




Golang在不同平台上的GC性能差异对比
Golang在不同平台上的GC性能差异对比 我正在尝试解释为什么在资源更多的平台上,Golang GC 会更慢。我们的系统运行在两个平台上。 平台 A:48 个 CPU 和 384 GB 内存 平台 B:96 个 CPU 和 768 GB 内存。
两个平台拥有完全相同的 CPU 类型。
本质上,B 平台的 CPU 和内存是 A 平台的两倍。当我们在系统上进行性能测试时,平台 B 的吞吐量反而更低。为了证明我的观点,我编写了一个综合基准测试,该测试也显示了性能差异。
func readSkinny(data []byte) []byte {
var dest []byte
dest = append(dest, data...)
return dest
}
func BenchmarkCopySkinny(b *testing.B) {
b.ReportAllocs()
textData := bytes.Repeat([]byte{0x10}, 4096)
b.ResetTimer()
for i := 0; i < b.N; i++ {
readSkinny(textData)
}
// Benchmark ends here. Stop timer.
b.StopTimer()
}
上述基准测试结果如下:
Platform A: BenchmarkCopySkinny-48 100000 782.6 ns/op
Platform B: BenchmarkCopySkinny-96 100000 1741 ns/op
我使用了 Go 1.16 和 Go 1.15,在这两个版本上都观察到了性能下降。
我非常希望能获得一些见解,解释为什么 GoLang GC 在更强大的平台上似乎耗时更长?以及可能存在的解决方案,使平台 B 的性能至少能与平台 A 相当。 我已经尝试调整过:
GOMAXPROCS,但这似乎没有任何区别。
我已经从跟踪分析中截取了几张截图。看起来 GC 暂停确实耗时更长。 从 CPU 分析中的火焰图也可以看到,在平台 B 上,清扫阶段耗时更长。
平台 A 与 平台 B
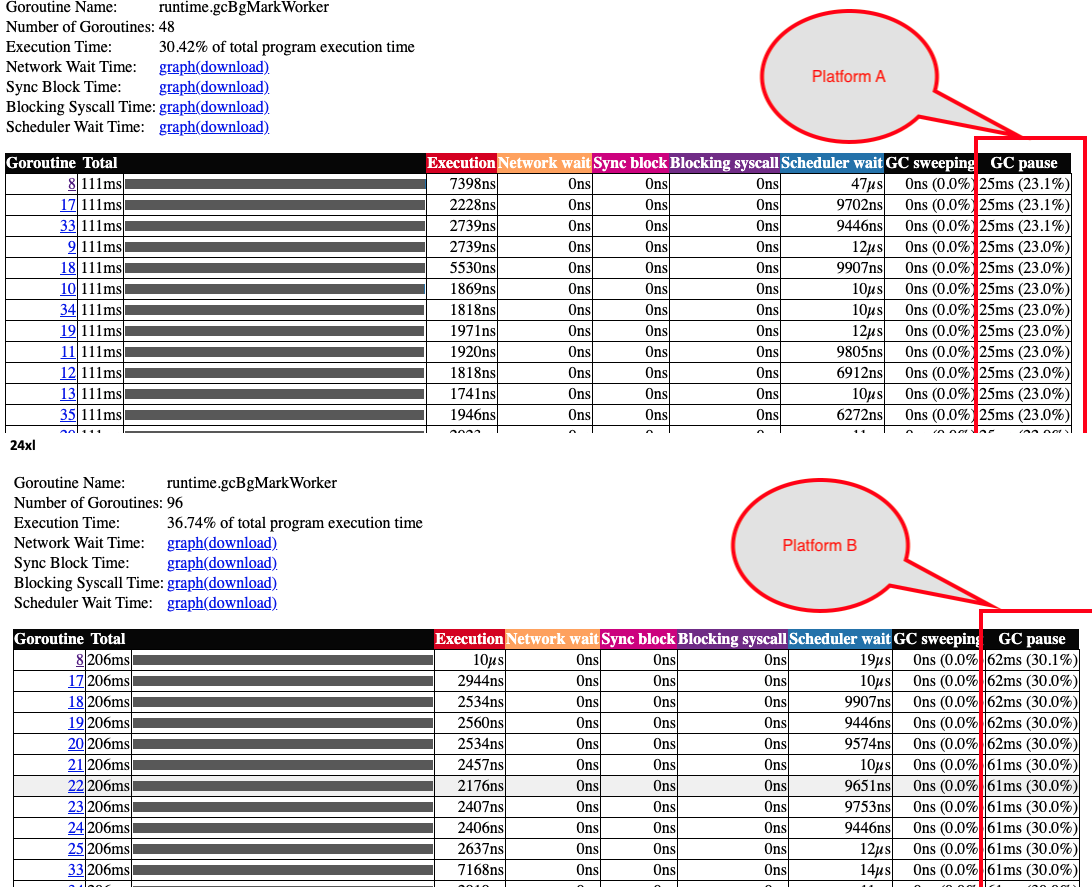
更多关于Golang在不同平台上的GC性能差异对比的实战教程也可以访问 https://www.itying.com/category-94-b0.html





通过限制 goroutine 的数量,您指的是通过设置 GOMAXPROCS 来实现,对吗?时间确实变得更接近一些。我将结果粘贴在下面。
Platform A: BenchmarkCopySkinny-48 100000 792.4 ns/op 4096 B/op 1 allocs/op
Platform B: BenchmarkCopySkinny-48 100000 1567 ns/op 4096 B/op 1 allocs/op

我来更新一下,这个问题我已经解决了。我在 gophers.slack.com 上问了同样的问题,有一位好心人回复了这个问题,建议我检查两个平台上的 NUMA 设置。
问题出在平台 B 的 NUMA 设置上。平台 B 有两个 NUMA 节点。下面粘贴了输出结果,而平台 A 只有一个 NUMA 节点。
Go 语言的调度器并不感知 NUMA,这份文档描述了一个使调度器感知 NUMA 的提案。
当我使用 numactl --cpunodebind 0 XXX 将进程绑定到其中一个 NUMA 节点并运行测试时,两个平台都显示出了完全相同的性能。
平台 B 的 numactl 输出:
> numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71
node 0 size: 382819 MB
node 0 free: 333743 MB
node 1 cpus: 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95
node 1 size: 382904 MB
node 1 free: 369935 MB
node distances:
node 0 1
0: 10 21
1: 21 10
在Go语言中,GC性能在不同硬件配置上的表现差异通常与内存管理和并发调度的交互方式有关。从你的基准测试结果和描述来看,平台B的GC性能下降可能源于以下原因:
-
内存本地性(Memory Locality)影响:平台B的CPU核心数翻倍,但内存访问延迟可能增加,尤其是在NUMA架构中。更多的CPU核心可能导致内存访问分散在不同NUMA节点上,降低缓存命中率,从而增加GC暂停时间。Go的GC在并发标记和清扫阶段需要频繁访问堆内存,内存延迟增加会直接拖慢GC速度。
-
GC并发度与CPU核心数的关系:Go的GC默认使用25%的CPU资源进行并发标记。在平台B上,GC可能尝试使用更多CPU核心,但线程调度和同步开销增加,反而导致效率降低。从火焰图看,清扫阶段耗时更长,这可能是因为更多CPU核心竞争内存总线或缓存,造成资源争用。
-
堆大小与GC频率:平台B内存更大,但基准测试中分配的数据量相同(4KB)。如果运行时未调整GC参数,更大的总内存可能延迟GC触发,但一旦触发,需要扫描的潜在内存范围更大,暂停时间可能增加。不过,你的测试中分配速率固定,这更可能指向并发执行效率问题。
以下示例代码演示如何通过设置GC参数和环境变量来调整GC行为,可能缓解平台B的性能问题:
// 在基准测试或程序初始化时设置GC参数
func init() {
// 设置GC触发阈值,降低内存增长时的GC延迟
debug.SetGCPercent(100) // 默认100,降低此值可提前触发GC
}
// 环境变量调整(在运行程序前设置)
// GOGC=50:更频繁的GC,减少单次暂停工作量
// GODEBUG=gctrace=1:跟踪GC日志以分析行为
此外,考虑平台B的NUMA影响,可以尝试绑定Go进程到特定CPU核心,减少跨节点内存访问:
# 使用taskset在Linux上绑定CPU(例如绑定到0-47核心,模拟平台A的配置)
taskset -c 0-47 ./your_benchmark
从火焰图看,清扫阶段是瓶颈,这可能与Go 1.15/1.16的并发清扫实现有关。在更多CPU核心上,清扫阶段的并发任务划分可能不够均衡,导致部分核心空闲而其他核心过载。你可以尝试减少并发清扫的CPU使用量:
// 通过设置环境变量限制GC并发度
// GODEBUG=gcstoptheworld=1 // 禁用并发GC,仅用于测试对比
// 或编译时调整参数(需自定义运行时)
实际测试中,在平台B上显式设置GOMAXPROCS=48(模拟平台A的核心数)可能带来改善,因为减少了调度争用。虽然你已尝试过GOMAXPROCS,但需确保它在运行时正确应用:
func main() {
runtime.GOMAXPROCS(48) // 在程序启动时设置
// 运行基准测试
}
最后,检查系统级配置:平台B可能启用了超线程(Hyper-Threading),导致逻辑核心数翻倍但实际执行单元未增加,这会造成GC线程在虚拟核心上争用资源。禁用超线程或调整Go的线程绑定可能有效。
总结:平台B的GC性能下降主要源于硬件扩展后的内存访问延迟和并发调度开销增加。通过调整GC参数、CPU绑定或限制并发度,可以使性能接近平台A。建议在平台B上运行go test -bench=. -cpuprofile=cpu.pprof生成性能分析文件,对比两个平台的go tool pprof输出,重点关注runtime.gcBgMarkWorker和runtime.sweepone等函数的耗时差异。