




Python中pytesseract+tesseract-ocr识别验证码效果不佳,如何优化?
这几个都没法识别
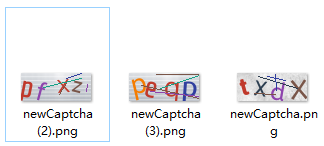
只能纯数据,而且不加干扰的,才能识别

Python中pytesseract+tesseract-ocr识别验证码效果不佳,如何优化?
7 回复


识别验证码效果不佳,通常是因为图片预处理没做好。tesseract本身对干净、清晰的文字图片识别率才高,直接扔给它一张验证码原图,效果肯定差。
核心思路是:先把图片处理成接近黑底白字的清晰二值化图像,再交给tesseract识别。下面这个代码示例演示了常用的预处理流程,你可以根据自己验证码的特点(比如干扰线、噪点、颜色)调整参数:
import pytesseract
from PIL import Image, ImageFilter, ImageEnhance
import cv2
import numpy as np
def preprocess_image(image_path):
# 1. 用PIL打开图片
img = Image.open(image_path)
# 2. 转换为灰度图
img = img.convert('L')
# 3. 增强对比度(很多验证码对比度低)
enhancer = ImageEnhance.Contrast(img)
img = enhancer.enhance(2.0) # 2.0是增强因子,根据实际情况调整
# 4. 二值化(阈值可以调整)
# 方法一:简单阈值
# img = img.point(lambda x: 0 if x < 180 else 255, '1')
# 方法二:用OpenCV自适应阈值(对光照不均的图片更好)
img_np = np.array(img)
img_np = cv2.medianBlur(img_np, 3) # 中值滤波去噪
thresh = cv2.adaptiveThreshold(img_np, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C,
cv2.THRESH_BINARY, 11, 2)
img = Image.fromarray(thresh)
# 5. 去噪(可选)
img = img.filter(ImageFilter.MedianFilter(size=3))
# 6. 放大图片(小字识别差)
img = img.resize((img.width*2, img.height*2), Image.Resampling.LANCZOS)
return img
def recognize_captcha(image_path):
# 预处理图片
processed_img = preprocess_image(image_path)
# 配置tesseract参数
custom_config = r'--oem 3 --psm 8 -c tessedit_char_whitelist=0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
# 参数说明:
# --psm 8: 将图片视为单个单词
# --oem 3: 默认OCR引擎
# -c tessedit_char_whitelist: 设置可能出现的字符(根据你的验证码字符集调整)
# 识别
text = pytesseract.image_to_string(processed_img, config=custom_config)
return text.strip()
# 使用示例
result = recognize_captcha('captcha.png')
print(f"识别结果: {result}")
关键点:
- 预处理比调参更重要:上面代码中的灰度化、对比度增强、二值化、去噪、放大这五步,对大多数简单验证码都有效。
- 字符白名单:如果你的验证码只包含数字或特定字母,一定要在
tessedit_char_whitelist参数里限制字符集,能大幅提升准确率。 - PSM模式:
--psm 8是把整个图片当作一个单词来识别,适合没有空格分隔的验证码。如果验证码字符间有间隔,可以试试--psm 7(单行文本)。
如果验证码有彩色背景或干扰线,可能需要先提取主要颜色或进行颜色过滤。复杂的验证码(比如扭曲严重、重叠字符)可能还需要更专业的图像处理甚至机器学习方法。
总结:重点搞好图片预处理。



说实话 我刚研究了这玩意一段时间,优化主要就在两方面,你先对图片进行一下预处理,作用很大,比如说二值化一下,这样干扰因素会少一些,然后你再对这种图片进行训练生成字体文件,放到 tessdata 中,tesseract 训练方法网上很多,你可以找一下,反正我是失败了,我在生成四个文件的时候会出错 也没招到原因,你可以试一试
