





HarmonyOS 鸿蒙Next MySQL派生表合并优化的原理和实现
HarmonyOS 鸿蒙Next MySQL派生表合并优化的原理和实现 摘要:本文从一个案例出发梳理了MySQL派生表合并优化的流程实现和优化原理,并对优化前后同一条SQL语句在代码层面的类实例映射关系进行了对比。
本文分享自华为云社区《【华为云MySQL技术专栏】MySQL 派生表合并优化的原理和实现》,作者:GaussDB 数据库。
引言
MySQL是一种流行的开源关系型数据库管理系统,广泛应用于各种Web应用程序和企业系统中。随着数据量的增加和查询复杂度的提高,优化SQL查询性能变得至关重要。派生表(Derived Table)是SQL查询中常用的一种技术,通过在主查询中嵌套子查询来实现更复杂的数据处理。然而,派生表的使用有时会导致系统的性能瓶颈。
为了解决这一问题,MySQL引入了派生表合并优化(Derived Table Merging Optimization)。本文将详细介绍派生表合并优化的原理及在MySQL中的实现。
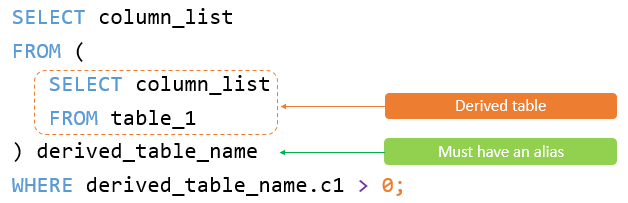
何为派生表?
派生表是一个临时表,它是由子查询的结果集生成并在主查询中使用。简单来讲,就是将FROM子句中出现的检索结果集当成一张表,比如 FROM一个SELECT构造的子查询,这个子查询就是一个派生表;SELECT一个视图,这个视图就是一个派生表;SELECT一个WITH构造的临时表(Common table expression,CTE),这个CTE表就是一个派生表。如下图举例所示:

图1 子查询语句样例
MySQL优化器处理派生表有两种策略:
第一种,将派生表物化为一个临时表; 第二种,将派生表合并到外查询块中。
派生表物化为一个临时表,可能会引发性能问题,如下情况:
- 大数据量子查询:派生表的结果集可能非常大,导致内存消耗和磁盘I/O增加。
- 复杂查询:多层嵌套查询或包含多个派生表的查询,会使优化器难以选择最佳执行计划。
- 不可索引:派生表的结果集是临时的,无法直接使用索引进行优化。
为了解决这些问题,MySQL 引入了派生表合并优化。
派生表合并优化原理
派生表合并优化的核心思想是将派生表的子查询合并到主查询中,从而避免生成临时表。具体来说就是,优化器会尝试将派生表的子查询展开,并直接嵌入到主查询的执行计划中。这样可以减少临时表的使用,降低内存和磁盘I/O的负担,从而提高查询性能。
下文将通过案例对派生表合并优化进行详细说明。
1.案例分析
创建如下两张表:
CREATE TABLE `departments` (
`id` int NOT NULL,
`name` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
CREATE TABLE `employees` (
`id` int NOT NULL,
`name` varchar(50) DEFAULT NULL,
`department_id` int DEFAULT NULL,
`salary` decimal(10,2) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB;
对于下述的查询语句:
SELECT t1.department_id, t2.name, t1.total_salary
FROM
(SELECT department_id, SUM(salary) total_salary
FROM employees GROUP BY department_id) t1
JOIN
(SELECT id, name
FROM departments
WHERE name='Human Resources') t2
ON t1.department_id = t2.id;
关闭optimizer_switch(优化器开关)的derived_merge选项,对应的执行计划如下:
+----+-------------+-------------+------------+------+---------------+-------------+---------+------------------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra
|----+-------------+-------------+------------+------+---------------+-------------+---------+------------------+------+----------+-----------------|
| 1 | PRIMARY | <derived2> | NULL | ALL | NULL | NULL | NULL | NULL | 2 | 100.00 | Using where |
| 1 | PRIMARY | <derived3> | NULL | ref | <auto_key0> | <auto_key0> | 4 | t1.department_id | 2 | 100.00 | NULL |
| 3 | DERIVED | departments | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using where |
| 2 | DERIVED | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using temporary |
+----+-------------+-------------+------------+------+---------------+-------------+---------+------------------+------+----------+-----------------+
4 rows in set, 1 warning (0.01 sec)
select_type列出现两行DERIVED类型, 说明派生表没有合并,派生表会物化为临时表。
执行EXPLAIN ANALYZE进一步分析,可知两个子查询都是物化为临时表后,再执行JOIN。
EXPLAIN: -> Nested loop inner join (actual time=0.304..0.308 rows=1 loops=1)
-> Table scan on t2 (cost=2.73 rows=2) (actual time=0.003..0.003 rows=1 loops=1)
-> Materialize (cost=0.55 rows=1) (actual time=0.163..0.164 rows=1 loops=1)
-> Filter: (departments.`name`='Human Resources') (cost=0.55 rows=1) (actual time=0.103..0.125 rows=1 loops=1)
-> Table scan on departments (cost=0.55 rows=3) (actual time=0.095..0.114 rows=3 loops=1)
-> Index lookup on t1 using <auto_key0> (department_id=t2.id) (actual time=0.004..0.006 rows=1 loops=1)
-> Materialize (actual time=0.137..0.139 rows=1 loops=1)
-> Table scan on <temporary> (actual time=0.001..0.003 rows=3 loops=1)
-> Aggregate using temporary table (actual time=0.102..0.104 rows=3 loops=1)
-> Table scan on employees (cost=0.65 rows=4) (actual time=0.040..0.056 rows=4 loops=1)
1 row in set (0.00 sec)
开启optimizer_switch(优化器开关)的derived_merge选项,对应的执行计划如下:
+----+-------------+-------------+------------+------+---------------+-------------+---------+---------------------+------+----------+-----------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
|----+-------------+-------------+------------+------+---------------+-------------+---------+---------------------+------+----------+-----------------|
| 1 | PRIMARY | departments | NULL | ALL | PRIMARY | NULL | NULL | NULL | 1 | 100.00 | Using where |
| 1 | PRIMARY | <derived2> | NULL | ref | <auto_key0> | <auto_key0> | 5 | test.departments.id | 2 | 100.00 | NULL |
| 2 | DERIVED | employees | NULL | ALL | NULL | NULL | NULL | NULL | 1 | 100.00 | Using temporary |
+----+-------------+-------------+------------+------+---------------+-------------+---------+---------------------+------+----------+-----------------+
3 rows in set (0.00 sec)
从执行计划可以看出,select_type列上只有一行为DERIVED类型,说明发生了派生表合并。
执行EXPLAIN ANALYZE进一步分析,employees表上的子查询仍然会被物化为临时表。departments表上的子查询(派生表)进行了合并优化,departments表直接与临时表t1进行JOIN。
EXPLAIN: -> Nested loop inner join (actual time=0.271..0.295 rows=1 loops=1)
-> Filter: (departments.`name` = 'Human Resources') (cost=0.55 rows=1) (actual time=0.103..0.122 rows=1 loops=1)
-> Table scan on departments (cost=0.55 rows=3) (actual time=0.095..0.112 rows=3 loops=1)
-> Index lookup on t1 using <auto_key0> (department_id=departments.id) (actual time=0.005..0.007 rows=1 loops=1)
-> Materialize (actual time=0.164..0.166 rows=1 loops=1)
-> Table scan on <temporary> (actual time=0.002..0.004 rows=3 loops=1)
-> Aggregate using temporary table (actual time=0.114..0.117 rows=3 loops=1)
-> Table scan on employees (cost=0.65 rows=4) (actual time=0.044..0.065 rows=4 loops=1)
1 row in set (0.00 sec)
对比derived_merge选项开启和关闭的两个执行计划可知,开启派生表合并优化特性后,departments表上的子查询(派生表)不再物化为临时表,而是合并到了父查询,进而简化了执行计划,并提高了执行效率。
另外,也可以发现,并不是所有派生表都可以合并优化,比如,案例中的employees表上的子查询(派生表),因为含有聚合函数,就无法进行合并优化。
2.应用场景限制
如下场景中派生表合并优化是无效的:
1)派生表中含有聚合函数,或者含有DISTINCT、GROUP BY、HAVING这些分组子句。比如,案例中的派生表t1包含了聚合函数和GROUP BY分组就无法合并优化。 2)派生表的SELECT列表中有子查询,也就是标量子查询。比如:
select *
from (
select stuno,
course_no,
(select course_name
from course c
where c.course_no = a.course_no) as course_name,
score
from score a
) b
where b.stuno = 1;
因为派生表b的select 列表中有标量子查询,无法合并,会被物化。 3)分配了用户变量。比如:
select (@i:= @i + 1) as rownum, stuno, course_no, course_name, score
from ((select a.stuno, a.course_no, b.course_name, a.score
from score a
left join course b
on a.course_no = b.course_no) dt, (select (@i:= 0) num) c)
where stuno = 1;
上面这个例子使用用户变量的形式给记录加了行号,不能合并。 4)如果合并会导致外查询块中超过61张基表的连接访问,优化器会选择物化派生表。 5)UNION或UNION ALL。比如:
select id, c1from (
select id, c1
from t1
union
select id, c1 from t2
) dt
where dt.id = 1;
因为派生表dt有union操作,无法合并,会被物化。 6)对于视图而言,创建视图时如果指定了ALGORITHM=TEMPTABLE,它会阻止合并,这个属性的优先级比优化器开关的优先级要高。 7)派生表中含LIMIT子句,因为合并会导致结果集改变。比如:
select * from (
select id,c1 from t1 limit 10
) a where a.id=1;
8)只引用了字面量值。比如:
select * from (
select '1' as c1, 2 as c2
) a;
源码分析
1.背景知识
我们使用的MySQL代码版本号为8.0.22。在介绍派生表代码实现之前,先了解下MySQL描述一条查询的逻辑语法树结构,有4个较为核心的类:
- SELECT_LEX_UINT
- SELECT_LEX
- Item
- TABLE_LIST
- 代码实现
MySQL主要在prepare阶段处理派生表的合并优化,详细的函数调用和处理过程如下:
-> Sql_cmd_dml::prepare
-> Sql_cmd_select::prepare_inner
-> SELECT_LEX::prepare
顶层 query block 的处理,全局入口
-> SELECT_LEX::resolve_placeholder_tables
处理query block中的第一个 derived table
-> TABLE_LIST::resolve_derived
-> 创建Query_result_union对象,在执行derived子查询时,用来向临时表里写入结果数据
-> 调用内层嵌套SELECT_LEX_UNIT::prepare,对derived table对应的子查询做递归处理
-> SELECT_LEX::prepare
-> 判断derived中的子查询是否允许merge到外层,当满足如下任一条件时,“有可能”可以merge到外层:
1. derived table属于最外层查询
2. 属于最外层的子查询之中,且query是一个SELECT查询
-> SELECT_LEX::resolve_placeholder_tables 嵌套处理derived table这个子查询内部的derived table...
... 处理query block中其他的各个组件,包括condition/group by/rollup/distinct/order by...
-> SELECT_LEX::transform_scalar_subqueries_to_join_with_derived
... 一系列对query block(Item中的)处理,略过
-> SELECT_LEX::apply_local_transforms 做最后的一些查询变换(针对最外层query block)
1. 简化join,把嵌套的join表序列尽可能展开,去掉无用的join,outer join转inner join等
2. 对分区表做静态剪枝
-> SELECT_LEX::push_conditions_to_derived_tables(针对最外层query block)
外 query block 中与 derived table 相关的条件会推入到派生表中
-> TABLE_LIST::is_mergeable
-> SELECT_LEX_UNIT::is_mergeable
判断当前 derived table 是否可以merge到外层,要同时满足如下的要求:(只支持最简单的SPJ查询)
1. derived table query expression 没有union
2. derived table query block 没有聚合/窗口函数+没有group by 没有having + 没有distinct + 有table + 没有window + 没有limit
-> SELECT_LEX::merge_derived,确定可以展开到外层后,执行 merge_derived 动作
-> 再做一系列的检查看是否可以merge
1. 外层query block是否允许merge,例如CREATE VIEW/SHOW CREATE这样的命令,不允许做merge
2. 基于启发式,检查derived子查询的投影列是否有子查询,有则不做merge
3. 如果外层有straight_join,而derived子查询中有semi-join/anti-join,则不允许merge
4. 外层表的数量达到MySQL能处理的最大值
-> 通过检查后,开始merge
1. 把内层join列表合并到外层中
2. 把where条件与外层的where条件做AND组合
3. 把投影列合并到外层投影列中
-> 对于不能展开的,采用物化方式执行,setup_materialized_derived
处理query block中的其它 derived table,...
-> resolve_placeholder_tables 处理完成
顶层 query block 的其它处理 ...
案例中的SQL语句经过上面的派生表的合并优化处理后,其对应的映射关系如下:
原理证明
前文描述了MySQL派生表合并优化的具体实现,那么,如何从原理上证明该优化方法的正确性呢?可以尝试根据关系代数定理对其进行论证。
先简化场景,假设有两个表,一个是主查询(主表)R,一个是派生表D。在没有合并优化之前,查询可能是这样的形式:
1)外层查询从派生表中选择数据:σ条件1(D) 2)派生表D是从另一个或多个表导出的结果,通过一定的操作如选择σ条件2、投影π属性或连接⋈等得到。
不考虑具体实现的复杂性,让我们通过一个简单查询的例子来说明外层查询和派生表合并的效果。假设派生表D是从主表R通过选择操作产生的:D = σ条件2®,而外层查询又对D进行选择:σ条件1(D)。
根据关系代数的选择的叠加律(σa(σb®) = σa ∧ b®),可以合并这两个选择操作为一个操作,直接作用在主表R上:σ条件1 ∧ 条件2®。
这样,外层查询和派生表D就被合并成了一个直接对原始表R进行操作的查询,省去了创建和访问派生表D的开销。
对于更复杂的派生表,它们可能通过多个操作,如连接、投影和选择,从一个或多个表导出。针对这样的情况,基于关系代数的性质,比如选择的叠加律和交换律、投影的结合律等,通过相应的关系代数变换,所有这些操作的组合都可以被重写为直接作用于原始表上的一系列操作,也就证明了MySQL的这一优化方式是有效的。
总结
本文从一个案例出发梳理了MySQL派生表合并优化的流程实现和优化原理,并对优化前后同一条SQL语句在代码层面的类实例映射关系进行了对比。MySQL派生表合并的代码实现细节比较多,篇幅有限,不再赘述,希望本文能够作为一个参考,帮助感兴趣的读者进一步研究这部分源码。
更多关于HarmonyOS 鸿蒙Next MySQL派生表合并优化的原理和实现的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html


{kind=link}
更多关于HarmonyOS 鸿蒙Next MySQL派生表合并优化的原理和实现的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html
HarmonyOS 鸿蒙Next MySQL派生表合并优化的原理和实现主要基于查询优化器的改进和底层存储引擎的优化策略。
原理上,派生表(Derived Table)是在查询中由子查询生成的临时表。在鸿蒙Next MySQL中,为了优化派生表的性能,查询优化器会尝试将派生表与外层查询合并,从而减少临时表的创建和数据的多次扫描。这种合并优化能够显著提升查询效率,特别是在处理复杂查询和大数据集时。
实现上,鸿蒙Next MySQL采用了多种技术来实现派生表的合并优化。首先,优化器会分析查询的语法树,识别出派生表及其相关子查询。然后,根据统计信息和成本模型,评估合并派生表与外层查询的可行性。如果合并能够带来性能提升,优化器会生成相应的执行计划,并在执行阶段直接应用合并后的查询。
此外,鸿蒙Next MySQL还针对派生表的存储和访问进行了优化,如使用更高效的内存数据结构来存储派生表数据,以及优化索引和查询路径选择等。
需要注意的是,派生表合并优化是一个复杂的查询优化过程,其实际效果取决于具体的查询场景和数据分布。在某些情况下,合并优化可能并不总是带来性能提升。
如果问题依旧没法解决请联系官网客服,官网地址是:https://www.itying.com/category-93-b0.html