





HarmonyOS 鸿蒙Next深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销
HarmonyOS 鸿蒙Next深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销
摘要:Host调度模式下,GE将模型中算子的执行单元划分为Host CPU执行与Device(昇腾AI处理器)执行两大类。
本文分享自华为云社区《深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销》,作者:昇腾CANN。
GE(Graph Engine)将模型的调度分为Host调度与下沉调度两种模式。经过上期的介绍我们知道,在模型为静态shape时,由于其输入tensor shape固定不变,在编译时就能确定所有算子的输入输出shape,并能提前完成模型级内存编排、tiling计算等Host调度工作,因此采用模型下沉调度方式可以将整个模型下沉到Device侧执行,从而提升模型调度性能。
与之对应的,在模型为动态shape的情况下,由于输入tensor shape不确定,需要在上一个算子完成shape推导后,才能确定下一个算子的输入shape等信息,因此无法将整个模型下沉执行,只能采用Host调度模式。
1 Host调度简介及优化背景
所谓Host调度,是指模型的调度主体位于Host CPU,由CPU完成逐算子调度。一个算子的调度任务为kernel执行准备必要参数,通常包含shape推导、tiling、内存分配、launch等。
Host调度模式下,GE将模型中算子的执行单元划分为Host CPU执行与Device(昇腾AI处理器)执行两大类。对于卷积、MatMul等对算力要求高的算子,会被划分到Device执行;而由于shape信息在Host CPU维护,Shape、Reshape等算子更适合被划分到Host CPU执行;除此之外,还有一些算子,在shape较小时,计算量也很小,调度开销往往大于算子的实际计算开销,就需要考虑如何尽可能减少调度开销带来的性能影响。
图1 网络拓扑片段
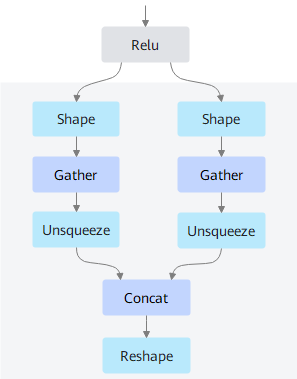
图1是一段网络拓扑片段示例,按照一般的调度机制,Gather、Concat算子会下沉到Device侧计算,Shape、Unsqueeze、Reshape算子在Host侧计算。其执行时序如图2所示,模型E2E执行耗时除了包含算子计算的时间外,还包含Host与Device之间的数据拷贝、算子下沉调度、Stream同步等开销,整体执行E2E耗时在毫秒级别。
图2 优化前执行时序
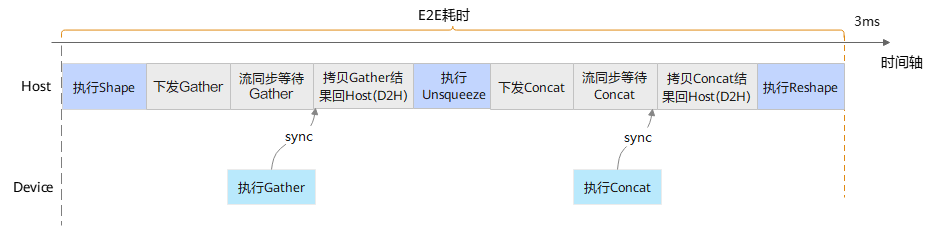
而对于小shape(如shape size小于8)的Gather、Concat,算子本身在Host侧CPU的计算开销上仅微秒级别,与Device侧计算的性能相差无几。此时下发带来的额外开销就显得比较明显。针对上述这种shape较小且输入Tensor内存在Host的场景,GE识别将这部分算子保留在Host侧执行,可有效减少调度开销带来的性能影响。
2 小shape算子计算优化实现
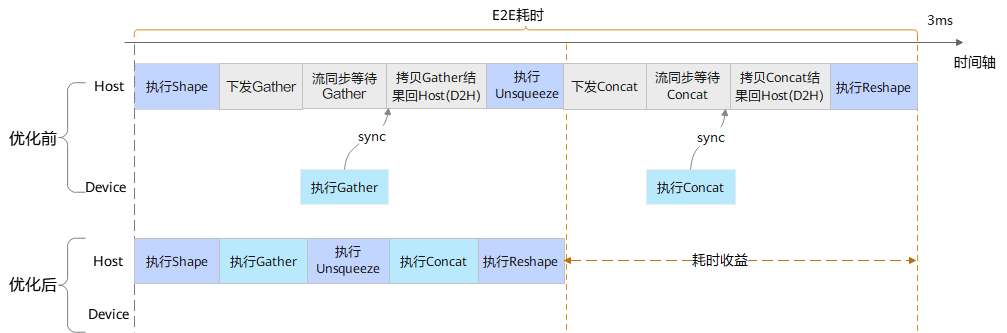
在图编译流程执行到引擎选择之后,GE选择在Host侧执行的算子并将其作为锚点,然后向后递归查找计算数据个数小于8的算子,并将这些算子的执行引擎修改为Host CPU。针对图1所示的网络片段,假设shape算子的输出的shape size小于8,则Gather、Concat算子的执行引擎都会被刷新成Host CPU。优化后执行时序如图3所示,此时模型执行只有算子计算带来的开销,经测试约为10微秒(3ms –> 10us),显著的提高了E2E执行性能。
图3 优化前后执行前后时序对比
3 优化效果
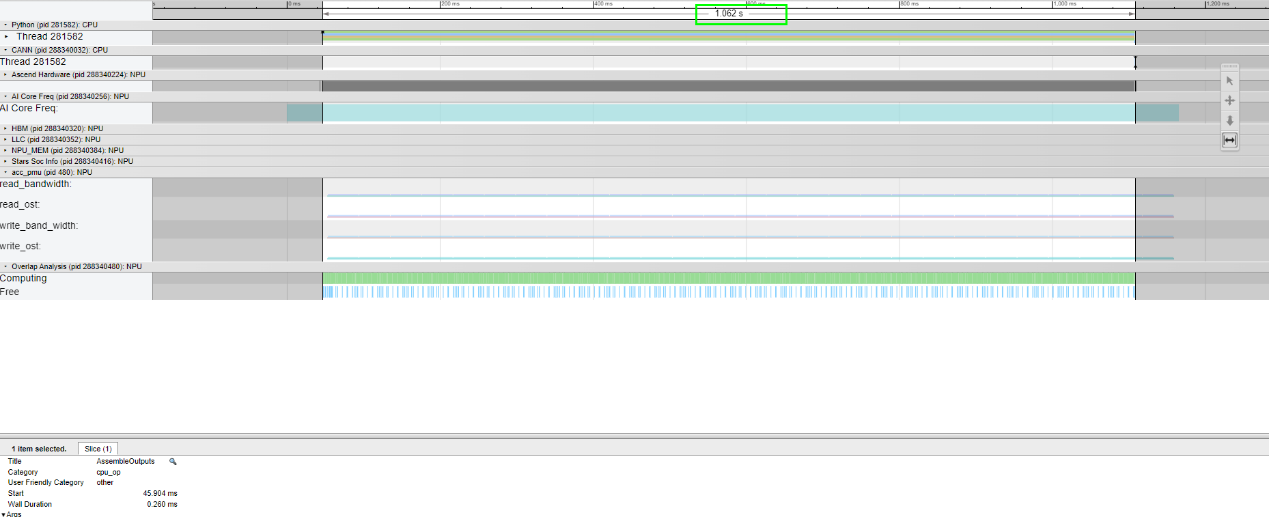
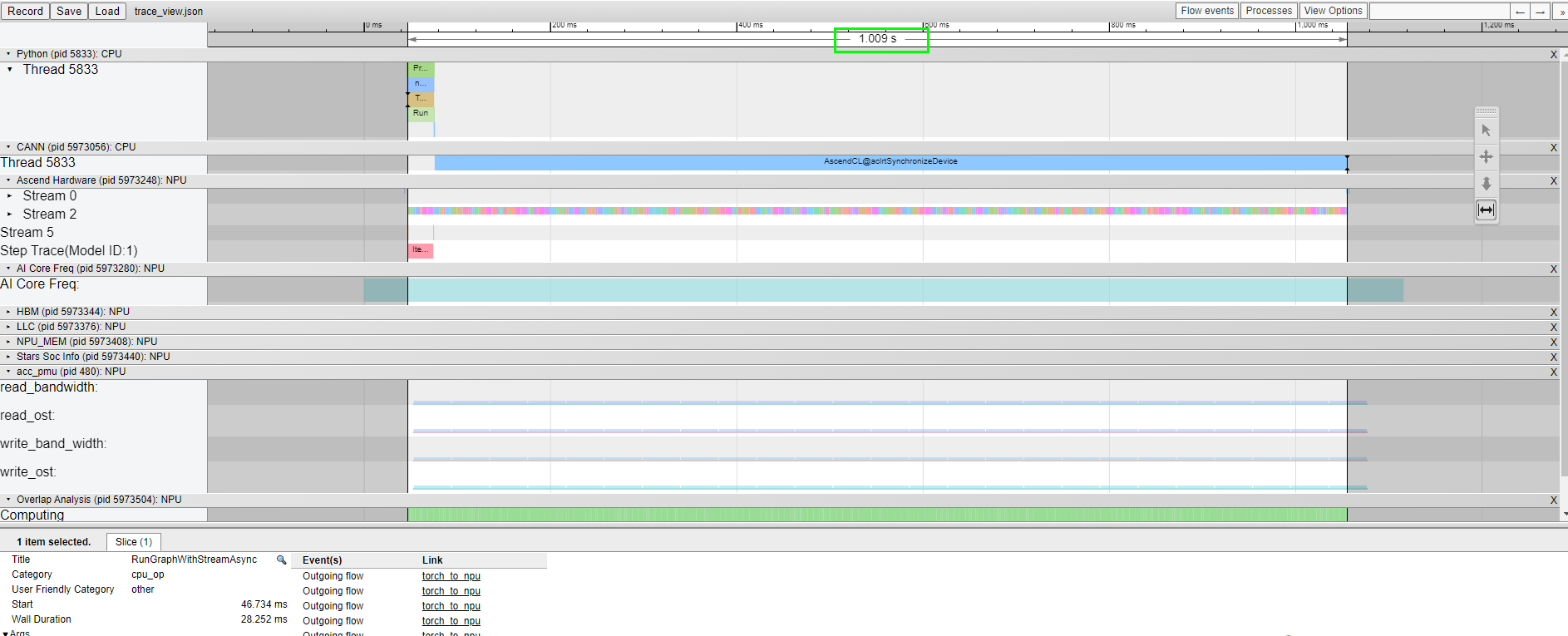
以LLaMA2大语言推理模型为例,符合上述执行引擎刷新的算子有Pack、Gather、Concat等约650+个,刷新前模型E2E耗时约1.062S,刷新后执行时间优化到了1.009S,吞吐提升5%。
4 更多介绍
GE小shape算子计算优化技术的相关介绍就到这里,欢迎大家关注后续技术分享。如需获取更多学习资源请登录昇腾社区。
更多关于HarmonyOS 鸿蒙Next深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


更多关于HarmonyOS 鸿蒙Next深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html

HarmonyOS 鸿蒙Next深度集成的昇腾CANN小shape算子计算优化技术,通过GE图引擎的Host调度模式,针对shape较小且输入Tensor内存在Host的场景,将算子保留在Host侧执行,显著减少调度开销。该技术优化了如Gather、Concat等小shape算子的执行效率,提升整体模型性能。例如,在LLaMA2大语言推理模型中,该技术使模型E2E耗时从1.062秒优化到1.009秒,吞吐提升5%。如果问题依旧没法解决请加我微信,我的微信是itying888。
更多关于HarmonyOS 鸿蒙Next深度解读昇腾CANN小shape算子计算优化技术,进一步减少调度开销的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html