




开源Python微信爬虫项目,寻求志同道合的人一起来改进
一个爬取微信公众号文章的爬虫
github: https://github.com/bowenpay/wechat-spider
微信爬虫的由来
我们是一家帮助中国 5000 万贫困人口与社会公益组织的对接的公司。
我们通过国家和地方政府的“建档立卡”系统,获取到了一手的贫困户数据,目前有 100 万左右,总数为 5000 万,目前每个月都在增长。
为了帮助这部分贫困户对接公益机构,我写了这个微信爬虫,从微信公众号发布的文章中上找出最新的公益项目。
这种找项目的方式的可行性,我们还在试验中。
起初,为了快速上线,本爬虫的代码是基于我的另一个 通用爬虫项目 开发的,还不是很完善,所以希望任何对本项目感兴趣的人联系我,与我一同改进这个项目。
联系方式:在该 issue 下留言告诉我 点击去留言
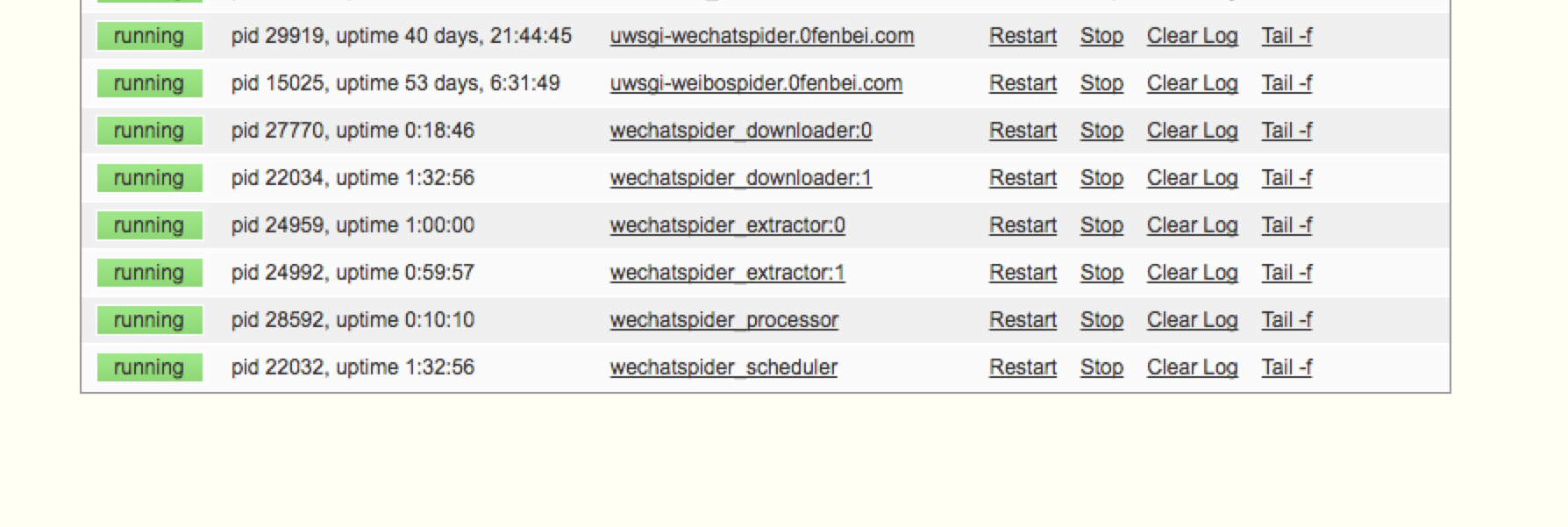
界面预览
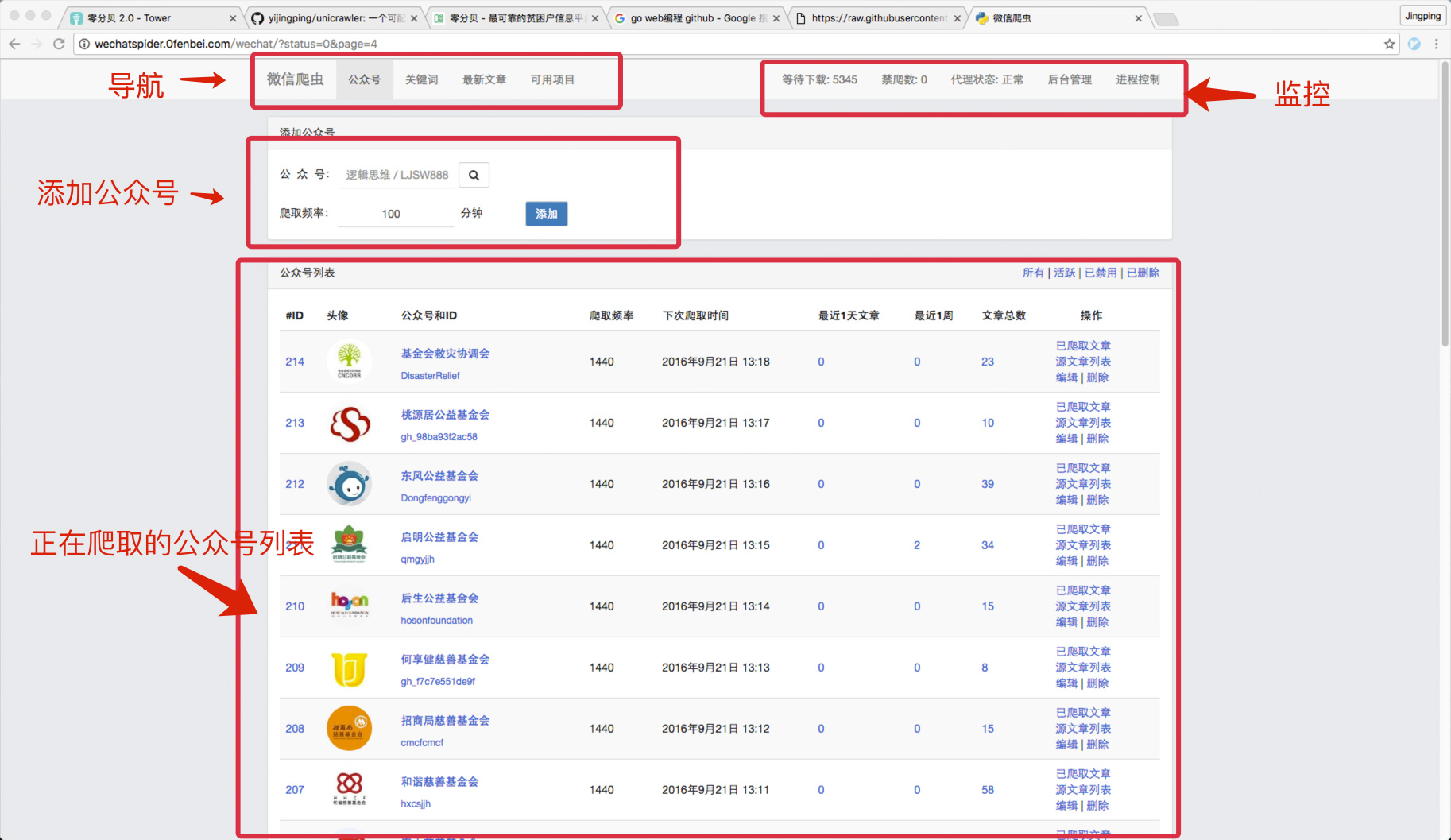
1 ) 要爬取的微信公众号列表
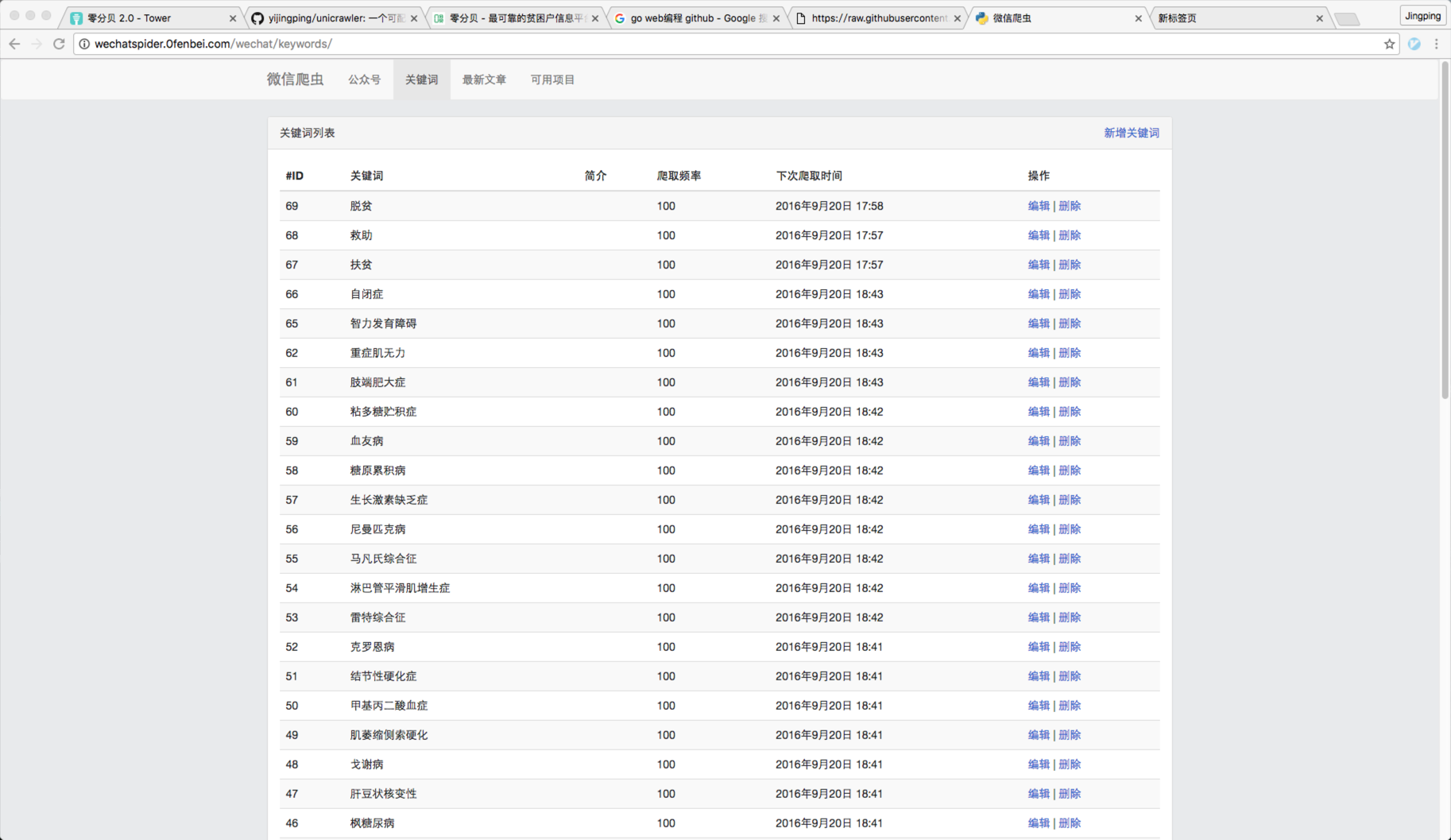
2 ) 要爬取的文章关键字列表
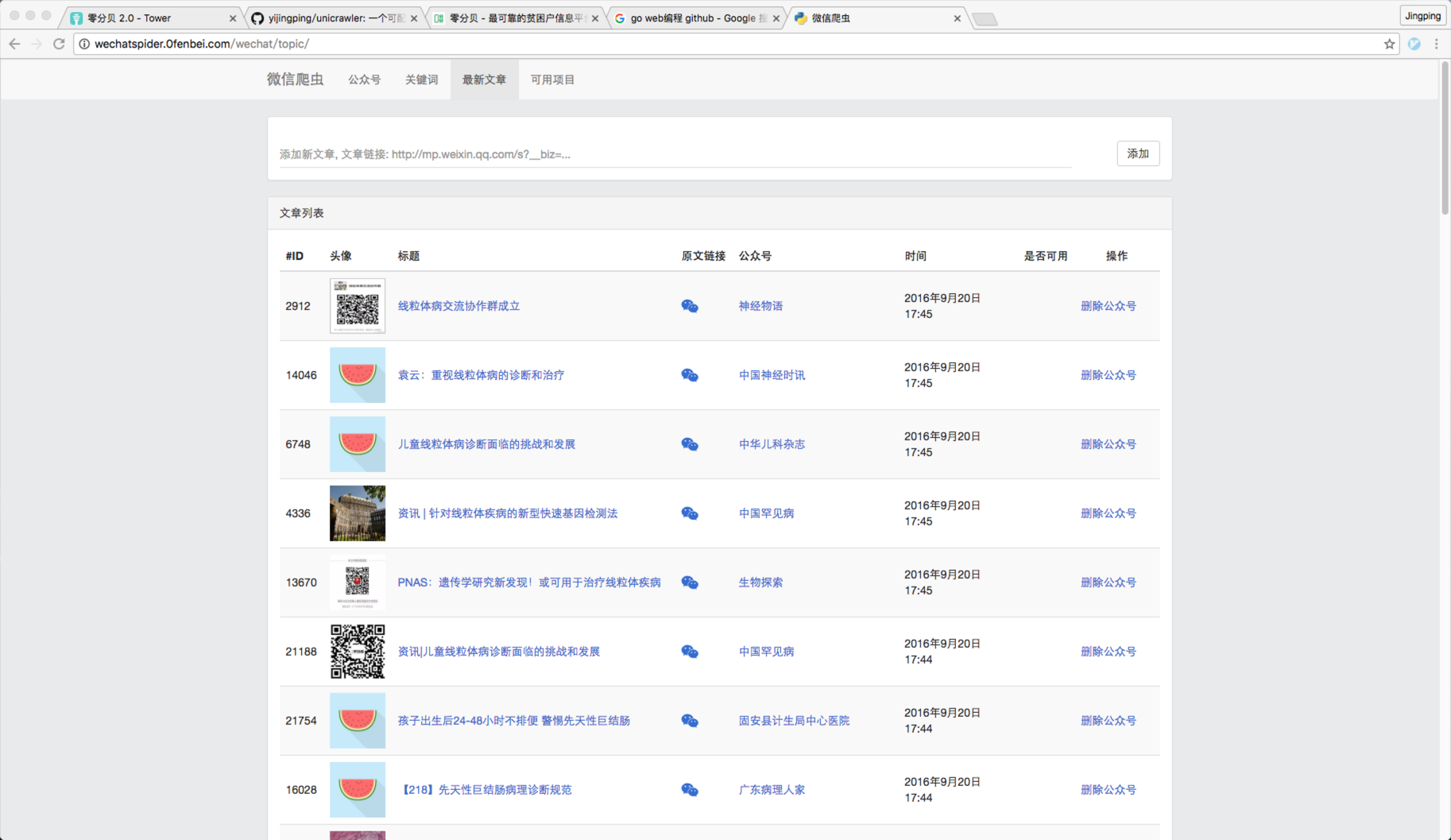
3 ) 已经爬取的微信文章
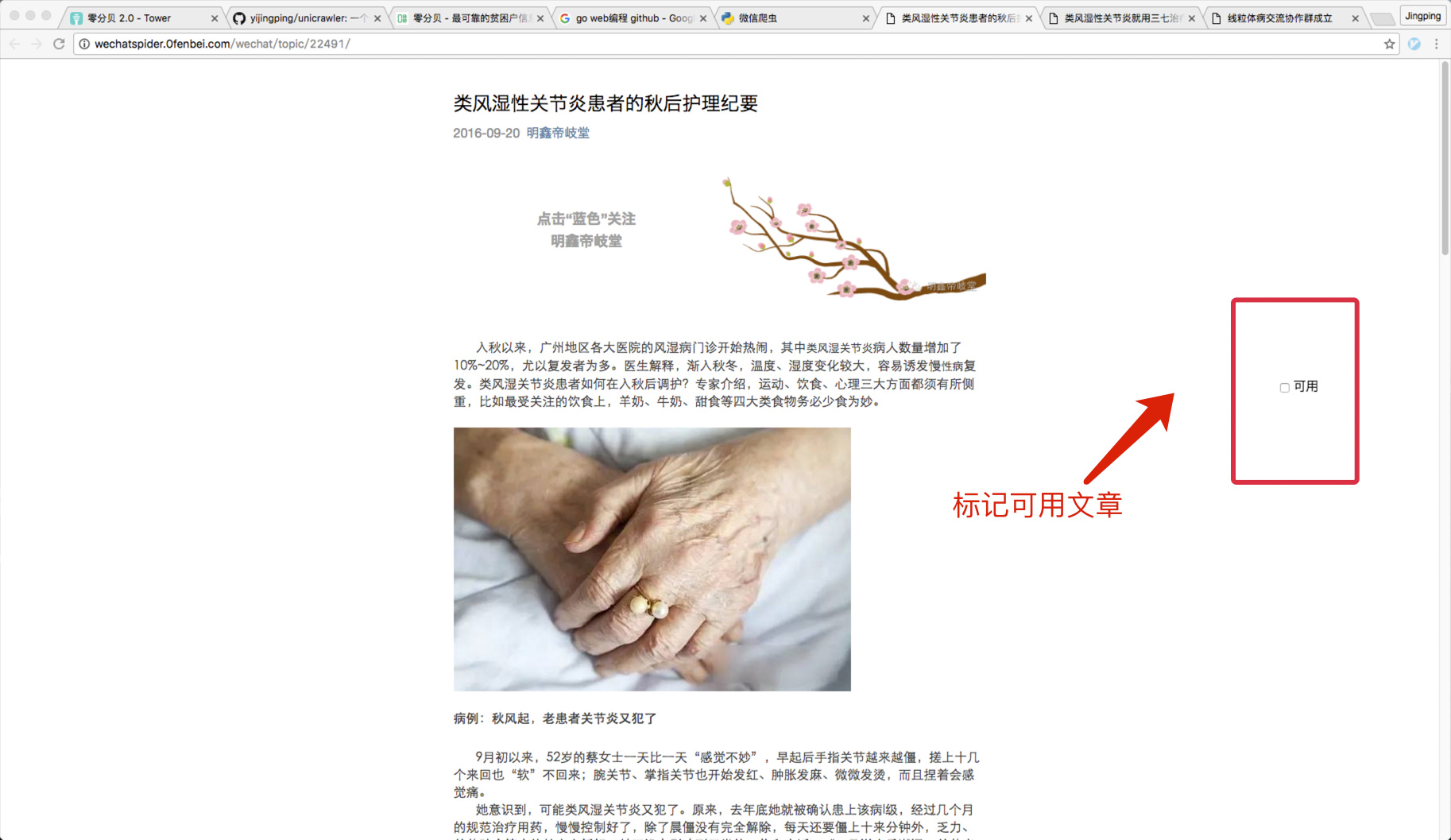
4 ) 查看文章,并标记是否可用
5 ) 控制爬取进程数
使用到的技术和框架
django mysql redis lxml selenium
开源Python微信爬虫项目,寻求志同道合的人一起来改进


这个项目听起来挺有意思的。微信爬虫确实是个有挑战性的领域,尤其是在反爬机制越来越严的情况下。我之前也折腾过类似的,主要难点在于模拟登录、处理动态加载和规避风控。
一个基础框架可以这么搭:
import requests
import time
import json
from bs4 import BeautifulSoup
class WeChatCrawler:
def __init__(self):
self.session = requests.Session()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
def login(self, username, password):
# 这里需要处理二维码登录或账号密码登录
# 实际实现会更复杂,需要处理验证码等
pass
def get_article_list(self, official_account):
url = f'https://mp.weixin.qq.com/profile?src=3×tamp={int(time.time())}'
# 实际需要构造正确的请求参数
response = self.session.get(url, headers=self.headers)
return self.parse_article_list(response.text)
def parse_article_list(self, html):
soup = BeautifulSoup(html, 'html.parser')
articles = []
# 解析文章列表的具体逻辑
return articles
def get_article_content(self, article_url):
response = self.session.get(article_url, headers=self.headers)
return self.parse_article_content(response.text)
# 使用示例
if __name__ == '__main__':
crawler = WeChatCrawler()
# crawler.login('your_username', 'your_password')
articles = crawler.get_article_list('target_account')
不过说实话,纯requests+BeautifulSoup的方案现在很难稳定运行。更靠谱的是用selenium或playwright模拟浏览器,或者直接调用微信开放平台API(如果有权限的话)。
项目可以往这几个方向改进:完善登录模块、增加代理池支持、实现分布式爬取、添加数据存储模块。我比较熟悉异步爬虫和反反爬策略,可以帮忙优化这部分。
有GitHub链接吗?我可以看看现有代码结构。














也有一些人找过我,要爬这种类型的数据、以及做数据分析和广告投放的。 但是公司的主业是做“中国 5000 万贫困人口与社会公益组织的对接”,所以就没有去做你说的“据本身就能兑换价值”的事情。
我一个人也有些忙不经过来。
不过这个爬虫是可以爬任意数据的,如果你感兴趣,可以做一些尝试。 我可以帮你搭建下基础环境。
在 github issue 下留言告诉我 https://github.com/bowenpay/wechat-spider/issues/1 ,这两天我把要做的事情,都列出来。 合作方式也写在上面。

国外的 ngo 还真是这么做的, ngo 可以在捐款中抽取 ngo 运营费用,其中包括运营人员的基本工资。但是所有的开销啥的都必须是透明的,被监督的。
虽然做公益是靠理想,但是光靠理想会饿死的。然而广大圣母婊往往都喜欢脱离现实,不管不顾他人死活,只为了抒发原始情绪,感动自己。
国内也有一些都是公开的,每年年报里面都有详细说明。 基金会中心网 http://www.foundationcenter.org.cn/ 有一个透明指数,可以看出行业内的透明水平。
爬取的时候,如果遇到验证码,则放弃本次爬取任务,并记录重试次数,然后将任务重新放到爬取队列。 下次爬取的时候,会随机选择一个代理 ip 爬取。 如此重复,直到不出现验证码,或者达到重试次数限制。
1 淘宝上搜动态 vps ,有很多卖的。(便宜、方便) 2 自己找机房,拨号上网的那种,(今日头条用的是这种方式,稳定,快,可控)
我用的是这家的: https://item.taobao.com/item.htm?spm=a230r.1.14.1.RT0O2l&id=525941770043&ns=1&abbucket=11#detail
linux 下和 windows 下都需要准备 3 个软件:
1 定时自动重新拨号软件(如拨号精灵)
2 实时获取 ip 并提交到服务端(在项目目录下有, bin/getNewIp.py )
3 代理软件(如 cproxy )