放弃更新。

根据目前公开的官方信息,华为并未宣布放弃对Pocket 2的HarmonyOS Next更新支持。
您遇到的“很久没更新”、应用适配(如抖音非全屏)以及发热问题,更可能与以下情况相关:
-
HarmonyOS 4与Next版本的节奏差异:当前Pocket 2等已上市设备主要接收的是基于OpenHarmony AOSP兼容框架的HarmonyOS 4.x版本的系统更新和维护。而您提到的HarmonyOS Next(即“纯血鸿蒙”)是下一个主要的大版本,其开发者预览版/Beta版目前主要面向合作伙伴和开发者,在特定开发机型上进行测试。面向广大存量用户的HarmonyOS Next正式版升级计划,通常会由官方在后续统一公布升级机型列表和时间表。因此,Pocket 2目前未收到Next版本更新,属于正常的版本发布节奏,不代表被放弃。
-
应用适配问题:抖音等第三方应用的全屏显示、深度优化体验,需要应用开发者基于HarmonyOS的API和设计规范进行适配。在HarmonyOS Next完全独立的新生态下,这一适配过程需要时间。您遇到的非全屏问题,很可能是因为该应用尚未针对您设备当前的HarmonyOS版本完成全面的界面适配。
-
系统优化与发热:日常使用发热可能与特定应用版本的后台活动、系统后台服务或当前系统版本的功耗优化策略有关。这类问题通常会在后续的系统维护更新中得到修复和优化。
建议您关注“我的华为”App中的服务通知或官方HarmonyOS升级公告,以获取关于Pocket 2未来系统升级(包括可能的大版本如Next)的确切信息。 目前的情况更可能是处于新老版本交替的常规阶段,而非对设备的放弃。