




Python中使用tesseract进行数字识别的问题
用的 python
这张图片识别成了 BS...
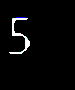
识别信息:
Tesseract Open Source OCR Engine v4.0.0.20181030 with Leptonica Warning: Invalid resolution 0 dpi. Using 70 instead. BS
版本:
$ D:\Tesseract-OCR\tesseract.exe -v tesseract v4.0.0.20181030 leptonica-1.76.0 libgif 5.1.4 : libjpeg 8d (libjpeg-turbo 1.5.3) : libpng 1.6.34 : libtiff 4.0.9 : zlib 1.2.11 : libwebp 0.6.1 : libopenjp2 2.2.0
我已经尝试了, 把转换为 tiff 格式, 用 OpenCV 的 threshold 和 erosion 处理都不行, 我想 tesseract 的识别能力不至于这么差吧。。。 这个图片我觉得已经很简单了。
有那个老哥有相关的经验, 或者有什么其他的方法, 在线的 ocr 速度不行我这个最好还是本地的 OCR 比较好。 主要识别数字, 今天刚下载的 tesseract...
Python中使用tesseract进行数字识别的问题
7 回复





