




HarmonyOS 鸿蒙Next深度解读昇腾CANN多流并行技术,提高硬件资源利用率
HarmonyOS 鸿蒙Next深度解读昇腾CANN多流并行技术,提高硬件资源利用率
摘要:GE(Graph Engine)图引擎采用多流并行算法,在满足计算图任务内部依赖关系的前提下,支持高效并发执行计算任务,从而大大提高硬件资源利用率和AI计算效率。
本文分享自华为云社区《深度解读昇腾CANN多流并行技术,提高硬件资源利用率》,作者:昇腾CANN。
随着人工智能应用日益成熟,文本、图片、音频、视频等非结构化数据的处理需求呈指数级增长,数据处理过程从通用计算逐步向异构计算过渡。面对多样化的计算需求,昇腾AI处理器内置丰富的硬件计算资源用于处理不同的计算任务。其中,AI Core、Vector Core与AI CPU分别负责AI计算场景下的矩阵、向量与标量计算,DVPP支持图像、视频等数据的加速处理,而HCCL作为华为集合通信库,则提供单机多卡及多机多卡间的数据并行、模型并行集合通信方案。
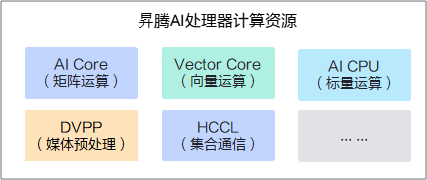
在给定硬件算力的情况下,如何高效利用这些计算资源、提高计算效率显得尤其重要。多样化的计算任务以task的形式下发到各硬件资源执行,GE(Graph Engine)图引擎采用多流并行算法,在满足计算图任务内部依赖关系的前提下,支持高效并发执行计算任务,从而大大提高硬件资源利用率和AI计算效率。
1 多流并行技术实现
计算图编译时,GE会为计算图中的每个节点分配一个硬件资源(即对应一种执行引擎),在任务执行时按编译时分配的stream调度顺序下发到对应的引擎执行。
各引擎使用不同的硬件计算资源,若同一时间只能执行某种引擎的一个task,则其余引擎会处于闲置状态,导致硬件资源严重浪费,影响端到端性能。若采用多流并行技术,在满足依赖关系的前提下,将不同task下发到对应的引擎上,驱动各个引擎并行执行,则可大大提升硬件资源的利用率。
GE采用了多流并行算法,将计算图的拓扑结构、硬件资源规格和执行引擎作为计算要素,为每个节点分配Stream。Stream与硬件资源绑定,任务执行时会按编译时分配的stream调度顺序下发到对应的引擎执行。同一Stream上的任务串行执行,不同Stream间的任务并发执行,从而提升硬件计算资源利用率。
GE多流并行技术的实现流程如下:
1. 基于网络节点功能和硬件资源特性,给每个节点分配执行引擎。
2. 基于网络拓扑结构和每个节点的执行引擎,为每个节点分配Stream。分配Stream时会同时考虑硬件规格、资源利用率等,提升并发度。
3. 不同Stream间可以进行同步来保证执行时序。
GE多流并行主要包含以下场景:
1. 计算与通信引擎并行:计算算子(如Convolution、Add等)会生成计算task,通信算子(HcomAllReduce等)会生成卡间通信task,两类task无拓扑依赖时可并发执行。

2. 不同计算引擎并行:矩阵运算(AI Core)、向量运算(VectorCore)和图像预处理(DVPP)等不同引擎的task,可下发到不同的引擎上并发执行。

3. 相同计算引擎内并行:当计算图中某个节点无法占满一个计算引擎的全部计算资源,且拓扑结构可并发时,该引擎的不同拓扑集合的task可并发执行。

2 多流并行执行效果
并行执行效果跟网络拓扑结构、节点引擎类型、AI处理器能力等因素存在相关性,理论最优并行场景下,整网执行时长为耗时最长的Stream的执行时长,其余Stream的执行时长都掩盖在该Stream的时长内。如下图所示,通信耗时可以掩盖在计算耗时内,向量计算耗时可以掩盖在矩阵运算耗时内。
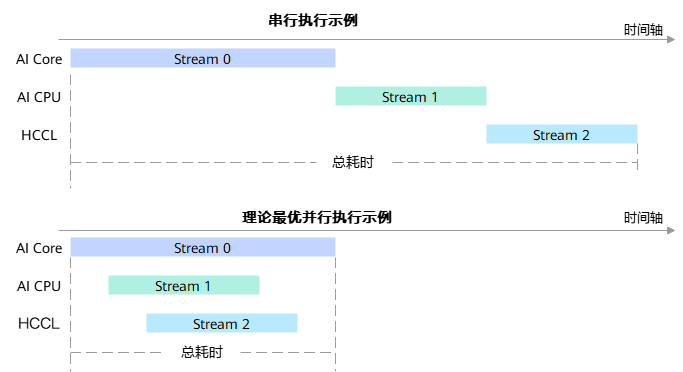
基于Atlas 800I A2推理产品,在经过计算通信流水并行优化后,LLaMA-65B参数模型全量图执行性能提升30%左右,盘古系列71B参数模型全量图执行性能提升15%左右。
然而,多流并行是一种资源换执行效率的技术,会占用更多的Device流资源,一般来说,静态shape场景下开启多流并行后,内存占用增加7%左右,用户可结合实际情况选择使用。
3 如何使能多流并行技术
GE的多流并行技术是基于深度学习计算图模式下的计算优化手段,在静态shape的离线推理场景和Pytorch框架的计算图模式下默认使能多流并行技术,开发者可通过相应的参数enable_single_stream灵活控制。
import torchair as tng
config = tng.CompilerConfig()
# 关闭图单流执行功能
config.ge_config.enable_single_stream = False
# 开启计算通信并行功能
config.experimental_config.cc_parallel_enable = True
npu_backend = tng.get_npu_backend(compiler_config=config)
…
model = Model()
model = torch.compile(model, backend=npu_backend, dynamic=False) 4 获取学习资源
GE多流并行技术的介绍就到这里,欢迎大家关注后续技术分享。如需获取更多学习资源请登录昇腾社区。


作为IT专家,对于HarmonyOS 鸿蒙Next与昇腾CANN多流并行技术的结合有着深入理解。HarmonyOS 鸿蒙Next作为一款纯国产全自研自主可控的操作系统,采用了全新的架构设计,在性能、设计、安全、AI等方面都作出了巨大升级。而昇腾CANN(Compute Architecture for Neural Networks)则是华为推出的AI计算架构,旨在高效使能AI原生创新。
鸿蒙Next与昇腾CANN的结合,在多流并行技术方面展现了显著优势。面对多样化的计算需求,昇腾AI处理器内置丰富的硬件计算资源,如AI Core、Vector Core、AI CPU等,分别负责不同的计算任务。而GE(Graph Engine)图引擎采用的多流并行算法,能够在满足计算图任务内部依赖关系的前提下,支持高效并发执行计算任务,从而大大提高硬件资源利用率和AI计算效率。
具体来说,GE会为计算图中的每个节点分配一个硬件资源(即对应一种执行引擎),在任务执行时按编译时分配的stream调度顺序下发到对应的引擎执行。不同stream间的任务可以并发执行,从而提升了硬件计算资源的利用率。这种技术优化了在静态shape的离线推理场景和Pytorch框架下的计算图模式。
综上所述,HarmonyOS 鸿蒙Next与昇腾CANN多流并行技术的结合,为AI计算带来了显著的性能提升。这一技术不仅提高了硬件资源的利用率,还加速了AI应用的执行效率。如果问题依旧没法解决请联系官网客服,官网地址是:https://www.itying.com/category-93-b0.html。