




Python爬虫项目:如何爬取免费可用代理供爬虫工具使用
proxy_list
很多网站对爬虫都会有 IP 访问频率的限制。如果你的爬虫只用一个 IP 来爬取,那就只能设置爬取间隔,来避免被网站屏蔽。但是这样爬虫的效率会大大下降,这个时候就需要使用代理 IP 来爬取数据。一个 IP 被屏蔽了,换一个 IP 继续爬取。此项目就是提供给你免费代理的。
需要免费代理的可以试试,如果对您有帮助,希望给个 Star ⭐,谢谢!😁😘🎁🎉
Github 项目地址 gavin66 / proxy_list
特性
-
爬取、验证、存储、Web API 多进程分工合作。
-
验证代理有效性时使用协程来减少网络 IO 的等待时间。
-
持久化(目前使用 Redis )爬取下来的代理。
-
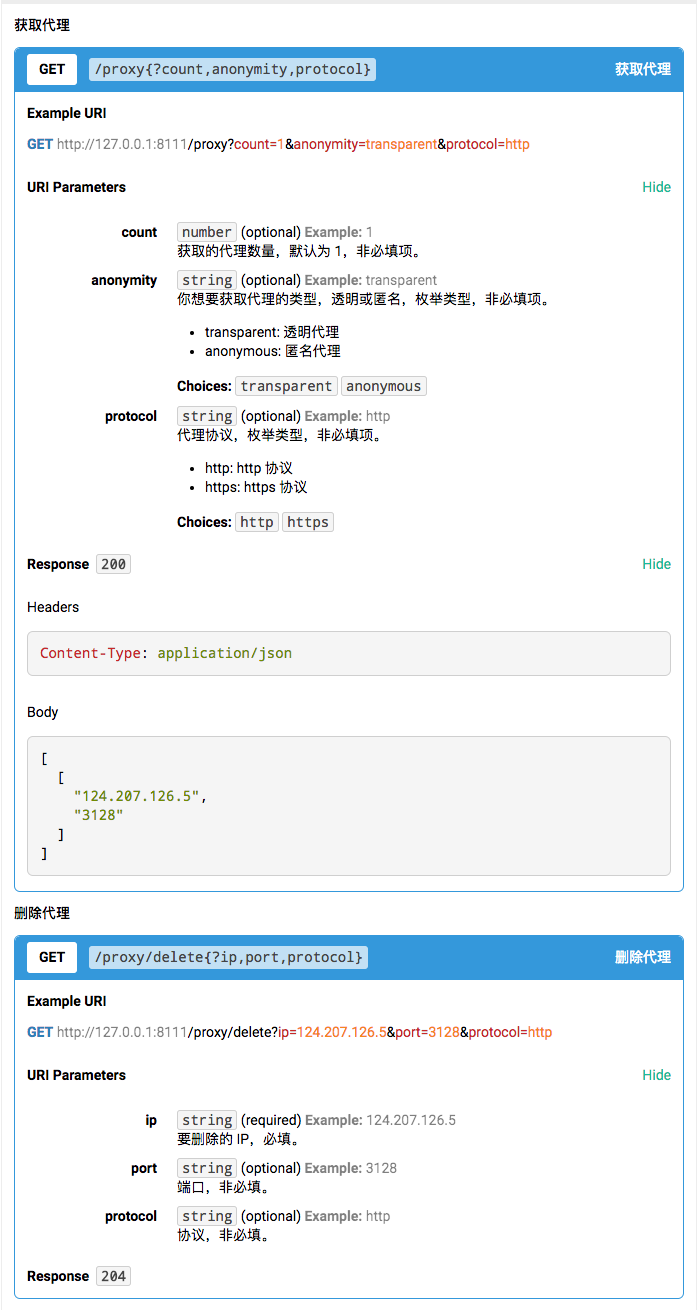
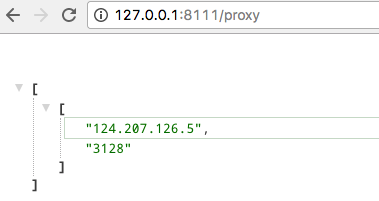
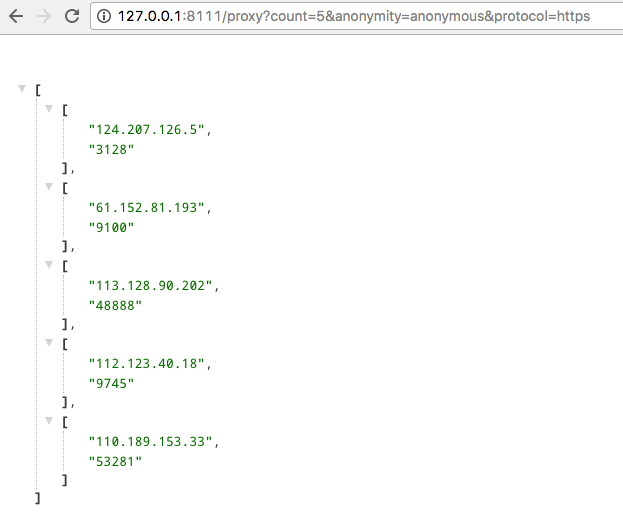
提供 Web API,随时提取与删除代理。
使用
使用 Python3.6 开发的项目,没有对其他版本 Python 测试
克隆源码
git clone [email protected]:gavin66/proxy_list.git
安装依赖
pip install -r requirements.txt
运行脚本
python run.py
Web API
Python爬虫项目:如何爬取免费可用代理供爬虫工具使用
25 回复


import requests
from bsdn import BeautifulSoup
import concurrent.futures
import time
class ProxyScraper:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
self.test_url = "http://httpbin.org/ip"
self.timeout = 5
def get_proxies_from_89ip(self):
"""从89ip获取代理"""
url = "https://www.89ip.cn/index_{}.html"
proxies = []
for page in range(1, 6): # 爬取前5页
try:
response = requests.get(url.format(page), headers=self.headers, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
rows = soup.select('table tbody tr')
for row in rows:
tds = row.find_all('td')
if len(tds) >= 2:
ip = tds[0].text.strip()
port = tds[1].text.strip()
proxies.append(f"http://{ip}:{port}")
except:
continue
return proxies
def get_proxies_from_kuaidaili(self):
"""从快代理获取"""
url = "https://www.kuaidaili.com/free/inha/{}/"
proxies = []
for page in range(1, 4):
try:
response = requests.get(url.format(page), headers=self.headers, timeout=10)
soup = BeautifulSoup(response.text, 'html.parser')
rows = soup.select('#list table tbody tr')
for row in rows:
tds = row.find_all('td')
if len(tds) >= 2:
ip = tds[0].text.strip()
port = tds[1].text.strip()
proxies.append(f"http://{ip}:{port}")
time.sleep(2) # 礼貌延迟
except:
continue
return proxies
def test_proxy(self, proxy):
"""测试单个代理是否可用"""
try:
response = requests.get(
self.test_url,
proxies={"http": proxy, "https": proxy},
timeout=self.timeout,
headers=self.headers
)
if response.status_code == 200:
# 验证返回的IP是否确实是代理IP
returned_ip = response.json().get('origin', '')
proxy_ip = proxy.split('//')[1].split(':')[0]
if proxy_ip in returned_ip:
return proxy
except:
pass
return None
def get_valid_proxies(self, max_workers=20):
"""获取并验证所有代理"""
all_proxies = []
all_proxies.extend(self.get_proxies_from_89ip())
all_proxies.extend(self.get_proxies_from_kuaidaili())
print(f"共获取到 {len(all_proxies)} 个原始代理")
valid_proxies = []
with concurrent.futures.ThreadPoolExecutor(max_workers=max_workers) as executor:
futures = {executor.submit(self.test_proxy, proxy): proxy for proxy in all_proxies}
for future in concurrent.futures.as_completed(futures):
result = future.result()
if result:
valid_proxies.append(result)
print(f"有效代理: {result}")
return valid_proxies
def save_proxies(self, proxies, filename="proxies.txt"):
"""保存代理到文件"""
with open(filename, 'w', encoding='utf-8') as f:
for proxy in proxies:
f.write(proxy + '\n')
print(f"已保存 {len(proxies)} 个有效代理到 {filename}")
# 使用示例
if __name__ == "__main__":
scraper = ProxyScraper()
valid_proxies = scraper.get_valid_proxies()
if valid_proxies:
scraper.save_proxies(valid_proxies)
print(f"\n最终获取到 {len(valid_proxies)} 个有效代理")
else:
print("未获取到有效代理")
这个爬虫做了几件事:
- 从89ip和快代理两个免费代理网站抓取代理IP
- 用多线程并发测试代理的可用性
- 验证代理是否真正生效(检查返回的IP地址)
- 把可用的代理保存到文件
核心思路就是:采集->验证->保存。免费代理质量参差不齐,必须验证后才能用。测试用的httpbin.org是个不错的验证网站,能返回请求的原始IP。
代码里加了请求头、延迟和异常处理,避免被网站屏蔽。多线程验证能加快速度,毕竟代理测试是IO密集型操作。
保存的proxies.txt文件可以直接给其他爬虫用,比如:
import random
with open('proxies.txt', 'r') as f:
proxies = [line.strip() for line in f]
proxy = random.choice(proxies)
# 然后在requests里用这个proxy参数
简单说就是:多源采集,严格验证,别太频繁请求。




你指的是哪一方面?是使用这些代理的效率还是爬取这些代理的效率?如果是爬取的话,每个代理都会访问一遍 <a target="_blank" href="https://httpbin.org/" rel="nofollow noopener">https://httpbin.org/</a> 确定代理可用。也就是使用已持久化下来的,都是保证可用的,使用 Web API 获取的时候都会获取连接速度最快的。







