





HarmonyOS 鸿蒙Next Natural Language Kit的问题
HarmonyOS 鸿蒙Next Natural Language Kit的问题
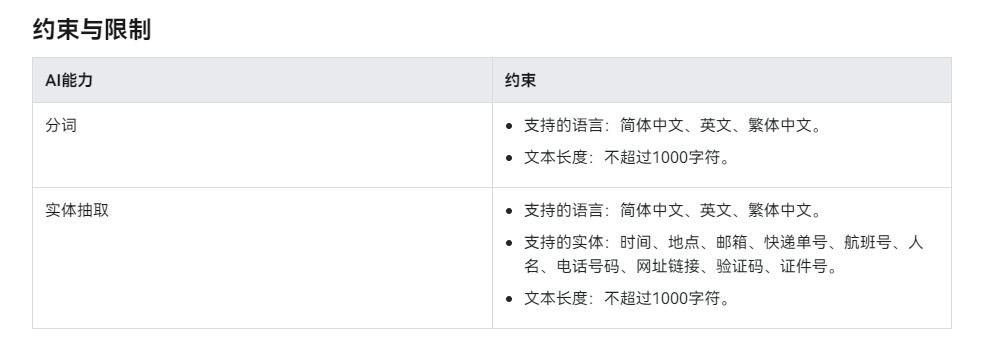
该分词功能是基于什么样的算法或模型?例如,是采用传统的基于规则的分词算法,还是基于深度学习的算法(如BERT、LSTM等)?这对处理复杂文本中的歧义和模糊性有何影响?
更多关于HarmonyOS 鸿蒙Next Natural Language Kit的问题的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


更多关于HarmonyOS 鸿蒙Next Natural Language Kit的问题的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html
针对HarmonyOS 鸿蒙Next Natural Language Kit的问题,以下是一些直接相关的回复:
HarmonyOS 鸿蒙Next Natural Language Kit旨在提供强大的自然语言处理能力,以支持开发者在鸿蒙系统中实现智能文本分析、语言理解及生成等功能。若您遇到的具体问题是关于API的使用、功能实现或性能优化等方面,以下是一些常见问题的简要解答:
-
API调用失败:请确保您使用的API版本与HarmonyOS版本兼容,并检查传入参数是否符合API要求。
-
功能实现问题:参考官方文档中的示例代码,确保您的实现逻辑与官方推荐方式一致。
-
性能瓶颈:分析代码中的性能热点,考虑使用更高效的数据结构和算法,或优化内存管理策略。
-
更新与兼容:关注HarmonyOS官方发布的更新公告,确保您的开发环境及依赖库已更新至最新版本,以避免兼容性问题。
-
错误日志:仔细查看系统日志和应用程序日志,以获取关于错误的详细信息,有助于快速定位问题原因。
如果问题依旧没法解决请联系官网客服,官网地址是:https://www.itying.com/category-93-b0.html 。在联系客服时,请提供详细的错误描述、代码示例及日志信息,以便客服人员能够更快地协助您解决问题。