




HarmonyOS 鸿蒙Next冷启动响应时延问题分析思路&案例
HarmonyOS 鸿蒙Next冷启动响应时延问题分析思路&案例
1. 场景导入
应用启动可以分为冷启动和热启动:
冷启动:当应用启动时,后台没有该应用的进程,这时系统会重新创建一个新的进程分配给该应用, 这种启动方式就叫做冷启动;
热启动:当应用程序已经在后台运行,此时用户再次打开应用程序时,应用程序仍然在内存中,可以直接从内存中加载并继续之前的状态,而不需要重新初始化和加载资源,这种称为热启动。
冷启动响应时延:应用冷启动时,从点击应用离手开始到桌面应用图标发生变化(通常指图标变大)的这一段时间称为冷启动响应时延。
2. 性能指标
2.1 性能指标介绍
冷启动响应时延推荐时间:85ms
2.2 性能衡量起止点介绍

应用冷启动响应时延的性能衡量的起点为用户点击应用图标离手帧时间,止点为桌面应用图标开始发生变化的首帧时间。
3. 问题定位流程
3.1 常规定位前置流程
3.1.1、 确认效果
处理三方应用问题前首先需要先和三方应用及测试确认当前问题场景的预期效果:
- 三方应用:和三方应用确认问题场景是否认可该标准,如不认可,相关问题需评审关闭。
- 测试:和测试确认是否按照预期效果执行的测试,测试步骤和性能衡量是否准确。
3.1.2 查看操作录屏辅助定位
处理三方应用问题时,可以优先查看操作录屏,查看操作场景,看能否发现一些有助于定位的信息,比如应用启动是否存在横竖屏切换,是否存在页面跳转,是否包含网络加载等等。
3.1.3 Trace抓取
冷启动Trace抓取请参考【附录1: 冷启动Trace抓取方法】。
3.2 问题定位思路
冷启动响应时延类问题的通用定位思路为先确认时延起止点,然后看起止点时延是否超60ms,未超过则说明达标,超过则根据Trace信息进一步确认问题点,确认责任领域并对齐处理(通常冷启动时延类问题责任领域都在大桌面),处理流程如下图:
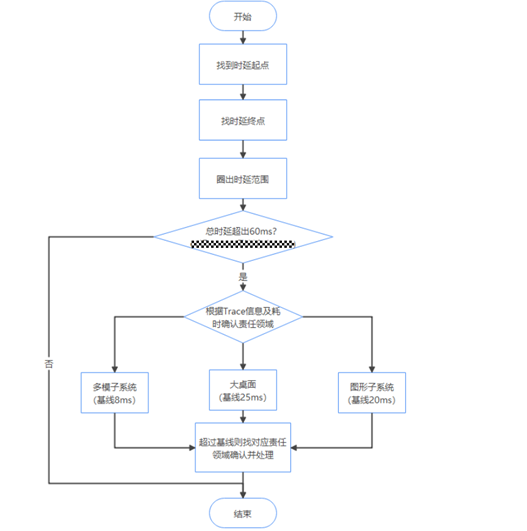
注:图中耗时基线均为参考值,仅供定界参考,实际各子系统是否超标需和对应子系统接口人确认。
3.2.1 确认起止点
冷启动响应时延起点确认:
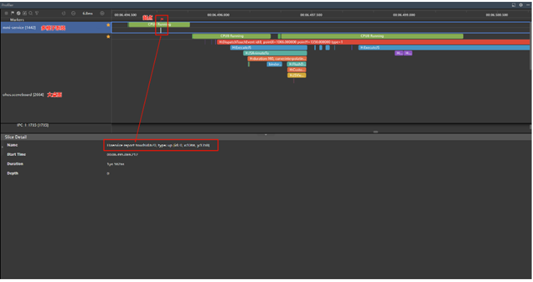
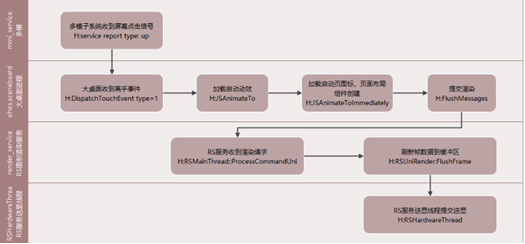
起点Trace查找顺序:H:DispatchTouchEvent type=1(大桌面ohos.sceneboard) -> CPU Running Trace(多模子系统mmi_service)-> H:service report(多模子系统mmi_service)
- 在大桌面泳道(ohos.sceneboard)搜索H:DispatchTouchEvent并且type=1(0,1,2分别代表按下,抬起,移动)的Trace点,该Trace点代表大桌面收到点击离手事件的Trace;
- 然后找到多模子系统泳道(mmi_service),找到H:DispatchTouchEvent前的一个CPU Running Trace,该Trace下有一个H:service report touchId:{id}, type: up [id: 0, x:{X}, y:{Y}]的Trace点,该Trace点的X,Y坐标和H:DispatchTouchEvent是对应的,且类型也是up,代表的是多模子系统收到点击离手事件的时间,H:service report这个Trace开始位置就是起点。
冷启动响应时延止点确认:
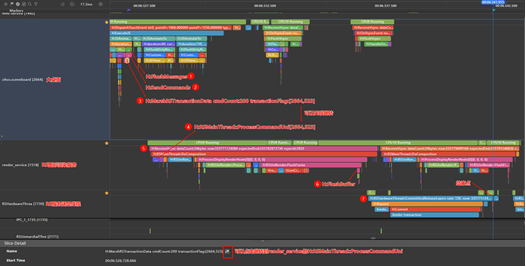
止点Trace查找顺序:
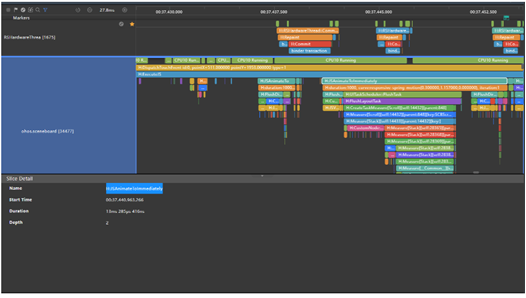
H:DispatchTouchEvent type=1(大桌面ohos.sceneboard) -> H:FlushMessages(大桌面ohos.sceneboard)-> H:SendCommands(大桌面ohos.sceneboard)-> H:MarshRSTransactionData(大桌面ohos.sceneboard) -> H:RSMainThread::ProcessCommandUni(RS服务render_service)-> H:ReceiveVsync(RS服务render_service) -> H:FlushBuffer(RS服务render_service)-> H:RSHardwareThread(RS送显线程RSHardwareThrea)
- 在H:DispatchTouchEvent type=1Trace的末尾找到H:FlushMessages(图中1)-> H:SendCommands(图中2)->H:MarshRSTransactionData(图中3)的系列Trace,这些Trace代表大桌面提交图形渲染请求到render_service(RS图形渲染服务)。
- 选中H:MarshRSTransactionData(图中3)后可以在详情界面点击箭头跳转到render_service泳道对应的Trace H:RSMainThread::ProcessCommandUni(图中4),这个代表render_service收到大桌面渲染请求的点。(H:MarshRSTransactionData后面会有个参数transactionFlag:[2664,523],括号中两个数字分别代表提交请求的进程号和提交的序号,在H:RSMainThread::ProcessCommandUni也会有一个[2664,523]与其对应,两个Trace是通过这个进程号和序号关联起来的。)
- 然后继续找H:RSMainThread::ProcessCommandUni(图中4)所在的H:ReceiveVsync(图中5)的Trace,接着找该Trace下的H:FlushBuffer(图中6),这里代表render_service渲染完成并刷新数据到缓冲区。
- 接着找到RS送显线程泳道RSHardwareThrea,找到根据时间顺序找到H:FlushBuffer后面第一个H:RSHardwareThread::CommitAndReleaseLayers,这里提交后就上屏显示了,这个Trace结束就是终点。(大桌面泳道的H:ReceiveVsync和RSHardwareThrea泳道的H:RSHardwareThread::CommitAndReleaseLayers的now字段也是对应的,也可以通过这个字段值直接找到H:ReceiveVsync对应的H:RSHardwareThread::CommitAndReleaseLayers)。
3.2.2 找问题点
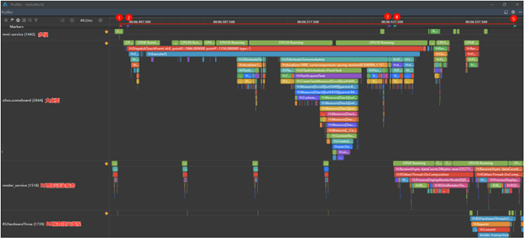
| 序号 | 所属泳道 | Trace点 | 描述 |
| 1 | mmi_service | H:service report(开始) | 多模子系统收到硬件传递过来的点击离手信号 |
| 2 | ohos.sceneboard | H:DispatchTouchEvent(开始) | 大桌面收到点击离手事件 |
| 3 | ohos.sceneboard | H:FlushMessages(结束) | 大桌面提交图形渲染请求完成 |
| 4 | render_service | H:ReceiveVsync(开始) | RS图形渲染服务收到同步信息 |
| 5 | RSHardwareThrea | H:RSHardwareThread::CommitAndReleaseLayers(结束) | RS送显线程提交送显完成 |
| 阶段 | 起点 | 终点 | 耗时基线(参考) |
| 冷启动响应时延 | 上图1 | 上图5 | 60ms |
| 多模子系统时延 | 上图1 | 上图2 | 8ms |
| 大桌面时延 | 上图2 | 上图3 | 25ms |
| 图形子系统时延 | 上图4 | 上图5 | 20ms |
冷启动响应时延类问题找问题点方式如下:
- 通过Trace确认完冷启动响应时延起止点后,就可以圈出冷启动响应时延的耗时区间(图中1->5),如果耗时未超过60ms,则说明达标,不需要继续分析。如果超过60ms,则需要进一步分析是哪里耗时。
- 通过H:DispatchTouchEvent,H:FlushMessages,H:ReceiveVsync这几个关键Trace点可以进一步将冷启动响应时延划分为多模子系统时延,大桌面时延,图形子系统时延三个部分,然后看每个部分耗时是否超过耗时基线,如果超过则找相应的子系统团队确认处理。
经验总结: 就目前来看绝大部分时延超标问题都发生在大桌面时延部分,多模子系统时延和图形子系统时延很少出现,这点从上图中的Trace划分也可以看出来,大桌面时延部分的Trace区间是最长的,因此确认冷却启动响应时延超标后,通常可以直接找大桌面进一步分析超标根因。
备注: 冷启动响应时延预预期85ms,其中包含了硬件显示耗时25ms~30ms(硬件耗时包含点击信号从硬件传输到多模子系统及RS提交渲染数据后数据显示到屏幕上这一段时间),这里按25ms算,减去硬件耗时剩下的才是软件耗时60ms。
3.2.3 根因分析方法
确认耗时Trace点后,圈中该Trace范围,在下方详情中可以看到方法调用栈及耗时,层层展开就可以定位到耗时的函数,之后可以和相关领域确认函数功能及耗时是否正常。
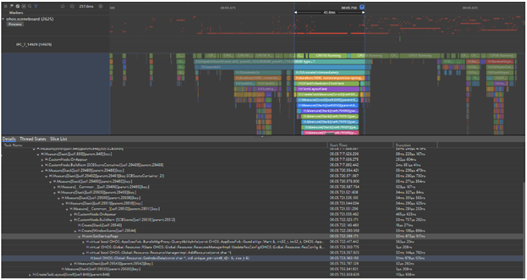
由于冷启动响应时延类问题不涉及应用进程(冷启动响应时延期间,应用进程还未开始启动,这段时间主要做的事情是大桌面拉起应用图标),因此这类问题只需要根据3.2.2章节内容定位到问题点确认系统侧责任领域即可,更进一步的根因分析通常由系统侧进行。
如果想了解更详细的冷启动时延范围内的Trace流程解读,见【附录2:冷启动响应时延Trace点解读】
4. 常见根因归档
4.1 因横竖屏转换启动动效导致冷启动响应时延不满足预期
4.1.1 问题根因分析
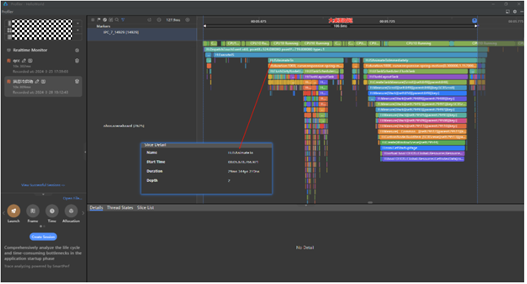
圈出大桌面时延区间,发现耗时106.6ms,远超性能基线25ms,进一步查看Trace信息发现,H:JSAnimateTo耗时29.3ms,占据了整个耗时区间的三分之一,猜测应该是问题点,再对比正常应用的H:JSAnimateTo,大约在2ms左右,所以基本可以确认H:JSAnimateTo存在问题。联系大桌面分析后得出结论是因为应用添加了横竖屏切换动效导致H:JSAnimateTo变长(通过视频也可以确认存在应用启动存在横竖屏切换)。
正常应用启动H:JSAnimateTo耗时2ms
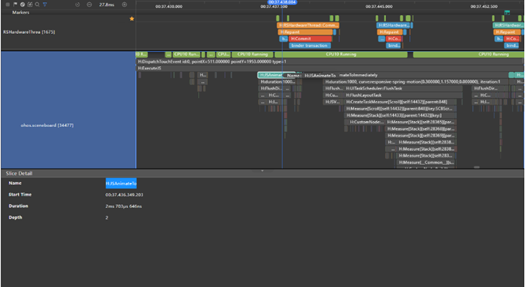
4.1.2 优化方案
竖屏应用启动时不需要横竖屏转换动效,建议应用侧删除横横竖屏转换动效。
4.2 因启动页图标分辨率过大导致冷启动响应时延不满足预期
4.2.1 问题根因分析
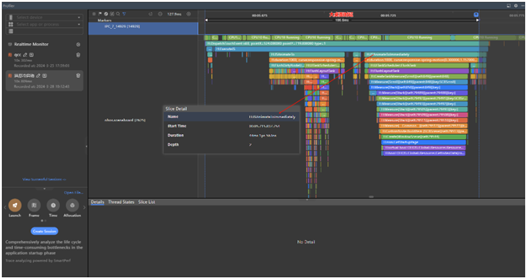
圈出大桌面时延区间,发现耗时106.6ms,远超性能基线25ms,进一步查看Trace信息发现,H:JSAnimateToImmediately耗时44.1ms,占据了整个耗时区间近一半的时间,猜测应该是问题点,再对比正常应用的H:JSAnimateToImmediately,大约在13ms左右,所以基本可以确认H:JSAnimateToImmediately存在问题,联系大桌面分析后得出结论是因为应用启动页图标过大(超过256256)导致H:JSAnimateToImmediately变长。通过Trace也可以看到H:JSAnimateToImmediately下面有个Trace H:ssm:GetStartupPage耗时32.8ms,这个就是加载启动页图标的Trace。
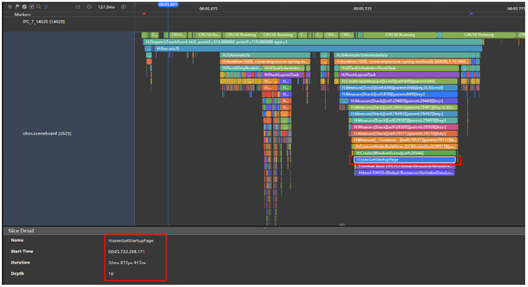
正常H:JSAnimateToImmediately耗时13ms
4.2.2 优化方案
建议使用不超过256256分辨率的图片走位启动页面图标,以减少图片解码带来的时延。
参考“指南-应用冷启动优化”。
附录1:冷启动Trace抓取方法
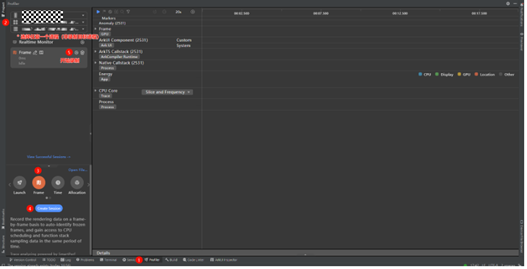
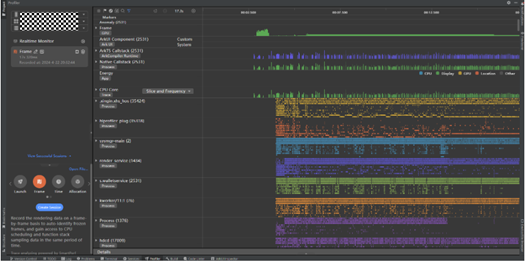
Step1: 打开DevEco Studio的Profiler(下图1) -> 选择设备进程(下图2)-> Frame模式(下图3)-> Create Session(下图4)-> 启动录制(下图5)。
注意:第二步选择进程时不要选择要录制的进程,因为要录制的进程需要处于未启动状态,这里是通过录制其他进程间接录制目标进程的启动Trace信息。
Step2: 启动录制后,在设备上点击应用图标启动要录制的目标应用,等到应用首页加载后,点击停止结束录制。
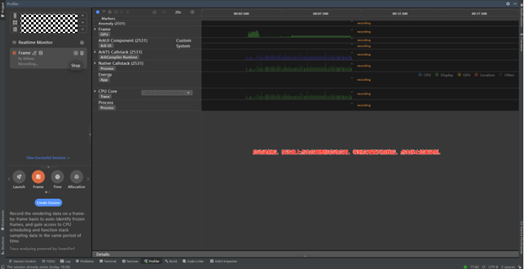
Step3: 录制完成后会工具会分析展示Trace数据。
附录2:冷启动响应时延Trace点解读
冷启动响应时延的定义是从离手帧到应用图标发生变化的首帧耗时,这其中还包含了硬件耗时25ms-30ms,除去这部分耗时外,剩下的就是软件耗时,软件耗时的大概流程区间如下图:
抽象流程如下:
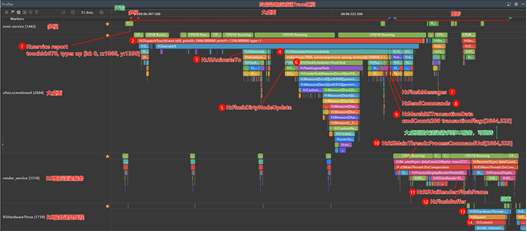
冷启动响应时延的Trace区间为多模子系统H:service report type=up Trace的开始到RS送显线程H:RSHardwareThread Trace的结束。
详细流程如下:
- 多模子系统mmi_service收到屏幕的点击离手信号Trace点H:service report type=up(type参数类型有down,up,move分别代表按下,抬起,移动),这里是冷启动响应时延的Trace起点。
- 桌面进程收到多模子系统传递过来的点击事件,Trace点为H:DispatchTouchEvent type=1(type值0,1,2分别代表按下,抬起,移动)。
- H:DispatchTouchEvent type=1的Trace点下包含H:JSAnimateTo和H:JSAnimateToImmediately两个关键Trace点。这两个Trace也是常见的出问题比较多的Trace点。
- H:JSAnimateTo表示显示动画,包含启动动效加载处理(常见问题是应用启动增加旋转动画导致时间变长)
- H:JSAnimateToImmediately包含启动图标的加载,页面组件创建布局刷新(这里常见问题是应用启动图标像素过大导致时间变长)
H:JSAnimateToImmediately这个Trace点的最后还包含H:FlushMessages->H:SendCommands->H:MarshRSTransactionData的Trace点,这里是大桌面提交渲染请求给RS渲染服务的流程。H:MarshRSTransactionData Trace点中包含transactionFlag:[2664,523]属性,括号中两个值分别表示RS服务的进程id和提交序号,从H:MarshRSTransactionData可以直接点击箭头跳转到RS服务进程中的H:RSMainThread::ProcessCommandUni[2664,523] Trace点。也可以通过搜索[2664,523]查找(这里只会找到两个关联Trace,一个是大桌面进程中H:MarshRSTransactionData,一个是RS服务进程中的H:RSMainThread::ProcessCommandUni)
4. 到RS服务中的H:RSMainThread::ProcessCommandUni Trace点表示RS服务收到了大桌面提交的渲染请求,会开始进行图形渲染之后会提交渲染好的图形数据到缓冲区,关键Trace包含H:RSUniRender:FlushFrame->H:FlushBuffer
5. 执行H:FlushBuffer Trace后就会由RS服务送显线程RSHardwareThread执行送显提交,在RSHardwareThrea泳道找到H:FlushBuffer后的第一个Trace H:RSHardwareThread,这里H:Commit后就将渲染好的图像送显上屏了。
| 序号 | 所属泳道 | 关键Trace点 | Trace点说明 |
| 1 | mmi_service | H:service report touchId:[id值], type: up [id: 0, x:[x坐标] , y:[y坐标]] | 手势事件,id代表touch事件id,pointX,pointY表示x,y坐标;type标识手势类型,值有down,up,move分别代表按下,抬起,移动 |
| 2 | ohos.sceneboard | H:DispatchTouchEvent id:[id值], pointX=[x坐标] pointY=[y坐标] type=1 | 手势事件,id代表事件id,同一个操作可能会有多个事件,但是id是相同的;pointX,pointY表示x,y坐标;type标识手势类型,值有0,1,2分别代表按下,抬起,移动 |
| 3 | ohos.sceneboard | H:JSAnimateTo | 表示显示动画,包含启动动效的加载处理 |
| 4 | ohos.sceneboard | H:JSAnimateToImmediately | 启动图标加载,组件创建页面布局刷新 |
| 5 | ohos.sceneboard | H:FlushDirtyNodeUpdate | 用来标识由于变量更新,触发了某一个组件的标脏,需要对它进行刷新 |
| 6 | ohos.sceneboard | H:UITaskScheduler::FlushTask | 组件创建布局和测量,这一块可以确认是什么组件在创建或者复用 |
| 7 & 8 & 9 | ohos.sceneboard | H:FlushMessages & H:SendCommands & H:MarshRSTransactionData cmdCount:[num] transactionFlag:[发送进程id,序列号] | 发送渲染请求到Render_Service图形渲染服务 |
| 10 | render_service | H:RSMainThread::ProcessCommandUni:[发送进程id,序列号] | Render_Service图形渲染服务收到渲染消息,可以和发送进程的Trace对应起来 |
| 11 & 12 | render_service | H:RSUniRender:FlushFrame & H:FlushBuffer | 刷新图形数据到缓冲区 |
| 13 & 14 | RSHardwareThrea | H:RSHardwareThread & H:Commit | 提交渲染的帧数据 |
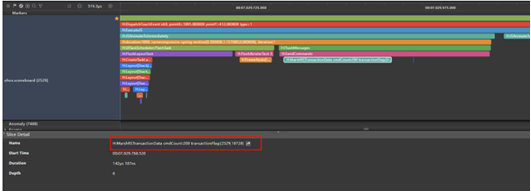
下面针对页面布局刷新Trace点做一些补充描述:
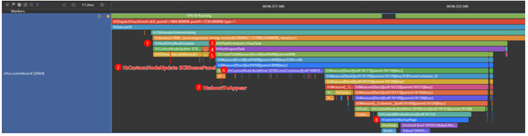
由于页面布局刷新属于通用Trace信息,描述表格不添加泳道信息:
| 序号 | 关键Trace点 | Trace点说明 |
| 1 | H:FlushDirtyUpdate | 用来标识由于变量更新,触发了某一个组件的标脏,需要对它进行刷新。例如上图中SCBScenePanel被标脏了 |
| 2 | H:CustomNodeUpdate [组件] | 表示什么组件发生了变化 |
| 3 & 4 & 5 | H:UITaskScheduler::FlushTask & H:FlushLayoutTask & H:CreateTaskMeasure | 组件创建刷新,页面布局测量 |
| 6 | H:CustomNode:BuildItem [组件] | 表示新创建了什么组件,如上图新创建了SCBSceneContainer组件,该Trace的下发还可以看到创建组件的生命周期 |
| 7 | H:aboutToAppear | 标识对应组件的初始化的生命周期 |
| 8 | H:ssm:GetStartupPage | 加载启动页图标的Trace |






作为IT专家,对于HarmonyOS 鸿蒙Next冷启动响应时延问题,以下是我的分析思路及案例概述:
分析思路:
- 确认场景:冷启动指的是应用后台无进程时,系统重新创建新进程分配给该应用。冷启动响应时延即从点击应用图标离手到桌面应用图标开始变化的时间。
- 性能指标:冷启动响应时延推荐时间为85ms,其中软件耗时60ms(硬件显示耗时25~30ms)。
- 问题定位:
- 确认时延起止点:起点为多模子系统收到点击离手事件,止点为应用图标开始变化的首帧时间。
- 划分时延区间:通过Trace信息,将时延划分为多模子系统时延、大桌面时延、图形子系统时延。
- 分析每个部分耗时,若超过耗时基线,则找相应子系统团队确认处理。
案例概述:
某应用在HarmonyOS 鸿蒙Next系统上冷启动响应时延超标。通过Trace信息分析,发现大桌面时延部分最长,超过60ms。进一步分析发现,大桌面在处理应用启动请求时,存在资源加载耗时过长的问题。经过优化资源加载逻辑,冷启动响应时延得到显著降低,达到推荐标准。
总结:
冷启动响应时延问题通常与大桌面处理逻辑相关,优化资源加载和渲染效率是关键。如果问题依旧没法解决请联系官网客服,官网地址是:https://www.itying.com/category-93-b0.html。