




想问下HarmonyOS鸿蒙Next中小艺开放平台里的知识库爬虫功能为什么是没有输出的?
想问下HarmonyOS鸿蒙Next中小艺开放平台里的知识库爬虫功能为什么是没有输出的? 【问题描述】:使用小艺开放平台里的爬虫功能没有输出,但是目前状态是成功,然后我目前选的是爬虫但是为什么给我显示的是图片呢?
【问题现象】:
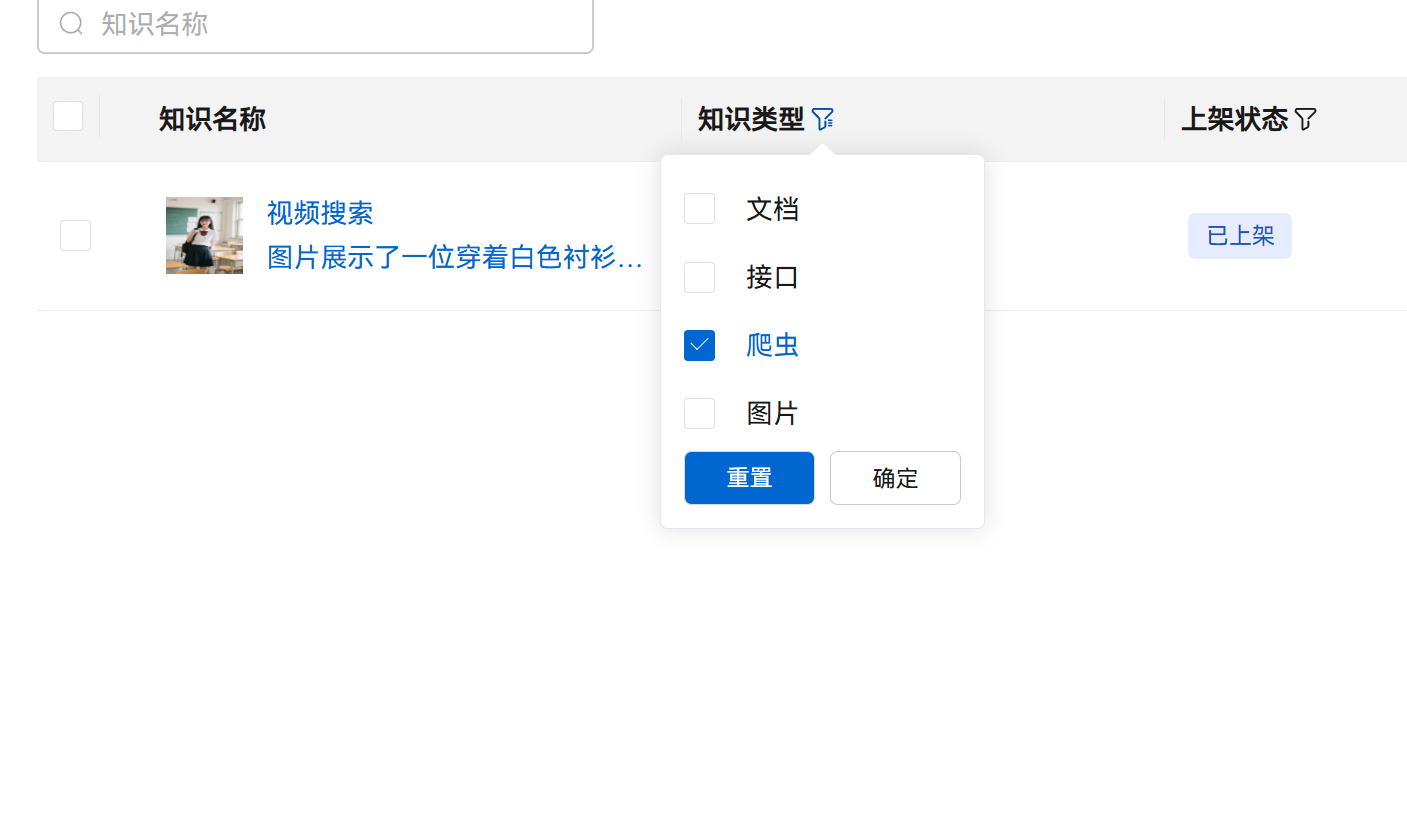
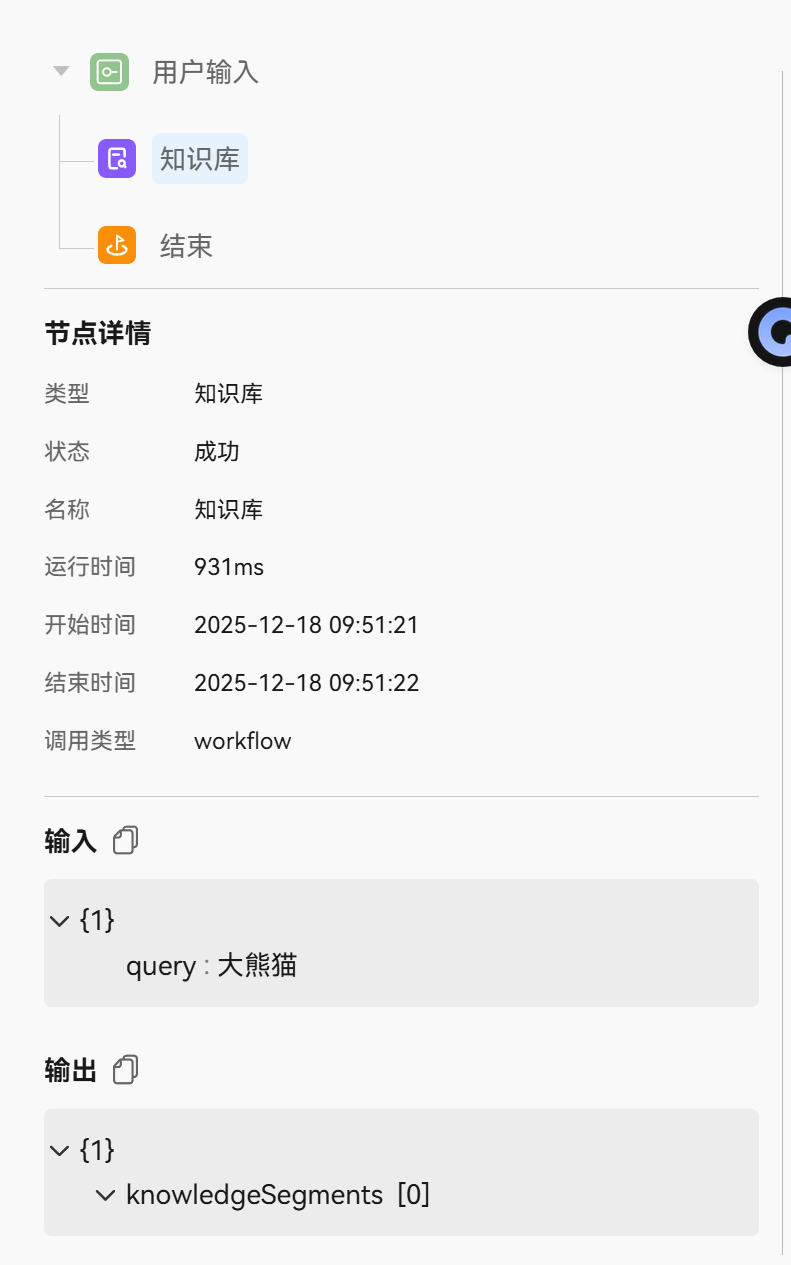
【版本信息】:NA
【复现代码】:NA
【尝试解决方案】:NA
更多关于想问下HarmonyOS鸿蒙Next中小艺开放平台里的知识库爬虫功能为什么是没有输出的?的实战教程也可以访问 https://www.itying.com/category-93-b0.html

鸿蒙Next小艺开放平台知识库爬虫功能无输出,通常涉及数据源配置、权限设置或网络连接问题。请检查数据源是否可访问、API接口权限是否开启、网络环境是否稳定。同时确认爬虫任务配置正确,包括目标URL、解析规则等参数。若问题持续,可查阅平台日志排查具体错误。
更多关于想问下HarmonyOS鸿蒙Next中小艺开放平台里的知识库爬虫功能为什么是没有输出的?的实战系列教程也可以访问 https://www.itying.com/category-93-b0.html

根据您提供的截图和描述,问题可能出在知识库创建时的“数据来源”类型选择上。
在您上传的第一张截图中,您创建的知识库选择的“数据来源”是 “图片”。这意味着该知识库被设计为专门处理和解析图片文件中的文字信息(例如,通过OCR技术识别图片中的文本),而不是执行网页爬虫任务。
关键点分析:
-
功能定位差异:小艺开放平台的“知识库”功能支持多种数据来源,包括:
- 文件:上传文档(如PDF、Word)、图片等。
- 爬虫:自动抓取指定网页的文本内容。
- API:通过接口同步数据。 您当前创建的知识库类型是“图片”库,因此它的处理逻辑是等待您上传图片文件,而非启动一个网页爬虫。
-
状态“成功”的含义:这里的“成功”指的是知识库创建成功,即系统已经为您准备好了一个用于接收和处理图片的知识库容器。它并不表示爬虫任务执行成功或已有内容输出。
-
“爬虫”选项未生效的原因:要使用爬虫功能,您需要在创建知识库的第一步,选择数据来源为 “爬虫”。之后系统会引导您配置目标网址、爬取规则等。您选择了“图片”类型,后续界面和功能自然围绕图片处理展开。
解决方案:
请重新创建一个新的知识库。在创建过程中,务必在数据来源步骤选择 “爬虫” 选项,然后根据指引填写您需要抓取的网页地址等相关配置。这样创建的知识库才会执行网页抓取任务,并将提取到的文本内容输出到知识库中。
总结:当前知识库无输出是因为类型不匹配。请检查并确保新建知识库时选择了正确的“爬虫”数据源类型。